Wetenschap
AI-leertechniek kan de functie van beloningspaden in de hersenen illustreren

Wanneer de toekomst onzeker is, toekomstige beloning kan worden weergegeven als een kansverdeling. sommige mogelijke toekomsten zijn goed (blauwgroen), anderen zijn slecht (rood). Verdelingsversterkingsleren kan leren over deze verdeling over voorspelde beloningen via een variant van het TD-algoritme. Credit: Natuur (2020). DOI:10.1038/s41586-019-1924-6
Een team van onderzoekers van DeepMind, University College en Harvard University hebben ontdekt dat lessen die zijn geleerd bij het toepassen van leertechnieken op AI-systemen, kunnen helpen verklaren hoe beloningsroutes in de hersenen werken. In hun artikel gepubliceerd in het tijdschrift Natuur , de groep beschrijft het vergelijken van het leren van distributieversterking in een computer met de verwerking van dopamine in het muizenbrein, en wat ze ervan geleerd hebben.
Voorafgaand onderzoek heeft aangetoond dat dopamine dat in de hersenen wordt geproduceerd, betrokken is bij de verwerking van beloningen - het wordt geproduceerd wanneer er iets goeds gebeurt, en de uitdrukking ervan resulteert in gevoelens van plezier. Sommige onderzoeken hebben ook gesuggereerd dat de neuronen in de hersenen die reageren op de aanwezigheid van dopamine allemaal op dezelfde manier reageren:een gebeurtenis zorgt ervoor dat een persoon of een muis zich goed of slecht voelt. Andere studies hebben gesuggereerd dat de neuronale respons meer een gradiënt is. In deze nieuwe poging de onderzoekers hebben bewijs gevonden dat de laatste theorie ondersteunt.
Distributioneel versterkend leren is een vorm van machine learning op basis van versterking. Het wordt vaak gebruikt bij het ontwerpen van games zoals Starcraft II of Go. Het houdt goede zetten versus slechte zetten bij en leert het aantal slechte zetten te verminderen, het verbeteren van de prestaties naarmate het meer speelt. Maar dergelijke systemen behandelen niet alle goede en slechte zetten hetzelfde - elke zet wordt gewogen zoals deze wordt geregistreerd en de gewichten maken deel uit van de berekeningen die worden gebruikt bij het maken van toekomstige zetkeuzes.
Onderzoekers hebben opgemerkt dat mensen een vergelijkbare strategie lijken te gebruiken om hun spelniveau te verbeteren, ook. De onderzoekers in Londen vermoedden dat de overeenkomsten tussen de AI-systemen en de manier waarop de hersenen beloningsverwerking uitvoeren waarschijnlijk vergelijkbaar waren, ook. Om erachter te komen of ze juist waren, ze deden experimenten met muizen. Ze plaatsten apparaten in hun hersenen die in staat waren om reacties van individuele dopamine-neuronen te registreren. De muizen werden vervolgens getraind om een taak uit te voeren waarbij ze beloningen ontvingen voor het reageren op een gewenste manier.
Uit de reacties van muisneuronen bleek dat ze niet allemaal op dezelfde manier reageerden, zoals eerdere theorie had voorspeld. In plaats daarvan, ze reageerden op betrouwbare verschillende manieren - een indicatie dat de niveaus van plezier die de muizen ervoeren meer een gradiënt waren, zoals het team had voorspeld.
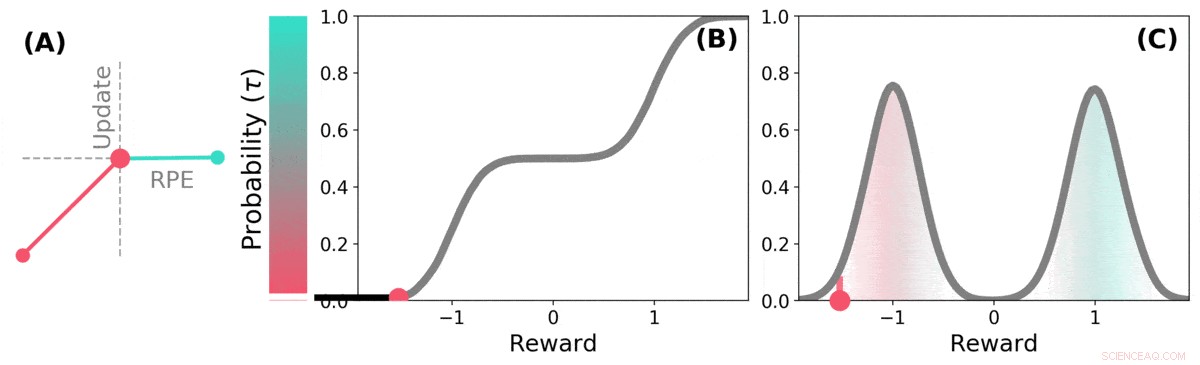
Distributional TD leert waardeschattingen voor veel verschillende delen van de distributie van beloningen. welk deel een bepaalde schatting bestrijkt, wordt bepaald door het type asymmetrische update dat op die schatting wordt toegepast. (a) Een 'pessimistische' cel zou negatieve updates versterken en positieve updates negeren, een 'optimistische' cel zou positieve updates versterken en negatieve updates negeren. (b) Dit resulteert in een diversiteit aan pessimistische of optimistische waardeschattingen, hier weergegeven als punten langs de cumulatieve verdeling van beloningen, die vastleggen (c) De volledige verdeling van beloningen. Credit: Natuur (2020). DOI:10.1038/s41586-019-1924-6
© 2020 Wetenschap X Netwerk
 Displays maken met rijkere kleuren
Displays maken met rijkere kleuren- Nieuw boormateriaal met hoge hardheid gecreëerd door chemische dampafzetting in plasma
- Gouden microjuwelen uit de 3D-printer
- Het in kaart brengen van de driedimensionale structuur van katalytische centra helpt bij het ontwerpen van nieuwe en verbeterde katalysatoren
- Chemische datamining stimuleert zoektocht naar nieuwe organische halfgeleiders
Hoofdlijnen
- Wat gebeurt er met een dierlijke cel in een hypotone oplossing?
- Mieren offeren hun koloniegenoten op als onderdeel van een dodelijke desinfectie
- Wat is het voordeel van het feit dat het DNA goed is ingepakt in de chromosomen?
- Hoe nauwkeurig is ons mentale beeld van onszelf?
- Onderzoek verduidelijkt de functie van de nucleaire hormoonreceptor in planten
- Geowetenschappers vergelijken micro-organismen in de poolgebieden
- Een sleutel vinden om geblokkeerde differentiatie in microRNA-deficiënte embryonale stamcellen te ontgrendelen
- Ademhaling bij zoogdieren
- Openbare bronnen stimuleren de ontdekking van medicijnen en bieden inzicht in de eiwitfunctie
- Krantenketen GateHouse koopt Gannett, USA Today eigenaar

- Siemens deelt duikvlucht over revisieplan, energie ellende

- Dynamische stalling bij hoge snelheden begrijpen

- Verdient kunstmatige intelligentie dezelfde ethische bescherming die we aan dieren geven?

- Uber neemt woon-werkverkeer over met Express carpoolservice


 Amerikaanse stromen bevatten een verrassend uitgebreid mengsel van verontreinigende stoffen
Amerikaanse stromen bevatten een verrassend uitgebreid mengsel van verontreinigende stoffen- Hoe Pi werkt
- Koolstofvastlegging in oceanen aangedreven door fragmentatie van grote organische deeltjes
- Stoutmoedig groeien:Japanse astronaut bezorgd over groeispurt in de ruimte
- Makerspaces kunnen een brede acceptatie van microfluïdica mogelijk maken
- Een nieuwe perovskiet kan leiden tot de volgende generatie gegevensopslag
- Onderzoekers meten temperatuur op nanometerschaal
- Nieuw efficiënt kwantumalgoritme overtreft de Quantum Phase Estimation-norm
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Swedish | Dutch | Danish | Norway | Spanish | Portuguese | German |

-
Wetenschap © https://nl.scienceaq.com
