Wetenschap
Verrassende voorkeur voor eenvoud gevonden in gemeenschappelijk model
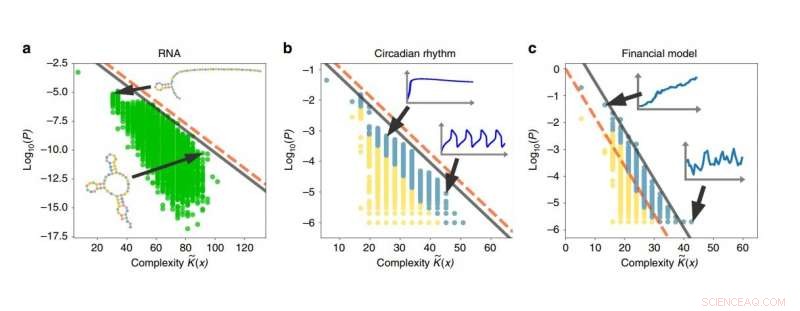
Voorbeelden van eenvoudsbias in RNA-sequenties, circadiaanse ritmes, en financiële modellen. Hoe hoger de complexiteit van een output, hoe kleiner de kans dat de output wordt gegenereerd. Krediet:Dingle, et al. Gepubliceerd in Natuurcommunicatie
Onderzoekers hebben ontdekt dat input-outputkaarten, die op grote schaal worden gebruikt in de wetenschap en techniek om systemen te modelleren, variërend van natuurkunde tot financiën, zijn sterk bevooroordeeld in de richting van het produceren van eenvoudige output. De resultaten zijn verrassend, als naïef is er geen reden om te vermoeden dat de ene output waarschijnlijker is dan de andere.
De onderzoekers, Kamaludin Dingle, Chico Q. Camargo, en Ard A. Louis, aan de Universiteit van Oxford en aan de Gulf University for Science and Technology, hebben een paper over hun resultaten gepubliceerd in een recent nummer van Natuurcommunicatie .
"Het grootste belang van ons werk is onze voorspelling dat eenvoudsbias - dat eenvoudige uitvoer exponentieel meer wordt gegenereerd dan complexe uitvoer - geldt voor een breed scala aan systemen in wetenschap en techniek, " vertelde Louis" Phys.org . "De eenvoudsbias houdt in dat, voor een systeem dat is gemaakt van veel verschillende op elkaar inwerkende onderdelen - zeg, een circuit met veel componenten, een netwerk met veel chemische reacties, enz. - de meeste combinaties van parameters en invoer zouden moeten resulteren in eenvoudig gedrag."
Het werk put uit het veld van de algoritmische informatietheorie (AIT), die zich bezighoudt met de verbindingen tussen informatica en informatietheorie. Een belangrijk resultaat van AIT is de coderingsstelling. Volgens deze stelling, wanneer een universele Turing-machine (een abstract computerapparaat dat elke functie kan berekenen) een willekeurige invoer krijgt, eenvoudige outputs hebben een exponentieel grotere kans om te worden gegenereerd dan complexe outputs. Zoals de onderzoekers uitleggen, dit resultaat staat haaks op de naïeve verwachting dat alle outputs even waarschijnlijk zijn.
Ondanks deze intrigerende bevindingen, tot nu toe is de coderingsstelling zelden toegepast op echte systemen. Dit komt omdat de stelling slechts op een zeer abstracte manier is geformuleerd, en een van de belangrijkste componenten - een complexiteitsmaatstaf die de Kolmogorov-complexiteit wordt genoemd - is niet te berekenen.
"De coderingsstelling van Solomonoff en Levin is een opmerkelijk resultaat dat eigenlijk veel meer bekend zou moeten zijn, Louis zei. "Het voorspelt dat outputs met een lage complexiteit exponentieel meer worden gegenereerd door een universele Turing-machine (UTM) dan outputs met een hoge complexiteit. Aangezien alles wat berekenbaar is, kan worden berekend op een UTM, dat is een vrij verbazingwekkende voorspelling!
"Echter, de coderingsstelling is onduidelijk gebleven omdat UTM's nogal abstract zijn, omdat alleen kan worden bewezen dat het geldt binnen de asymptotische limiet van grote complexiteiten, en omdat de Kolmogorov-maatstaf die wordt gebruikt om de complexiteit te bepalen fundamenteel onberekenbaar is. Ons werk omzeilt deze problemen door een iets zwakkere versie van de coderingsstelling te gebruiken die veel gemakkelijker toe te passen is."
In de nieuwe, zwakkere versie van de coderingsstelling, de onderzoekers hebben de Kolmogorov-complexiteit vervangen door een benaderingscomplexiteit, wat berekenbaar is, met behoud van de exponentiële voorkeur voor eenvoud. De zwakkere coderingsstelling kan gemakkelijk worden toegepast om voorspellingen te doen met betrekking tot praktische systemen.
"We gebruiken de taal van input-outputkaarten, wat nogal abstract klinkt, ' zei Louis. 'Echter, veel systemen die in de wetenschap en techniek worden bestudeerd, zetten een soort invoer om in een soort uitvoer via een algoritme. Bijvoorbeeld, de informatie die is gecodeerd in het DNA van een organisme (zijn genotype) kan worden gezien als input, terwijl de kenmerken en het gedrag van het organisme (het fenotype) kunnen worden gezien als de output. In een reeks differentiaalvergelijkingen, de invoer is de parameters van de vergelijkingen, en de output is de oplossing van die vergelijkingen, enkele randvoorwaarden gegeven.
"We stellen dat als je willekeurig invoerparameters kiest, dan hebben dergelijke systemen exponentieel meer kans om eenvoudige outputs te produceren dan complexe outputs. Aangezien deze voorspelling geldt voor een breed scala aan kaarten, we maken een brede claim. Maar dat is een van zijn sterke punten. Onze afleiding vereist niet veel weten over hoe de kaart (of het algoritme) in kwestie eigenlijk werkt.
"Dus de belangrijkste betekenis van ons werk is dat onze zwakkere versie van de coderingsstelling ongeveer de exponentiële voorkeur voor eenvoud van de oorspronkelijke coderingsstelling handhaaft, maar is in de praktijk veel gemakkelijker toe te passen."
Een gevolg van de resultaten is dat het mogelijk is om de waarschijnlijkheid van een bepaalde uitkomst te voorspellen op basis van de complexiteit ervan. Hoewel een eenvoudige uitvoer exponentieel vaker voorkomt dan een complexe uitvoer, de onderzoekers merken op dat dit niet noodzakelijkerwijs betekent dat eenvoudige outputs vaker voorkomen dan complexe outputs in het algemeen, omdat er in het algemeen veel complexere outputs kunnen zijn dan eenvoudige.
Om enkele toepassingen te illustreren, de onderzoekers gebruikten de gewijzigde coderingsstelling om systemen van RNA-sequenties te analyseren, circadiaanse ritmes, en financiële markten, en toonde aan dat al deze systemen de eenvoudsbias vertonen. In de toekomst, ze zijn ook van plan de resultaten toe te passen op computeralgoritmen, biologische evolutie, en chaotische systemen. Echter, voor een meer intuïtieve uitleg van wat eenvoudsbias betekent, de onderzoekers beschrijven een scenario waarbij onze verwanten van primaten betrokken zijn:
"Beschouw het bekende probleem van apen die op een typemachine typen, ' zei Louis. 'Als de apen echt willekeurig typen, en de typemachine heeft N sleutels, dan is de kans op het krijgen van een bepaalde reeks van lengte k is slechts 1/ N k , aangezien er een 1/ N kans om de juiste toetsaanslag te krijgen bij elk van de k stappen. Dus elke reeks van lengte k even waarschijnlijk of onwaarschijnlijk is.
"Beschouw nu het geval waarin de apen in een computerprogramma typen. Ze kunnen dan per ongeluk een kort programma typen dat een lange uitvoer genereert. Bijvoorbeeld, er is een code van 133 tekens in de programmeertaal C die de eerste 15 correct genereert, 000 cijfers van . Dus in plaats van 1/ N 15, 000 , wat is de kans dat apen dit goed krijgen op een typemachine, de kans is veel lager, 1 maar/ N 133 , die de apen π genereren op de computer.
Het blijkt dat de meeste nummers geen korte programma's hebben die ze genereren, dus het beste wat de apen op de computer voor deze getallen kunnen doen, is een programma typen als 'nummer afdrukken, ', wat de kans klein is dat ze het hoe dan ook goed op een typemachine zouden krijgen. Maar voor eenvoudige uitgangen, de kans is veel groter dan voor de typemachine. Per definitie, eenvoudige uitgangen worden gedefinieerd als die met korte programma's die ze beschrijven, en complexe outputs zijn die die alleen kunnen worden beschreven door lange programma's. Dus π is, per definitie, een nummer met een lage complexiteit, en daarom is het veel waarschijnlijker dat het wordt gegenereerd door apen die in een computerprogramma typen dan veel andere getallen die niet eenvoudig zijn.
"Wat de coderingsstelling doet, is dit intuïtieve verhaal kwantitatief maken. Korte programma's worden eerder willekeurig ingetypt, en aangezien waarschijnlijkheden voor lengte k programma's schalen ook als 1/ N k , eenvoudige uitvoer is exponentieel veel waarschijnlijker dan complexe. Onze bijdrage is om aan te tonen hoe de exponentiële relatie tussen waarschijnlijkheid en complexiteit voor veel praktische systemen eenvoudig kan worden berekend. Wat leuk is, is dat je niet veel hoeft te weten over de kaart (of het algoritme) om te bepalen of een uitvoer waarschijnlijk zal verschijnen of niet. Voor een goede eerste benadering, hoe meer samendrukbaar een uitvoer is, hoe groter de kans dat het verschijnt bij willekeurige invoer."
© 2018 Fys.org
 Microstaafjes gemaakt van lanthanoïde organische raamwerken fungeren als optische golfgeleiders op microschaal
Microstaafjes gemaakt van lanthanoïde organische raamwerken fungeren als optische golfgeleiders op microschaal- Onderzoekers ontwikkelen een vast materiaal met mobiele deeltjes die reageren op de omgeving
- Kankercellen targeten door elektrische stromen te meten
- Implanteerbaar piëzo-elektrisch polymeer verbetert gecontroleerde afgifte van medicijnen
- Biomedische ingenieurs maken slimme verbanden om chronische wonden te genezen
- Superdiepe diamant levert eerste bewijs in de natuur van het vierde meest voorkomende mineraal op aarde
- Langst bekende ononderbroken registratie van het Paleozoïcum ontdekt in de wildernis van Yukon
- 5 dingen die je niet wist over Paleoart
- Kunstmatige intelligentie kan helpen bij het bereiken van de duurzame ontwikkelingsdoelen van de VN
- Geofysici ontdekken nieuw bewijs voor een alternatieve stijl van platentektoniek
Hoofdlijnen
- Het idee testen dat milieu-uitdagingen de evolutie van grotere hersenen stimuleren
- Wat is een eigenschap die het resultaat is van twee dominante genen?
- Deze pijnbomen leunen bijna altijd naar de evenaar
- Namen van de enzymen in de mond & slokdarm
- Wat zijn chromatine en chromosomen?
- Mexico vangt zeldzame vaquita-bruinvis om soorten te redden
- Centriolen:je kunt cellen niet verdelen zonder ze
- Octopussen gestrand op het strand van Wales - hier zijn de wetenschappelijke theorieën waarom
- Cladistics: Definitie, methode en voorbeelden
- Onderzoekers ontwikkelen mijlpaal voor ultrasnelle communicatie en computergebruik

- Hoe oppervlakte uit volume

- Hadronen berekenen met behulp van supercomputers

- Onderzoekers creëren nieuw Bose-Einstein-condensaat

- Onderzoek naar de dynamiek van democratische verkiezingen met behulp van natuurkundige theorie

 Wapeninggrootte voor platen
Wapeninggrootte voor platen- Studie toont Witte Huis, Pentagon zijn letterlijk enkele van de populairste plekken in Washington
- Amerikaanse rechter beveelt gesprekken tussen Tesla's Musk, effectenregelgevers
- Galactische winden vertragen de vorming van nieuwe sterren
- Voordelen en nadelen van externe bevruchting
- Machines zullen in 2025 meer taken doen dan mensen:WEF
- Sociaal isolement begint af te nemen sinds de introductie van vaccins
- Hoe vernieuwt de watercyclus de toevoer van zoet water door de aarde?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
