Wetenschap
CERN Data Center passeert mijlpaal van 200 petabyte

het datacentrum van CERN. Krediet:Robert Hradil, Monika Majer/ProStudio22.ch
Op 29 juni 2017, het CERN DC heeft de mijlpaal bereikt van 200 petabyte aan gegevens die permanent in zijn tapebibliotheken zijn gearchiveerd. Waar komen deze gegevens vandaan? Deeltjes botsen in de Large Hadron Collider (LHC) detectoren ongeveer 1 miljard keer per seconde, het genereren van ongeveer één petabyte aan botsingsgegevens per seconde. Echter, dergelijke hoeveelheden gegevens zijn voor de huidige computersystemen onmogelijk vast te leggen en worden daarom gefilterd door de experimenten, alleen de meest "interessante" houden. De gefilterde LHC-gegevens worden vervolgens geaggregeerd in het CERN Data Center (DC), waar de initiële gegevensreconstructie wordt uitgevoerd, en waar een kopie wordt gearchiveerd naar langdurige opslag op tape. Zelfs na de drastische gegevensreductie die door de experimenten werd uitgevoerd, het CERN DC verwerkt gemiddeld één petabyte aan data per dag. Zo werd op 29 juni de mijlpaal bereikt van 200 petabyte aan permanent gearchiveerde gegevens in de tapebibliotheken.
De vier grote LHC-experimenten hebben de afgelopen twee jaar ongekende hoeveelheden gegevens opgeleverd. Dit is grotendeels te danken aan de uitstekende prestaties en beschikbaarheid van de LHC zelf. Inderdaad, in 2016, verwachtingen waren aanvankelijk voor ongeveer 5 miljoen seconden aan gegevensopname, terwijl het uiteindelijke totaal ongeveer 7,5 miljoen seconden was, een zeer welkome verhoging van 50%. 2017 volgt een vergelijkbare trend.
Verder, aangezien de lichtsterkte hoger is dan in 2016, veel botsingen overlappen elkaar en de gebeurtenissen zijn complexer, steeds geavanceerdere reconstructie en analyse vereisen. Dit heeft een sterke impact op de computervereisten. Bijgevolg, records worden gebroken in veel aspecten van data-acquisitie, datasnelheden en datavolumes, met uitzonderlijke gebruiksniveaus voor computer- en opslagbronnen.
Om deze uitdagingen aan te gaan, de computerinfrastructuur in het algemeen, en met name de opslagsystemen, heeft tijdens de twee jaar van Long Shutdown 1 grote upgrades en consolidatie ondergaan. Dankzij deze upgrades kon het datacenter omgaan met de 73 petabyte aan gegevens die in 2016 werden ontvangen (waarvan 49 LHC-gegevens) en met de gegevensstroom die tot nu toe in 2017. Dankzij deze upgrades heeft het CERN Advanced STORage-systeem (CASTOR) ook de uitdagende mijlpaal van 200 petabyte aan permanent gearchiveerde gegevens bereikt. Deze permanent gearchiveerde gegevens vertegenwoordigen een belangrijk deel van de totale hoeveelheid ontvangen gegevens in het CERN-datacentrum, de rest zijn tijdelijke gegevens die periodiek worden opgeschoond.
Een ander gevolg van de grotere datavolumes is een toegenomen vraag naar dataoverdracht en dus een behoefte aan een hogere netwerkcapaciteit. Sinds begin februari is een derde glasvezelcircuit van 100 Gb/s (gigabit per seconde) verbindt het CERN DC met de externe extensie die wordt gehost in het Wigner Research Center for Physics (RCP) in Hongarije, 1800 km verderop. Dankzij de extra bandbreedte en redundantie die door deze derde link wordt geboden, kan CERN op betrouwbare wijze profiteren van de rekenkracht en opslag op de externe extensie. Een must-have in de context van toenemende computerbehoeften!
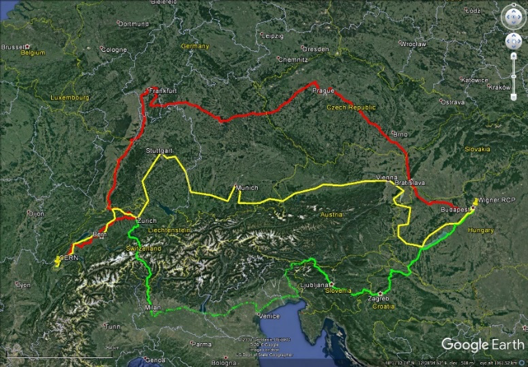
Deze kaart toont de routes voor de drie 100 Gbit/s glasvezelverbindingen tussen CERN en de Wigner RCP. De routes zijn zorgvuldig gekozen om ervoor te zorgen dat we de connectiviteit behouden in het geval van incidenten. (Afbeelding:Google)
 Studie lost mysterie op over hoe de eerste dieren op aarde verschenen
Studie lost mysterie op over hoe de eerste dieren op aarde verschenen- Wat eet een nijlpaard?
- Bodememissies in Central Valley een grote bron van vervuiling door stikstofoxiden
- Als vogeltjes samen poepen
- Nieuwe wetenschappelijke methode om waterkwaliteitscriteria van metalen af te leiden voor de bescherming van verschillende mariene ecosystemen wereldwijd
Hoofdlijnen
- Deze dans wordt uitgevoerd:honderden mannelijke kikkersoorten veranderen van kleur rond de paringstijd
- Wetenschappers nemen de temperatuur van knokkelkoorts risico
- Wat is de meest logische volgorde van stappen voor het splitsen van vreemd DNA?
- Ondanks de wet stijgt het aantal doden door loodvergiftiging in New Hampshire
- Lovelorn koala gepakt na ontsnapping uit dierentuin op jacht naar partner
- Wat veroorzaakt psychische aandoeningen?
- Model voorspelt hoe E. coli-bacteriën zich aanpassen onder stress
- Onderzoekers demonstreren een technische benadering om medicijnen te combineren, controle parasitaire wormen
- Wit vlees of donker vlees? Big data serveren om het Thanksgiving-diner te ontcijferen
- Zonlichttrechter verzamelt licht uit alle richtingen
- Elektronenorbitalen kunnen de sleutel zijn tot het verenigende concept van supergeleiding bij hoge temperatuur
- ATLAS-experiment meet Higgs-bosonkoppeling met top-quark in difotonkanaal met volledige Run 2-gegevensset

- Mijlpaal op weg naar het inschakelen van 's werelds grootste supergeleidende lineaire versneller

- Onderzoekers ontwikkelen 's werelds kleinste ultrasone detector


 Onderzoekers ontwikkelen alternatief voor verspillend methaan affakkelen
Onderzoekers ontwikkelen alternatief voor verspillend methaan affakkelen- Afgeleide voetgangers lopen langzamer en staan minder stabiel:studeren
- Gouden nanostaafjes zouden de bestralingstherapie van hoofd- en nekkanker kunnen verbeteren
- De eerste zachte ringoscillator laat zachte robots rollen, golven, soort, metervloeistoffen, en slikken
- Ongekend:zakenman uit Dallas voltooit diepste oceaanduik ooit door een mens ooit
- Hoe medestudenten je eigen cijfers verbeteren
- Stralend licht op tweedimensionale magneten
- Hoe het afstoten van fossiele brandstoffen de planeet kan helpen redden
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
