Wetenschap
Hoe Regressiecoëfficiënt
Een van de meest basale hulpmiddelen voor engineering of wetenschappelijke analyse is lineaire regressie. Deze techniek begint met een gegevensverzameling in twee variabelen. De onafhankelijke variabele wordt gewoonlijk "x" genoemd en de afhankelijke variabele wordt gewoonlijk "y" genoemd. Het doel van de techniek is om de lijn te identificeren, y = mx + b, die de gegevensreeks benadert. Deze trendlijn kan grafisch en numeriek de relaties tussen de afhankelijke en onafhankelijke variabelen weergeven. Uit deze regressieanalyse wordt ook een waarde voor correlatie berekend.
Identificeer en scheid de x- en y-waarden van uw datapunten. Als u een spreadsheet gebruikt, voert u deze in de aangrenzende kolommen in. Er moet hetzelfde aantal x- en y-waarden zijn. Als dit niet het geval is, is de berekening onnauwkeurig of retourneert de spreadsheetfunctie een fout. x = (6, 5, 11, 7, 5, 4, 4) y = (2, 3, 9, 1, 8, 7, 5)
Bereken de gemiddelde waarde voor de x-waarden en de y-waarden door de som van alle waarden te delen door het totale aantal waarden in de set. Deze gemiddelden worden "x_avg" en y_avg. "X_avg = (6 + 5 + 11 + 7 + 5 + 4 + 4) /7 = 6 y_avg = (2 + 3 + 9 + 1 + 8 + 7 + 5) /7 = 5
Maak twee nieuwe gegevenssets door de x_avg-waarde af te trekken van elke x-waarde en de y_avg-waarde van elke y-waarde. X1 = (6 - 6, 5 - 6, 11 - 6, 7 - 6 ...) x1 = (0, -1, 5, 1, -1, -2, -2) y1 = (2 - 5, 3 - 5, 9 - 5, 1 - 5, ... ) y1 = (-3, -2, 4, -4, 3, 2, 0)
Vermenigvuldig elke x1-waarde met elke y1-waarde, in volgorde. x1y1 = (0 * -3, -1 * -2, 5 * 4, ...) x1y1 = (0, 2, 20, -4, -3, -4, 0)
Vier elke x1-waarde. X1 ^ 2 = (0 ^ 2 , 1 ^ 2, -5 ^ 2, ...) x1 ^ 2 = (0, 1, 25, 1, 1, 4, 4)
Bereken de sommen van de x1y1-waarden en x1 ^ 2 waarden. sum_x1y1 = 0 + 2 + 20 - 4 - 3 - 4 + 0 = 11 sum_x1 ^ 2 = 0 + 1+ 25 + 1 + 1 + 4 + 4 = 36
Splits "sum_x1y1" door " sum_x1 ^ 2 "om de regressiecoëfficiënt te krijgen sum_x1y1 /sum_x1 ^ 2 = 11/36 = 0.306
TL; DR (te lang; niet gelezen)
Voor degenen die de voorkeur geven aan werk direct met de vergelijking, i t is m = som [(x_i - x_avg) (y_i - y_avg)] /sum [(x_i - x_avg) ^ 2].
Veel spreadsheets hebben verschillende lineaire regressiefuncties. In Microsoft Excel kunt u de functie "Helling" gebruiken om het gemiddelde van de x- en y-kolommen te nemen en voert het werkblad automatisch alle resterende berekeningen uit.

Hoofdlijnen
- Hoeveel calorieën verbrand ik als ik lach?
- Nu waren gestrest? Geschiedenis toont de oudste emotie
- Geheugenhack:doe wat aerobics vier uur na de les
- Relatie tussen ademhaling en stofwisseling
- Wat houdt de genetische continuïteit in?
Je kunt op veel manieren nadenken over genetische continuïteit. In zekere zin verwijst het naar de consistente replicatie van genetische informatie van een oudercel naar twee dochtercellen. Een ander perspec
- Waarom is UV-licht schadelijk?
- Simpele microscoopexperimenten
- Trofisch niveau (voedselketen en web): definitie en voorbeelden (met diagram)
- Wat zijn de vier organische moleculen die in levende wezens worden gevonden?
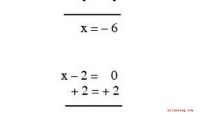




 Hoe de waarde voor de Vce in een transistor
Hoe de waarde voor de Vce in een transistor- Hoe werkt de condensor in een fluorescentielamp?
- Wat is het pad van het licht door het oog?
- Welke van Mans-activiteiten versnelt de erosie?
- Inductiewet van Faradays: definitie, formule en voorbeelden
- Factoren die een selectiesite voor een hydro-elektrisch station beïnvloeden
- Wat is de dichtheid van een ei?
- De San Andreas-fout:komt de grote er aan?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
