Wetenschap
Chemisch gegevensbeheer:een open weg voorwaarts
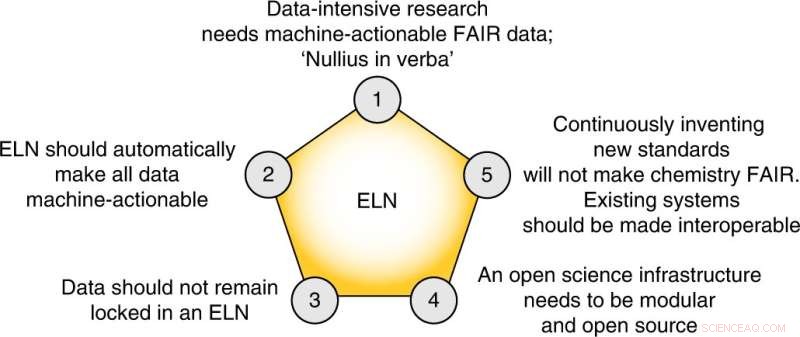
De vijf kernstellingen van dit perspectief. Krediet:Natuurchemie (2022). DOI:10.1038/s41557-022-00910-7
Een van de meest uitdagende aspecten van de moderne scheikunde is het beheren van gegevens. Bij het synthetiseren van een nieuwe verbinding zullen wetenschappers bijvoorbeeld meerdere proefondervindelijke pogingen ondernemen om de juiste omstandigheden voor de reactie te vinden, waarbij ze enorme hoeveelheden onbewerkte gegevens genereren. Dergelijke gegevens zijn van ongelooflijke waarde, omdat algoritmen voor machine learning, net als mensen, veel kunnen leren van mislukte en gedeeltelijk succesvolle experimenten.
De huidige praktijk is echter om alleen de meest succesvolle experimenten te publiceren, aangezien geen mens het enorme aantal mislukte experimenten zinvol kan verwerken. Maar AI heeft dit veranderd; het is precies wat deze machine learning-methoden kunnen doen, op voorwaarde dat de gegevens worden opgeslagen in een machinaal bruikbare indeling die iedereen kan gebruiken.
"Lange tijd moesten we informatie comprimeren vanwege het beperkte aantal pagina's in gedrukte tijdschriftartikelen", zegt professor Berend Smit, die het Laboratory of Molecular Simulation bij EPFL Valais Wallis leidt. "Tegenwoordig hebben veel tijdschriften zelfs geen gedrukte edities meer; scheikundigen worstelen echter nog steeds met reproduceerbaarheidsproblemen omdat cruciale details in tijdschriftartikelen ontbreken. Onderzoekers 'verspillen' tijd en middelen door 'mislukte' experimenten van auteurs te repliceren en hebben gepubliceerde resultaten, aangezien onbewerkte gegevens zelden worden gepubliceerd."
Maar volume is hier niet het enige probleem; gegevensdiversiteit is een andere:onderzoeksgroepen gebruiken verschillende tools zoals Electronic Lab Notebook-software, die gegevens opslaan in propriëtaire formaten die soms niet compatibel zijn met elkaar. Dit gebrek aan standaardisatie maakt het voor groepen bijna onmogelijk om gegevens te delen.
Nu heeft Smit, samen met Luc Patiny en Kevin Jablonka van EPFL, een perspectief gepubliceerd in Nature Chemistry een open platform presenteren voor de volledige chemieworkflow:van het begin van een project tot de publicatie ervan.
De wetenschappers zien het platform als een "naadloze" integratie van drie cruciale stappen:gegevensverzameling, gegevensverwerking en gegevenspublicatie - allemaal met minimale kosten voor onderzoekers. Uitgangspunt is dat data FAIR moet zijn:goed vindbaar, toegankelijk, interoperabel en herbruikbaar. “Op het moment van dataverzameling worden de data automatisch omgezet naar een standaard FAIR-formaat, waardoor het mogelijk wordt om automatisch alle ‘mislukte’ en deels geslaagde experimenten samen met het meest succesvolle experiment te publiceren”, zegt Smit.
Maar de auteurs gaan nog een stap verder en stellen voor dat data ook machine-actionable moeten zijn. "We zien steeds meer datawetenschappelijke studies in de chemie", zegt Jablonka. "Inderdaad, recente resultaten in machine learning proberen een aantal van de problemen aan te pakken waarvan chemici denken dat ze onoplosbaar zijn. Onze groep heeft bijvoorbeeld enorme vooruitgang geboekt bij het voorspellen van optimale reactieomstandigheden met behulp van machine learning-modellen. Maar die modellen zouden veel waardevoller zijn als ze kunnen ook reactiecondities leren die falen, maar verder blijven ze bevooroordeeld omdat alleen de succesvolle condities worden gepubliceerd."
Ten slotte stellen de auteurs vijf concrete stappen voor die het veld moet nemen om tot een FAIR datamanagementplan te komen:
- De chemiegemeenschap moet haar eigen bestaande normen en oplossingen omarmen.
- Journals moeten deponering van herbruikbare onbewerkte gegevens verplicht stellen, waar gemeenschapsnormen bestaan.
- We moeten de publicatie van "mislukte" experimenten omarmen.
- Elektronische Lab-notebooks waarmee niet alle gegevens kunnen worden geëxporteerd naar een open, machinaal bruikbare vorm, moeten worden vermeden.
- Data-intensief onderzoek moet in onze curricula worden opgenomen.
"We denken dat het niet nodig is om nieuwe bestandsformaten of technologieën uit te vinden", zegt Patiny. "In principe is alle technologie er, en we moeten bestaande technologieën omarmen en interoperabel maken."
De auteurs wijzen er ook op dat alleen het opslaan van gegevens in een elektronisch lab-notebook - de huidige trend - niet noodzakelijkerwijs betekent dat mensen en machines de gegevens opnieuw kunnen gebruiken. De gegevens moeten eerder gestructureerd en gepubliceerd zijn in een gestandaardiseerd formaat, en ze moeten ook voldoende context bevatten om gegevensgestuurde acties mogelijk te maken.
"Ons perspectief biedt een visie op wat volgens ons de belangrijkste componenten zijn om de kloof tussen data en machine learning te overbruggen voor kernproblemen in de chemie", zegt Smit. "We bieden ook een open science-oplossing waarin EPFL het voortouw kan nemen." + Verder verkennen
Machine learning kraakt de oxidatietoestanden van kristalstructuren
 Nanopore onthult vormveranderend enzym gekoppeld aan katalyse
Nanopore onthult vormveranderend enzym gekoppeld aan katalyse- Biosensoren verlichten cellulaire signaalprocessen
- Wetenschappers stellen IAP-proces voor voor scheiding van aluminiumlegeringen
- Op de natuur geïnspireerde materialen kunnen worden gebruikt in toepassingen variërend van tunneling tot ruimtevaart
- Duurzame sterk geleidende elektrodematerialen van ultradunne koolstof nanovezel aerogels afgeleid van nanofibrillated
- Intercropping verhoogt de groenteproductie
- De uitstoot van zwaveldioxide in China daalde aanzienlijk, terwijl India het afgelopen decennium groeide
- Waarom je regen kunt ruiken
- Hogere planten verhuizen naar het noordpoolgebied vanwege klimaatverandering
- Moeilijk te zien, moeilijk te ademen:het westen van de VS worstelt met rook
Hoofdlijnen
- De nadelen van gelelektroforese
- Een bouwsteen voor leverfitness op oudere leeftijd
- De patronen van klimaatverandering
- Slachtoffers van dolfijnen in de Zwarte Zee in de Russische oorlog in Oekraïne
- Central Dogma (Gene Expression): Definitie, Stappen, Verordening
- Grootte van witrotschimmels verklaard door de breedte van de betrokken genfamilies
- Fasen van de cardiale actiepotentiaal
- High School Biology Topics
- Hoe haarverf bijdraagt aan het behoud van de Australische zeeleeuwenpopulatie
- Stabiele katalysatoren voor nieuwe energie

- Voeg gewoon nanomaterialen toe voor sterkere, hardere duikvinnen

- Massaspectrometrietechniek helpt bij het identificeren van vervalste manuscripten van Robert Burns

- Klein worden om te bepalen waar nucleair materiaal vandaan komt en hoe het is gemaakt

- Gemeenschappelijke herbicideverbinding kan miljoenen levens redden


 SpaceX brengt een nieuwe weergave uit van hoe het volledig stalen ruimteschip eruit zal zien als het terugkeert naar de aarde
SpaceX brengt een nieuwe weergave uit van hoe het volledig stalen ruimteschip eruit zal zien als het terugkeert naar de aarde- Natuurkundigen maken het mogelijk om je eigen babyuniversum in 3D te printen
- Ruimteduurzaamheid en puinfysica:de rol van terugkeer
- Sociale media hebben opmerkelijk weinig invloed op Amerikaanse overtuigingen:studie
- Toekomstige plotselinge droogte zal toenemen in vochtige gebieden
- Nieuw AI-programma bestrijdt brand met data
- SARS-CoV-2 waakzaam in de gaten houden
- NASA verplaatst lancering van Psyche-missie naar een metalen asteroïde
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
