Wetenschap
Betrouwbare kwantumcomputers ontwikkelen
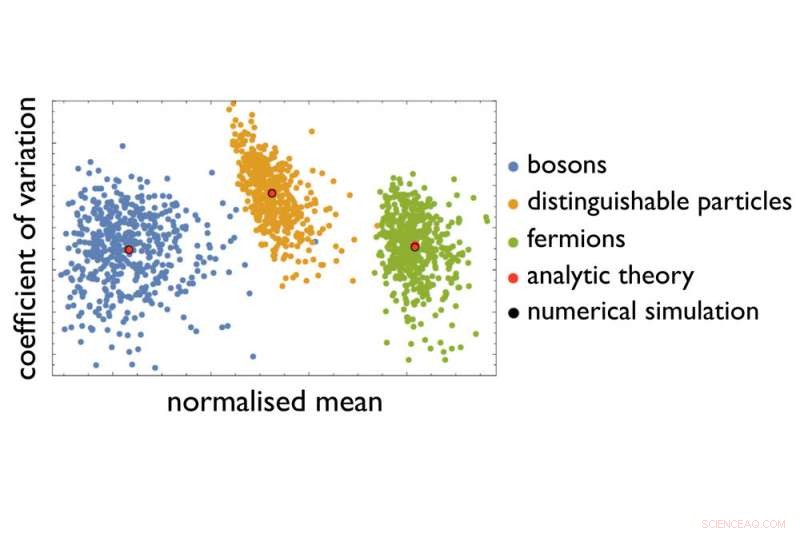
Kwantumoptica en statistiek. Krediet:Universiteit van Freiburg
Kwantumcomputers kunnen op een dag algoritmische problemen oplossen die zelfs de grootste supercomputers van tegenwoordig niet aankunnen. Maar hoe test je een kwantumcomputer om er zeker van te zijn dat deze betrouwbaar werkt? Afhankelijk van de algoritmische taak, dit kan een eenvoudig of een zeer moeilijk certificeringsprobleem zijn. Een internationaal team van onderzoekers heeft een belangrijke stap gezet in de richting van het oplossen van een moeilijke variant van dit probleem, met behulp van een statistische benadering ontwikkeld aan de Universiteit van Freiburg. De resultaten van hun onderzoek zijn gepubliceerd in de laatste editie van Natuurfotonica .
Hun voorbeeld van een moeilijk certificeringsprobleem is het sorteren van een bepaald aantal fotonen nadat ze een gedefinieerde opstelling van verschillende optische elementen hebben doorlopen. De opstelling voorziet elk foton van een aantal transmissiepaden - afhankelijk van of het foton wordt gereflecteerd of doorgelaten door een optisch element. De taak is om de kans te voorspellen dat fotonen de opstelling op gedefinieerde punten verlaten, voor een bepaalde positionering van de fotonen bij de ingang van de opstelling. Met een toenemende omvang van de optische opstelling en een toenemend aantal fotonen dat op hun weg wordt gestuurd, het aantal mogelijke paden en verdelingen van de fotonen aan het einde stijgt sterk als gevolg van het onzekerheidsprincipe dat ten grondslag ligt aan de kwantummechanica - zodat er geen voorspelling kan worden gedaan van de exacte waarschijnlijkheid met behulp van de computers die ons vandaag ter beschikking staan. Fysische principes zeggen dat verschillende soorten deeltjes - zoals fotonen of elektronen - verschillende kansverdelingen moeten opleveren. Maar hoe kunnen wetenschappers deze verdelingen en verschillende optische arrangementen van elkaar onderscheiden als er geen manier is om exacte berekeningen te maken?
Een benadering die in de huidige studie is ontwikkeld, maakt het nu voor het eerst mogelijk om karakteristieke statistische handtekeningen te identificeren over onmeetbare kansverdelingen. In plaats van een volledige "vingerafdruk, " konden ze de informatie destilleren uit datasets die werden verkleind om ze bruikbaar te maken. Met behulp van die informatie, ze waren in staat om verschillende soorten deeltjes en onderscheidende kenmerken van optische arrangementen te onderscheiden. Het team toonde ook aan dat dit distillatieproces kan worden verbeterd, gebruikmakend van gevestigde technieken van machine learning, waarbij de natuurkunde de belangrijkste informatie levert over welke dataset moet worden gebruikt om de relevante patronen te zoeken. En omdat deze benadering nauwkeuriger wordt voor grotere aantallen deeltjes, de onderzoekers hopen dat hun bevindingen ons een belangrijke stap dichter bij de oplossing van het certificeringsprobleem brengen.
 Onderzoekers pionieren met nieuwe techniek om gebruikte melkflessen om te vormen tot kajaks en opslagtanks
Onderzoekers pionieren met nieuwe techniek om gebruikte melkflessen om te vormen tot kajaks en opslagtanks- Nieuwe methode voor het opsporen van ziekten, waaronder coronavirus en cystische fibrose
- Cementloze vliegasbinder maakt beton groen
- Polymeer afgeleid van materiaal in de schelpen van garnalen kan geneesmiddelen tegen kanker afleveren op tumorplaatsen
- Diamant van nanoformaat zal materialen voor maritiem transport verbeteren
- Native Oak Trees of Louisiana
- Biologische afbraak van olie geremd in diepzeesedimenten
- GIE gebruiken om ontbossing in het Amazone-regenwoud in kaart te brengen
- Europese toezichthouder dringt er bij banken op aan om klimaatrisico's te evalueren
- Klimaatengineering:internationale bijeenkomst onthult spanningen
Hoofdlijnen
- Biochemistry Blotting Techniques
- Geërgerd door andere volkeren friemelen? Studie zegt dat je niet alleen bent
- Mobiele genetische elementen die de functie van nabijgelegen genen veranderen
- Nieuw fundamenteel inzicht in de strijd tegen bacteriën
- Hoe maak je een 3D-plant eukaryotisch celmodel
- Vroege mensen gepaard met ingeteelde neanderthalers - tegen een prijs
- Wat zijn de vijf klassen van immunoglobulinen?
- Een sociaal controlesysteem garandeert de zuiverheid van embryonale stamcellen
- Hoe maak je een modelhart met materialen uit je thuis





 Zou het antwoord op de grondwatervoorraden hoog in de lucht kunnen komen?
Zou het antwoord op de grondwatervoorraden hoog in de lucht kunnen komen?- Alaska vulkaan Q&A:uitbarstingen hebben hoogvliegende gevolgen
- Planten en dieren die leven in de buurt van de Koalas Habitat
- Hoe een GPA naar N /MM2 te converteren
- Ubisoft wil vijf miljard spelers binnenhalen met Tencent-deal
- Moordenaar Christine Jessops geïdentificeerd:opgeloste cold case roept vragen op over genetische privacy
- Te nat? Te koud? Te heet? Zo beïnvloedt het weer de reizen die we maken
- Complementaire en aanvullende hoeken berekenen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
