Wetenschap
Een benadering om vraagbeantwoordingsmodellen (QA) te verbeteren
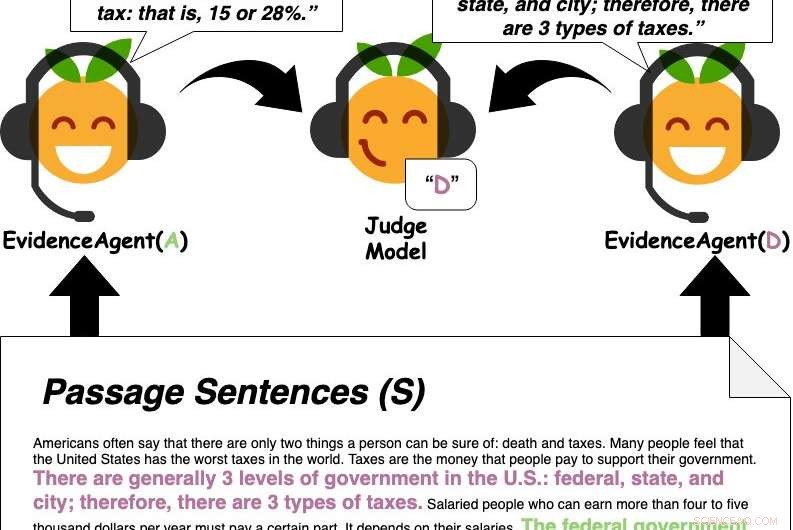
Bewijsagenten citeren zinnen uit de passage om een vraagbeantwoordend rechtermodel van een antwoord te overtuigen. Krediet:Perez et al.
Om het juiste antwoord op een vraag te vinden, moeten vaak grote hoeveelheden informatie worden verzameld en complexe ideeën worden begrepen. In een recente studie, een team van onderzoekers van de New York University (NYU) en Facebook AI Research (FAIR) onderzocht de mogelijkheid om automatisch de onderliggende eigenschappen van problemen, zoals het beantwoorden van vragen, bloot te leggen door te onderzoeken hoe machine learning-modellen verwante taken leren oplossen.
In hun krant voorgepubliceerd op arXiv en zal worden gepresenteerd op EMNLP 2019, ze introduceerden een aanpak om het sterkste ondersteunende bewijs voor een gegeven antwoord op een vraag te verzamelen. Ze pasten deze methode specifiek toe op taken waarbij op passages gebaseerde vragen beantwoorden (QA), wat inhoudt dat je grote hoeveelheden tekst moet analyseren om het beste antwoord op een bepaalde vraag te vinden.
"Als we een vraag stellen, we zijn vaak niet alleen geïnteresseerd in het antwoord, maar ook in waarom dat antwoord correct is - welk bewijs ondersteunt dat antwoord, "Ethan Perez, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Helaas, het vinden van bewijs kan tijdrovend zijn als het veel artikelen moet lezen, onderzoeks papieren, enz. Ons doel was om machine learning te gebruiken om automatisch bewijs te vinden."
Eerst, Perez en zijn collega's hebben een QA-machine learning-model getraind dat is ontworpen om gebruikersvragen te beantwoorden op een grote database met tekst met nieuwsartikelen, biografieën, boeken en andere online inhoud. Vervolgens, ze gebruikten "evidence agents" om zinnen te identificeren die het machine-learningmodel zouden "overtuigen" om op een bepaalde vraag te reageren met een specifiek antwoord, in wezen bewijs verzamelen voor het antwoord.

Krediet:Perez et al.
"Ons systeem kan bewijs vinden voor elk antwoord - niet alleen het antwoord dat volgens het Q&A-model correct is, als eerder werk gericht op, "Zei Perez. "Dus, onze aanpak kan een Q&A-model gebruiken om nuttig bewijs te vinden, zelfs als het Q&A-model het verkeerde antwoord voorspelt of als er geen duidelijk goed antwoord is."
In hun testen, Perez en zijn collega's merkten op dat modellen voor machinaal leren doorgaans bewijs uit tekstpassages selecteren dat goed generaliseert bij het overtuigen van andere modellen en zelfs mensen. Met andere woorden, hun bevindingen suggereren dat modellen oordelen vellen op basis van soortgelijk bewijs als dat doorgaans door mensen wordt overwogen, en tot op zekere hoogte, het is zelfs mogelijk om te onderzoeken hoe mensen denken door te beïnvloeden hoe modellen bewijs beschouwen.
De onderzoekers ontdekten ook dat nauwkeurigere QA-modellen meestal beter ondersteunend bewijs vinden, althans volgens een groep menselijke deelnemers die ze interviewden. De prestaties en mogelijkheden van machine learning-modellen kunnen daarom sterk worden geassocieerd met hun effectiviteit bij het verzamelen van bewijs om hun voorspellingen te ondersteunen.
-

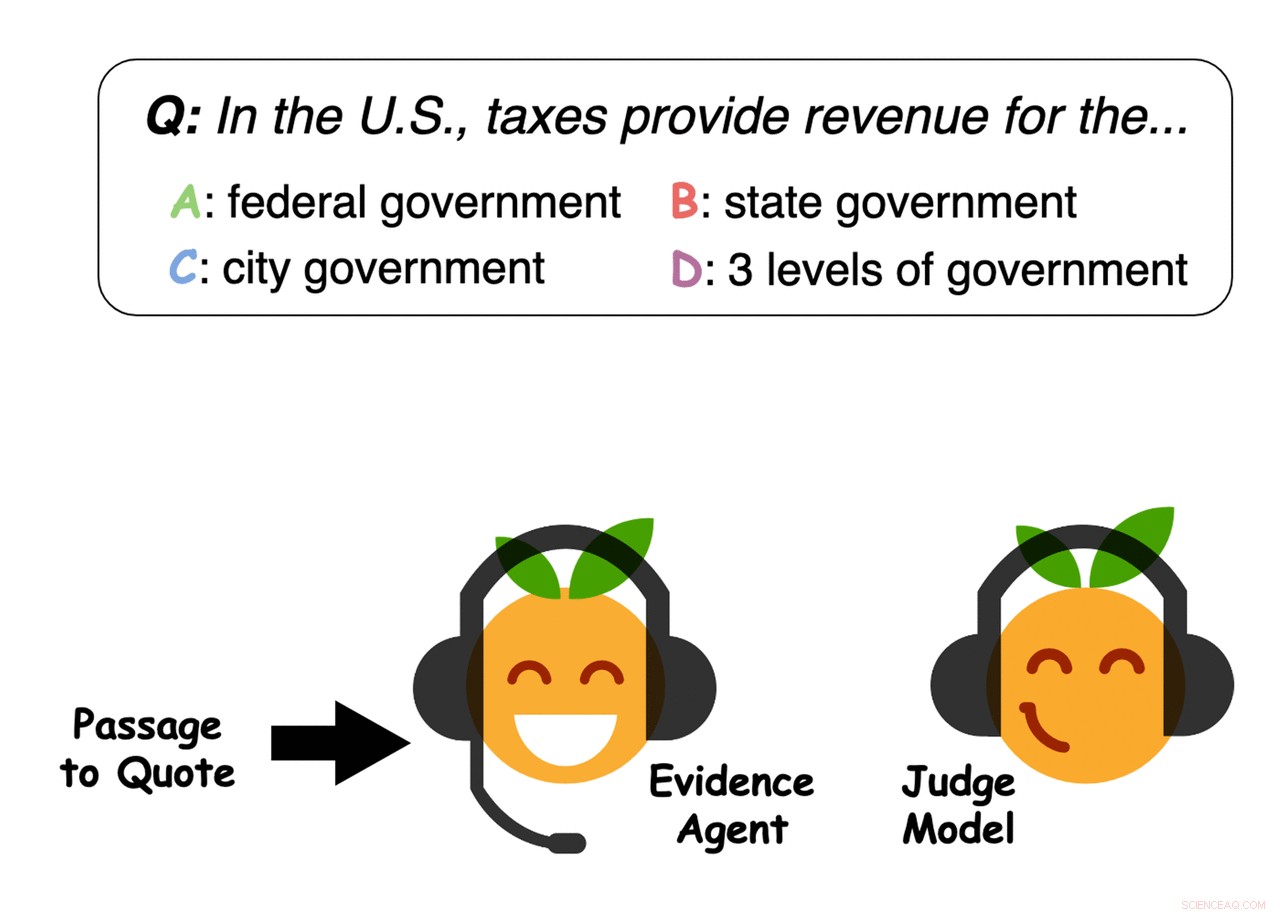
Voorbeeld van bewijs geselecteerd door de agenten. Krediet:Perez et al.
-
Krediet:Perez et al.
-

Voorbeeld van bewijs geselecteerd door de agenten. Krediet:Perez et al.
-
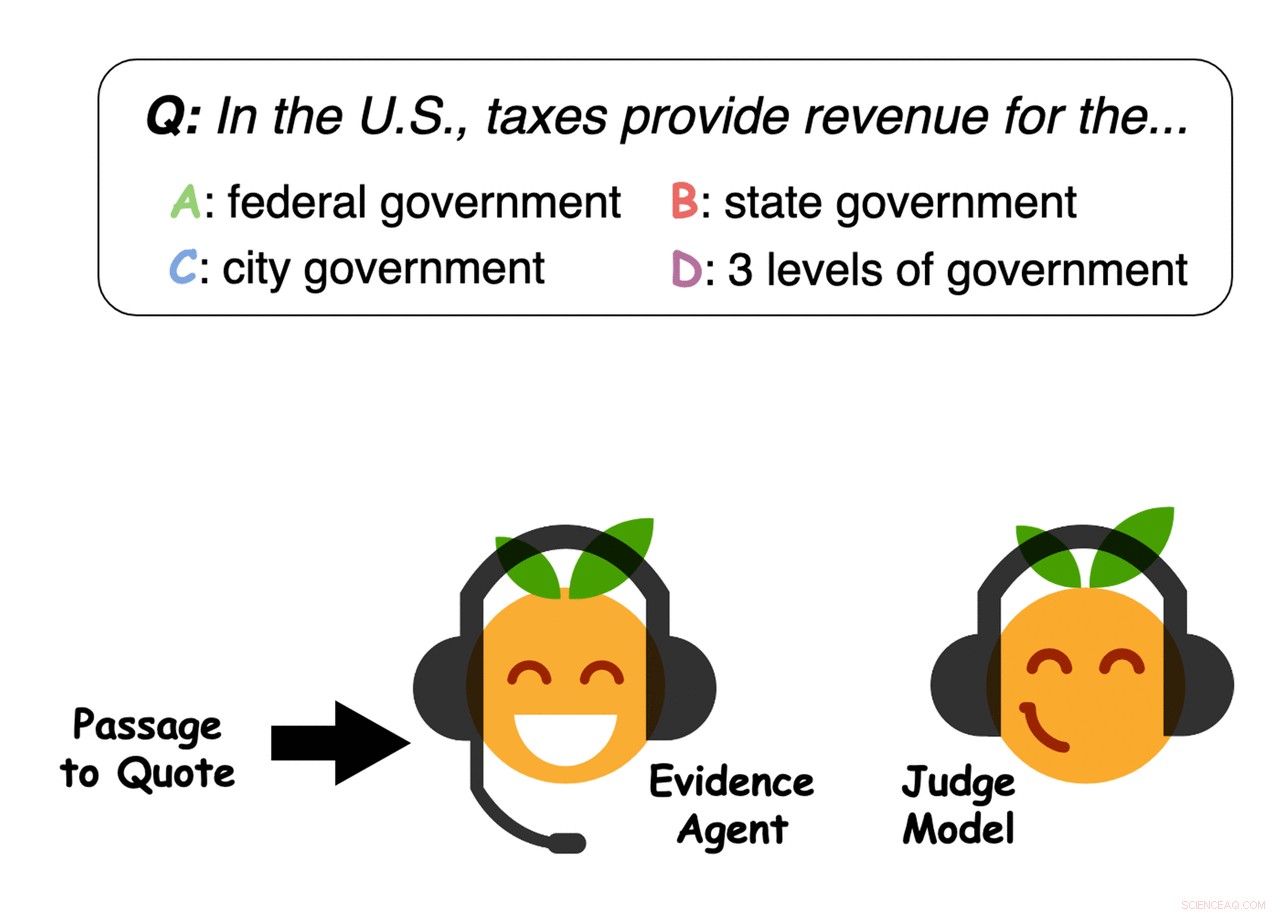
Bewijsagenten citeren zinnen uit de passage om een vraagbeantwoordend rechtermodel van een antwoord te overtuigen. Krediet:Perez et al.
"Vanuit praktisch oogpunt bewijs vinden is nuttig, "Zei Perez. "Mensen kunnen vragen over lange artikelen beantwoorden door het bewijs van ons systeem voor elk mogelijk antwoord te lezen. Daarom, in het algemeen, door automatisch bewijs te vinden, een systeem als het onze kan mensen mogelijk helpen sneller geïnformeerde meningen te ontwikkelen."
Perez en zijn collega's ontdekten dat hun benadering van het verzamelen van bewijs het beantwoorden van vragen aanzienlijk verbeterde, mensen in staat stellen om vragen correct te beantwoorden op basis van ongeveer 20 procent van een tekstpassage, die is geselecteerd door een machine learning-agent. In aanvulling, hun aanpak stelde QA-modellen in staat om antwoorden op vragen effectiever te identificeren, beter generaliseren naar langere passages en moeilijkere vragen.
In de toekomst, de aanpak die door dit team van onderzoekers is bedacht en de observaties die ze hebben verzameld, zouden kunnen bijdragen aan de ontwikkeling van effectievere en betrouwbaardere QA-machine learning-tools. Recenter, Perez schreef ook een blogpost op Medium waarin de ideeën die in de paper worden gepresenteerd meer diepgaand worden uitgelegd.
"Het vinden van bewijs is een eerste stap naar modellen die debatteren, Perez zei. "Vergeleken met het vinden van bewijs, debat is een nog expressievere manier om een standpunt te ondersteunen. Debatteren vereist niet alleen het citeren van extern bewijs, maar ook het construeren van uw eigen argumenten - het genereren van nieuwe tekst. Ik ben geïnteresseerd in het trainen van modellen om nieuwe argumenten te genereren, terwijl u ervoor zorgt dat de gegenereerde tekst waar en feitelijk correct is."
© 2019 Wetenschap X Netwerk
 Define Chemical Pollution
Define Chemical Pollution- Uit onderzoek blijkt dat geen grondbewerking alleen niet voldoende is om watervervuiling door nitraat te voorkomen
- Sommige droogteperiodes tijdens de Indiase moesson zijn te wijten aan unieke verstoringen in de Noord-Atlantische Oceaan
- NASA's AIRS-beelden Tropische storm Barry voor aanlanding
- Het klimaatlevensverhaal van de aarde, 3 miljard jaar in de maak
Hoofdlijnen
- Het belang van wetenschappelijke namen voor organismen
- Waarom zijn botten belangrijk voor het lichaam?
- Het grote structurele voordeel Eukaryoten hebben over prokaryoten
- Het simuleren van seks met walvisachtigen met kadaverdelen biedt inzicht in mariene copulatie
- Hoe vogelgriep werkt
- Nucleic Acid Facts
- Onverwachte bevinding in de energiecentrale van cellen
- Welke soorten moleculen kunnen door het plasmamembraan passeren via eenvoudige diffusie?
- Graslandmussen constant op zoek naar een mooier huis
- Zuckerberg wijst verzoek om voor het Britse parlement te verschijnen af

- Hoe Facebook-advertenties u targeten

- Onderzoekers gebruiken gerecyclede koolstofvezel om doorlatende bestrating te verbeteren

- In een handelsoorlog, luchtvaartgigant Boeing kan een zittende eend zijn

- Facebook verwerpt Australische media-oproepen voor regulering


 Stellair lijk onthult aanwijzingen voor vermist sterrenstof
Stellair lijk onthult aanwijzingen voor vermist sterrenstof- Wetenschappers ontwikkelen gesynchroniseerde moleculaire motoren
- Kubieke ruimte berekenen
- Materiaalwetenschappers aansturen op betere geheugenapparaten
- Nanotechnologie dringt door in de bouwsector
- Op het spoor van oorzaken van stralingsgebeurtenissen tijdens ruimtevlucht
- Sterrenkraamkamers in de Melkweg in kaart brengen
- Australië kan execs van sociale media opsluiten voor het tonen van geweld
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
