Wetenschap
Spraakherkenning met behulp van kunstmatige neurale netwerken en optimalisatie van kunstmatige bijenkolonies
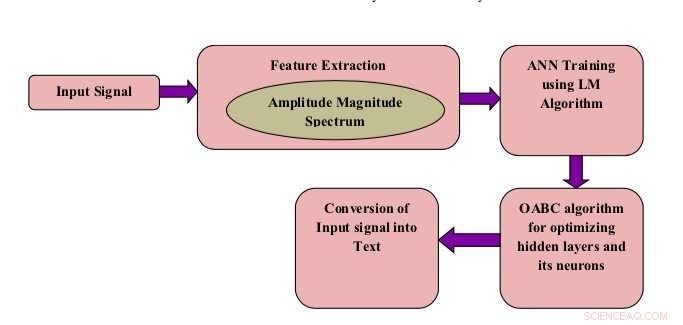
Blokschema van het voorgestelde model. Krediet:Shukla &Jain.
In de afgelopen tien jaar of zo, vooruitgang in machine learning heeft de weg vrijgemaakt voor de ontwikkeling van steeds geavanceerdere spraakherkenningstools. Door audiobestanden van menselijke spraak te analyseren, deze tools kunnen woorden en zinnen in verschillende talen leren herkennen, omzetten in een machineleesbaar formaat.
Hoewel verschillende op machine learning gebaseerde modellen veelbelovende resultaten hebben opgeleverd voor spraakherkenningstaken, ze presteren niet altijd goed in alle talen. Bijvoorbeeld, wanneer een taal een woordenschat heeft met veel gelijkaardige klinkende woorden, de prestaties van spraakherkenningssystemen kunnen aanzienlijk afnemen.
Onderzoekers van Mahatma Gandhi Mission's College of Engineering &Technology en Jaypee Institute of Information Technology, in India, hebben een spraakherkenningssysteem ontwikkeld om dit probleem aan te pakken. Dit nieuwe systeem, gepresenteerd in een paper gepubliceerd in Springer Link's Internationaal tijdschrift voor spraaktechnologie , combineert een kunstmatig neuraal netwerk (ANN) met een optimalisatietechniek die bekend staat als oppositionele kunstmatige bijenkolonie (OABC).
"In dit werk, de standaardstructuur van ANN's is opnieuw ontworpen met behulp van het Levenberg-Marquardt-algoritme om een optimale voorspellingssnelheid met nauwkeurigheid te verkrijgen, " schreven de onderzoekers in hun paper. "De verborgen lagen en neuronen van de verborgen lagen worden verder geoptimaliseerd met behulp van de kunstmatige oppositie-optimalisatietechniek voor bijenkolonies."
Een uniek kenmerk van het door de onderzoekers ontwikkelde systeem is dat het een OABC-optimalisatiealgoritme gebruikt om de ANN-lagen en kunstmatige neuronen te optimaliseren. Zoals de naam doet vermoeden, kunstmatige bijenkolonie (ABC) algoritmen zijn ontworpen om het gedrag van honingbijen te simuleren om een verscheidenheid aan optimalisatieproblemen aan te pakken.
"Over het algemeen, optimalisatie-algoritmen initialiseren willekeurig de oplossingen in het overeenkomende domein, " legden de onderzoekers uit in hun paper. "Maar deze oplossing zou in de tegenovergestelde richting van de beste oplossing kunnen liggen, waardoor de computationele overhead aanzienlijk wordt verhoogd. Vandaar dat deze op oppositie gebaseerde initialisatie OABC wordt genoemd."
Het door de onderzoekers ontwikkelde systeem beschouwt individuele woorden die door verschillende mensen worden gesproken als een ingangsspraaksignaal. Vervolgens, het extraheert zogenaamde amplitudemodulatie (AM) spectrogramkenmerken, die in wezen geluidsspecifieke kenmerken zijn.
De functies die door het model worden geëxtraheerd, worden vervolgens gebruikt om de ANN te trainen om menselijke spraak te herkennen. Nadat het is getraind op een grote database met audiobestanden, de ANN leert geïsoleerde woorden te voorspellen in nieuwe voorbeelden van menselijke spraak.
De onderzoekers testten hun systeem op een reeks menselijke spraakaudioclips en vergeleken het met meer conventionele spraakherkenningstechnieken. Hun techniek presteerde beter dan alle andere methoden, het behalen van opmerkelijke nauwkeurigheidsscores.
"De gevoeligheid, specificiteit, en nauwkeurigheid van de voorgestelde methode zijn 90,41 procent, 99,66 procent en 99,36 procent, respectievelijk, die beter is dan alle bestaande methoden, ’ schreven de onderzoekers in hun paper.
In de toekomst, het spraakherkenningssysteem zou kunnen worden gebruikt om effectievere communicatie tussen mens en machine te bereiken in verschillende omgevingen. In aanvulling, de aanpak die ze gebruikten om het systeem te ontwikkelen, zou andere teams kunnen inspireren om vergelijkbare modellen te ontwerpen, die ANN's en OABC-optimalisatietechnieken combineren.
© 2019 Wetenschap X Netwerk

Hoofdlijnen
- Onthulling van essentiële enzymen voor plantengroei tijdens stikstofgebrek
- Onderzoeker ontdekt dat wanneer sperma concurreert, eieren hebben een keuze
- Hoe vergelijk ik Frankenstein & Cloning?
- Antibiotica kunnen het vermogen van immuuncellen om bacteriën te doden verminderen
- Waar vindt ademhaling plaats?
- Virus veroorzaakt meer dan 170 dolfijndoden in Brazilië
- Wat is de functie van tracking-kleurstof in gelelektroforese?
- Ideeën voor een Sunscreen Science Fair Project
- Fungus Vs. Mold
- Epidermale VR geeft technologie een menselijk tintje

- NY Times zwaait naar winst op abonnee, reclame winsten

- Onderzoekers ontwikkelen MEMS-versnellingsmeter met hogere gevoeligheid en verbeterde ruisonderdrukking
- Toyota verlaagt winstprognose voor het hele jaar waarschuwt voor Brexit

- GM:Trump-tarieven drijven kosten op


 Gigantische megalodonhaai eerder uitgestorven dan eerder werd gedacht
Gigantische megalodonhaai eerder uitgestorven dan eerder werd gedacht- Nieuw boek beschrijft manieren waarop onderzoekers hun afbeeldingen informatiever en aantrekkelijker kunnen maken
- Waterstofionen gebruiken om magnetisme op moleculaire schaal te manipuleren
- Bangladesh heeft duizenden levens gered van een verwoestende cycloon - dit is hoe
- Rusland brengt 38 buitenlandse satellieten in een baan om de aarde
- Methaanemissies detecteren tijdens COVID-19
- Persoonlijke veiligheid automatiseren met draagbare slimme sieraden
- Nanosensoren verbeteren de detectie van biomarkers voor ziekten in uitgeademde adem
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
