Wetenschap
Studenten helpen NASA aardverschuivingen te vinden door computers te trainen om Reddit te lezen
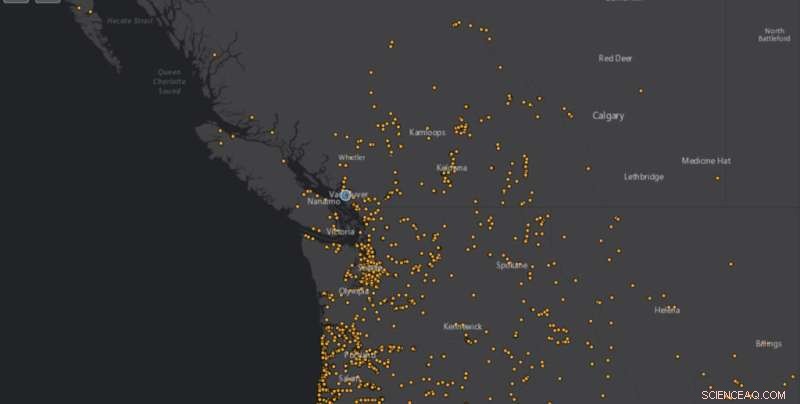
Volgens de Wereldgezondheidsorganisatie zijn aardverschuivingen meer wijdverbreid dan enige andere geologische gebeurtenis. Krediet:NASA
Afgestudeerde studenten van de University of British Columbia hebben computers getraind om nieuwsartikelen over aardverschuivingen op Reddit te "lezen" om een NASA-database te versterken, wat de voorspellingen zou kunnen verbeteren van wanneer en waar deze natuurrampen zullen plaatsvinden.
Voor hun Master of Data Science in Computational Linguistics sluitstukproject hebben Badr Jaidi en zijn team, de Social Landslides-groep, computers getraind om automatisch nuttige informatie te extraheren uit relevante nieuwsartikelen over aardverschuivingen die op Reddit zijn geplaatst. In deze Q&A bespreekt hij hoe deze tool levens kan redden.
Waarom hebben we deze tool nodig?
Volgens de Wereldgezondheidsorganisatie zijn aardverschuivingen meer wijdverbreid dan enige andere geologische gebeurtenis. Ze zijn zo destructief en we hebben niet zoveel gegevens over hen. Hoe nauwkeuriger aardverschuivingsgegevens u heeft, hoe beter het mogelijk is om nauwkeurig te voorspellen op welke plaatsen een hoger risico bestaat, wat uiteindelijk levens kan redden.
NASA verzamelt dergelijke informatie in een openbare database genaamd de Cooperative Open Online Repository, of COOLR, en gebruikt deze om te voorspellen wanneer en waar aardverschuivingen zullen plaatsvinden. Maar mensen moesten handmatig aardverschuivingsinformatie indienen of één voor één naar nieuwsartikelen en gegevens zoeken, wat behoorlijk vervelend is. Onze tool automatiseert dat proces en voltooit in enkele minuten wat voorheen maanden kon duren.
Dat zou middelen vrijmaken voor belangrijker onderzoek, en zou ook betekenen dat we meer gegevens, sneller, mogelijk beter onderzoek naar aardverschuivingen in het algemeen krijgen, evenals NASA's aardverschuivingsvoorspellingen.
Hoe werkt het?
Geleid door BGC Engineering Inc. en NASA voor ons sluitstukproject, heeft ons team een tool ontworpen die Reddit scant op nieuwsartikelen over aardverschuivingen binnen een bepaalde periode en vervolgens relevante informatie extraheert.
Eerst komt een computermodel erachter of het artikel inderdaad gaat over aardverschuivingen, in plaats van over een verkiezing waarbij iemand "door een aardverschuiving" wint, of, zoals we ook ontdekten, over artikelen over Pokémon met aardetechnieken zoals "rotsverschuiving".
Vervolgens hebben we een model voor natuurlijke taalverwerking getraind op aardverschuivingsgegevens, waarbij we het leerden om de informatie te herkennen die we van een artikel wilden. Dit soort model kan taal begrijpen, inclusief het analyseren van zinnen. Dus we zouden het een nieuwsartikel geven en vragen waar een aardverschuiving zou kunnen zijn gebeurd. Het model zou het antwoord voorspellen op basis van de betreffende taal, bijvoorbeeld "De aardverschuiving is hier hoogstwaarschijnlijk gebeurd, volgens deze zin", en we zouden het laten weten of het correct was of niet.
Op deze manier leert de computer welke informatie automatisch en nauwkeurig moet worden geëxtraheerd, inclusief wanneer een aardverschuiving heeft plaatsgevonden en waar, waardoor deze is ontstaan en hoeveel dodelijke slachtoffers daarbij zijn gevallen.
Dit gebeurt allemaal vrij snel:het geeft een maand aan artikelen terug in ongeveer 15 minuten, vergeleken met het handmatig doornemen om die stukjes informatie te vinden. De gegevens kunnen vervolgens in COOLR worden ingevoerd. Dit kostte ons ongeveer twee maanden om te bouwen. NASA beoordeelt momenteel of de tool kan worden uitgevoerd zoals hij is of dat er enkele aanpassingen nodig zijn om te gebruiken.
Kan de tool ook op andere sociale-mediasites worden gebruikt?
We hebben Reddit gebruikt omdat het gratis is om toegang te krijgen tot hun Application Programming Interface (API). De API van Twitter heeft bijvoorbeeld veel beperkingen en is vrij duur om toegang te krijgen. Ook zou de hoeveelheid gegevens enorm zijn.
We wilden klein beginnen en bewijzen dat het werkt met Reddit. Maar het kan worden uitgebreid naar grotere platforms en bronnen, op voorwaarde dat ze nieuwsartikelen hebben. Je zou de tool zelfs kunnen uitbreiden om hem te gebruiken voor andere rampen, zoals aardbevingen, door dezelfde methodologie te gebruiken door de modellen te trainen met vergelijkbare datasets.
Verbetering van het model en het toevoegen van meer bronnen waaruit aardverschuivingen kunnen worden geëxtraheerd, behalve Reddit, zou NASA uiteindelijk helpen om sneller meer datapunten te hebben. Ik zal het in de gaten houden. + Verder verkennen
Onderzoekers verbeteren internationale nomenclatuur van aardverschuivingsgeometrie
 AI gebruiken om mariene omgevingen in kaart te brengen
AI gebruiken om mariene omgevingen in kaart te brengen- Onderzoekers ontdekken een ijstijd in de Afrikaanse woestijn
- Soedanese hoop dat Ethiopische dam een einde maakt aan overstromingen van de Blauwe Nijl
- 5 dingen die je niet wist over Paleoart
- Een frisse kijk op zoet water - onderzoekers creëren een 50, 000-meren-database
Hoofdlijnen
- Winden van zorg:Amerikaanse vissers zijn bang voor bossen met krachtturbines
- Gevaren van het inademen van olierook
- Designer biosensor kan de productie van antibiotica door microben detecteren
- Wetenschappers identificeren nieuwe gastheren voor vectoren van de ziekte van Chagas
- De functie van macromoleculen
- De genetica van schijfziekte bij honden ontrafelen
- Ecologen gebruiken de nieuwste tandheelkundige scantechnologie om jong koraal te bestuderen
- Wat is de evolutionaire betekenis van de genetische codes bij Universaliteit?
- Wat zijn de verschillen tussen PCR en klonen?
- Een benadering om vraagbeantwoordingsmodellen (QA) te verbeteren
- New York verliest aanbieder van rideshare als Juno stopt

- New York Times passeert binnenkort 4 miljoen abonnees

- Ingenieurs creëren oplossing voor goedkopere, batterijpakketten met een langere levensduur

- Onderzoekers leggen kwetsbaarheden van wachtwoordmanagers bloot

 Avonturen in akoestische kosmologie
Avonturen in akoestische kosmologie- Onderzoek suggereert dat het smelten van Arctische permafrost enorme hoeveelheden lachgas kan vrijgeven
- Hoe partijpolitiek een hap uit je portemonnee kan nemen
- Meubels verplaatsen in de microwereld
- NASA's nieuwe vormveranderende radiator geïnspireerd op origami
- Aardbeving biedt nieuwe kansen voor onderzoek, Directeur geologisch onderzoek Idaho zegt:
- Knipperen zorgt voor moeilijk te verkrijgen 2D boornitride
- Berekening van een planeten Revolutie om de zon
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
