Wetenschap
AI-techniek doet dubbele taak over kosmische en subatomaire schalen
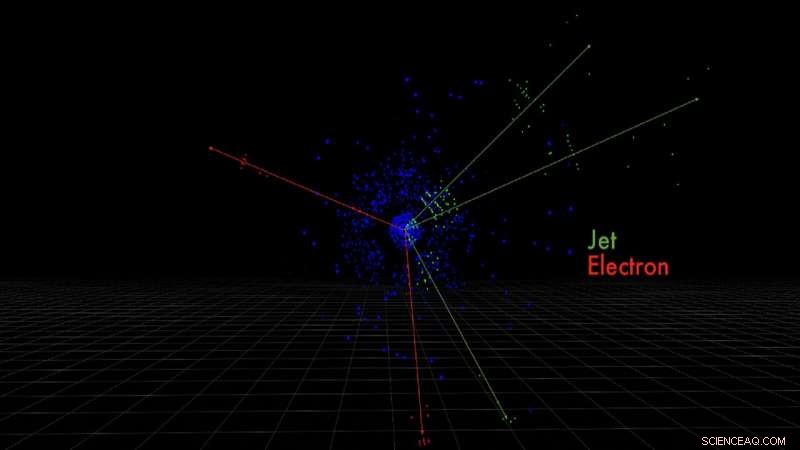
Dit zijn de detectorpixels voor elektronen en quarkjets geproduceerd door een gesimuleerde protonbotsing, gemeten door de ATLAS-detector. Krediet:Taylor Childers
Terwijl hoge-energiefysica en kosmologie werelden uit elkaar lijken in termen van enorme schaal, natuurkundigen en kosmologen in Argonne gebruiken vergelijkbare machine learning-methoden om classificatieproblemen voor zowel subatomaire deeltjes als sterrenstelsels aan te pakken.
Hoge-energiefysica en kosmologie lijken qua schaal, maar de onzichtbare componenten waaruit het veld van de ene bestaat, bepalen de compositie en dynamiek van de andere - instortende sterren, ster-bevalling nevels en, misschien, donkere materie.
Al decenia, de technieken waarmee onderzoekers in beide vakgebieden hun domeinen bestudeerden leken bijna onverenigbaar, ook. Hoge-energiefysica vertrouwde op versnellers en detectoren om enig inzicht te krijgen uit de energetische interacties van deeltjes, terwijl kosmologen door allerlei telescopen staarden om de geheimen van het universum te onthullen.
Hoewel geen van beiden de fundamentele uitrusting van hun specifieke vakgebied heeft opgegeven, natuurkundigen en kosmologen van het Argonne National Laboratory van het Amerikaanse Department of Energy (DOE) vallen complexe multischaalproblemen aan met behulp van verschillende vormen van een kunstmatige-intelligentietechniek die machine learning wordt genoemd.
Reeds gebruikt in tal van gebieden, machine learning kan helpen verborgen patronen te identificeren door te leren van invoergegevens en door voorspellingen over nieuwe gegevens geleidelijk te verbeteren. Het kan worden toegepast op visuele classificatietaken of bij de snelle reproductie van gecompliceerde en rekenkundig dure berekeningen.
Met het potentieel om de manier waarop wetenschap wordt bedreven radicaal te veranderen, deze AI-technieken zullen ons helpen een beter begrip te krijgen van de verspreiding van sterrenstelsels door het heelal of de vorming van nieuwe deeltjes beter te visualiseren waaruit we nieuwe fysica zouden kunnen afleiden.
"In de loop van de decennia we hebben traditionele algoritmen ontwikkeld die de handtekeningen reconstrueren van de verschillende deeltjes waarin we geïnteresseerd zijn, " zei Taylor Childers, een deeltjesfysicus en een computerwetenschapper met de Argonne Leadership Computing Facility (ALCF), een DOE Office of Science gebruikersfaciliteit.
"Het heeft erg lang geduurd om ze te ontwikkelen en ze zijn zeer nauwkeurig, "voegde hij eraan toe. "Maar tegelijkertijd, het zou interessant zijn om te weten of beeldclassificatietechnieken van machine learning die met succes door Google en Facebook zijn gebruikt, de ontwikkeling van algoritmen die deeltjessignaturen in onze 3D-detectoren identificeren, kunnen vereenvoudigen of verkorten."
Childers werkt samen met hoogenergetische fysici uit Argonne, die allemaal lid zijn van de ATLAS-experimentele samenwerking bij CERN's Large Hadron Collider (LHC), de grootste en krachtigste deeltjesversneller ter wereld. Op zoek naar het oplossen van een breed scala aan natuurkundige problemen, de ATLAS-detector zit acht verdiepingen hoog en 50 voet lang op een punt rond de 17-mijls-colliderring van de LHC, waar het de producten meet van protonen die botsen met snelheden die de lichtsnelheid benaderen.
Volgens de ATLAS-website, "elke seconde vinden er meer dan een miljard deeltjesinteracties plaats in de ATLAS-detector, een datasnelheid gelijk aan 20 gelijktijdige telefoongesprekken gehouden door elke persoon op aarde."
Hoewel slechts een klein percentage van deze botsingen het bestuderen waard wordt geacht - ongeveer een miljoen per seconde - levert het nog steeds een berg gegevens op voor wetenschappers om te onderzoeken.
Deze snelle deeltjesbotsingen creëren nieuwe deeltjes in hun kielzog, zoals elektronen of quarkdouches, elk laat een unieke handtekening achter in de detector. Het zijn deze handtekeningen die Childers wil identificeren door middel van machine learning.
Een van de uitdagingen is het vastleggen van die energiesignaturen als afbeeldingen in een complexe 3D-ruimte. Een foto, bijvoorbeeld, is in wezen een 2D-weergave van 3D-gegevens met verticale en horizontale posities. De pixelgegevens, de kleuren in de afbeelding, zijn ruimtelijk georiënteerd en bevatten ruimtelijke informatie gecodeerd, bijvoorbeeld de ogen van een kat zijn naast de neus, en de oren zijn links en rechts boven.
"Dus hun ruimtelijke oriëntatie is belangrijk. Hetzelfde geldt voor de beelden die we maken bij de LHC. Als een deeltje onze detector doorkruist, het laat een energiesignatuur achter in ruimtelijke patronen die specifiek zijn voor de verschillende deeltjes, ", legt Childers uit.
Voeg daarbij de hoeveelheid gegevens die is gecodeerd in niet alleen de handtekeningen, maar de 3D-ruimte eromheen. Waar traditionele machine learning-voorbeelden voor beeldherkenning - die katten, opnieuw - omgaan met honderdduizenden pixels, De afbeeldingen van ATLAS bevatten honderden miljoenen detectorpixels.
Dus het idee, hij zei, is om de detectorbeelden als traditionele beelden te behandelen. Met behulp van een machine learning-techniek genaamd convolutionele neurale netwerken - die leren hoe gegevens ruimtelijk gerelateerd zijn - kunnen ze de 3D-ruimte extraheren om specifieke deeltjeskenmerken gemakkelijker te identificeren.

De afbeelding toont een Einstein-ring (midden rechts) gevormd door zwaartekrachtlensing van een stervormend sterrenstelsel (blauw) door een enorm lichtgevend rood sterrenstelsel (oranje). Dit systeem werd voor het eerst ontdekt door de Sloan Digital Sky Survey in 2007; de beelden zijn afkomstig van de Hubble-ruimtetelescoop. Krediet:NASA
Childers hoopt dat deze machine learning-algoritmen uiteindelijk de traditionele handgemaakte algoritmen zullen vervangen, de tijd die nodig is om vergelijkbare hoeveelheden gegevens te verwerken aanzienlijk te verminderen en de nauwkeurigheid van de meetresultaten te verbeteren.
"We kunnen ook de tien jaar durende ontwikkeling die nodig is voor nieuwe detectoren vervangen en die verminderen met nieuwe trainingsmodellen voor toekomstige detectoren. " hij zei.
Een grotere ruimte
Argonne-kosmologen gebruiken vergelijkbare machine learning-methoden om classificatieproblemen aan te pakken, maar op veel grotere schaal.
"Het probleem met kosmologie is dat de objecten waar we naar kijken ingewikkeld en wazig zijn, " zei Salman Habib, Divisiedirecteur van Argonne's Computational Science-divisie en interim-adjunct-directeur van de High Energy Physics-divisie. "Dus het op een eenvoudigere manier beschrijven van gegevens wordt erg moeilijk."
Hij en zijn collega's maken gebruik van supercomputers in Argonne en andere nationale DOE-laboratoria om de bijzonderheden van het universum te reconstrueren, melkweg voor melkweg. Ze maken zeer gedetailleerde gesimuleerde melkwegcatalogi die kunnen worden gebruikt voor vergelijking met echte gegevens van onderzoekstelescopen, zoals de Large Synoptic Survey Telescope, een samenwerking tussen de DOE en de National Science Foundation.
Maar om deze activa waardevol te maken voor onderzoekers, ze moeten zo dicht mogelijk bij de werkelijkheid liggen.
Machine learning-algoritmen, Habib zei, zijn erg goed in het uitkiezen van kenmerken die gemakkelijk kunnen worden gekarakteriseerd door geometrie, zoals die katten. Nog, vergelijkbaar met de waarschuwing op autospiegels, objecten in de hemel zijn niet altijd zoals ze lijken.
Neem het fenomeen van sterke zwaartekrachtlensvorming; de vervorming van een achtergrondlichtbron - een melkwegstelsel of een cluster van melkwegstelsels - door een tussenliggende massa. De afbuiging van de banen van lichtstralen van de bron als gevolg van de zwaartekracht leidt tot een vervorming van de vorm van de achtergrondbron, positie en oriëntatie; deze vervorming geeft informatie over de massaverdeling van het tussenliggende object. De feitelijke waarnemingssituatie is niet zo eenvoudig, echter.
Een volledig ronde klodder met een lens, bijvoorbeeld, in de een of andere richting uitgerekt lijken, terwijl een ronde, schijfvormig object zonder lens kan er elliptisch uitzien als het gedeeltelijk op de rand wordt bekeken.
"Dus hoe weet je of het object waar je naar kijkt geen rond object is dat is gedraaid, of een lens met een lens?" vroeg Habib. "Dit zijn het soort lastige dingen die machine learning moet kunnen oplossen."
Om dit te doen, onderzoekers creëren een trainingsvoorbeeld van miljoenen realistisch ogende objecten, waarvan de helft lensvormig is. De machine learning-algoritmen proberen vervolgens de verschillen tussen de objecten met en zonder lens te leren. De resultaten worden geverifieerd aan de hand van een bekende reeks objecten met en zonder lens.
Maar de resultaten vertellen maar de helft van het verhaal:hoe goed de algoritmen werken op testgegevens. Om hun nauwkeurigheid voor echte gegevens verder te verbeteren, onderzoekers mengen een bepaald percentage synthetische gegevens met eerder waargenomen gegevens en voeren de algoritmen uit, opnieuw, vergelijken hoe goed ze objecten met een lens in de trainingssteekproef kozen versus de combinatiegegevens.
"Uiteindelijk, je zou kunnen ontdekken dat het redelijk goed werkt, maar misschien niet zo goed als je wilt, " legde Habib uit. "Je zou kunnen zeggen 'OK, deze informatie alleen is niet voldoende, Ik moet meer verzamelen.' Het is een vrij lang en complex proces."
Twee hoofddoelen van de moderne kosmologie, hij zei, zijn om te begrijpen waarom de uitdijing van het heelal versnelt en wat de aard van de donkere materie is. Donkere materie is ongeveer vijf keer zo overvloedig als normale materie, maar de uiteindelijke oorsprong blijft mysterieus. Om op afstand dicht bij een antwoord te komen, de wetenschap moet zeer weloverwogen zijn, erg precies.
"In het huidige stadium Ik denk niet dat we al onze problemen met machine learning-toepassingen kunnen oplossen, " gaf Habib toe. "Maar ik zou zeggen dat machine learning in de nabije toekomst erg belangrijk zal zijn voor alle aspecten van precisiekosmologie."
Naarmate machine learning-technieken worden ontwikkeld en verfijnd, hun bruikbaarheid voor zowel de hoge-energiefysica als de kosmologie zal zeker exponentieel groeien, het bieden van hoop op nieuwe ontdekkingen of nieuwe interpretaties die ons begrip van de wereld op meerdere schalen veranderen.
 Nieuw onderzoek toont aan dat alle solid-state batterijen met de hoogste energiedichtheid nu mogelijk zijn
Nieuw onderzoek toont aan dat alle solid-state batterijen met de hoogste energiedichtheid nu mogelijk zijn- Onderzoekers testen Lamborghini's koolstofvezelmaterialen in de ruimte
- Wat gebeurt er als SO2 reageert met staal?
- Biosensorverband verzamelt en analyseert zweet
- Welke pH-waarden worden als sterk en zwak beschouwd?
- Eta terug naar zee terwijl Midden-Amerika schade en doden telt
- 2e grote sneeuwstorm in een week dekens Noordoost
- IJsbedekking neemt diepe duik op Grote Meren
- Rechtbank beveelt Frankrijk om tekort aan broeikasgasreductie op te lossen
- VN-chefs roepen op om de Stille Oceaan te redden om de wereld te redden
Hoofdlijnen
- El Nino in de Stille Oceaan heeft invloed op dolfijnen in West-Australië
- Een stap dichter bij gewassen met twee keer de opbrengst
- Woestijn in Zuid-Californië overspoeld met de beste superbloei in 20 jaar
- Nieuwsgierige grote witte haai speelt met camera
- Thomas Malthus: Biografie, Populatietheorie & Feiten
- Wolven bleken meer coöperatief te zijn met hun eigen soort dan honden met die van hen
- Hoe genenbanken werken
- Hoe kleine robots uw gezondheid van binnenuit kunnen verbeteren
- Wat is het Forer-effect?
- Onderzoekers gebruiken een laserpenseel om miniatuurmeesterwerken te maken

- Ongebruikelijke elektronendeling gevonden in koel kristal
- Intense laserexperimenten leveren het eerste bewijs dat licht elektronen kan stoppen
- A Poor Mans-methode om goud te smelten

- ORNL werkt samen met Los Alamos, EPB demonstreert de nieuwste generatie netwerkbeveiligingstechnologie


 'S Werelds kortste laserpuls
'S Werelds kortste laserpuls- Vietnams Rong Dragon Bridge ademt eigenlijk vuur
- Nieuwe test van donkere energie en expansie van kosmische structuren
- Dat was een korte vlucht:bemanning van mislukte raket houdt het hoofd koel
- Wat als de ozonlaag zou verdwijnen?
- De dynamiek van stikstofhoudende meststoffen in de wortelzone
- Hoe te verwijderen van Acid
- Wat doet Choline voor het lichaam?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
