Wetenschap
Nieuwe modellen voor handschriftherkenning in online Latijnse en Arabische schriften
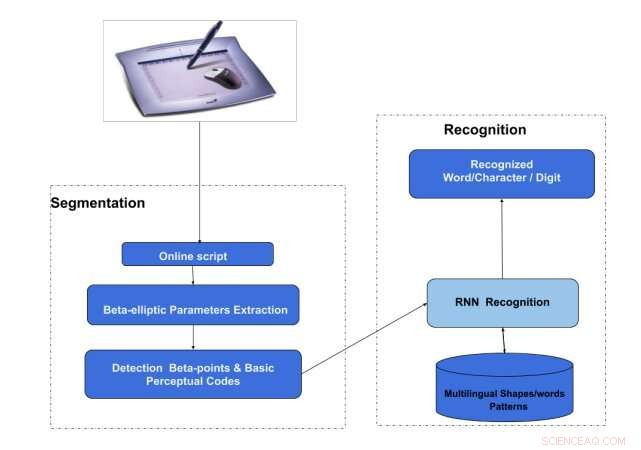
De architectuur van OnHS-LSTM. Krediet:Akouaydi et al.
Onderzoekers van de Universiteit van Sfax, in Tunesië, hebben onlangs een nieuwe methode ontwikkeld om handgeschreven karakters en symbolen in online scripts te herkennen. Hun techniek, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, heeft al opmerkelijke prestaties geleverd op teksten die zijn geschreven in zowel het Latijnse als het Arabische alfabet.
In recente jaren, onderzoekers hebben op neurale netwerken gebaseerde architecturen gemaakt die een verscheidenheid aan taken kunnen aanpakken, inclusief beeldclassificatie, gezichtsherkenning, natuurlijke taalverwerking (NLP), en nog veel meer. Handschriftherkenningssystemen zijn computerhulpmiddelen die speciaal zijn ontworpen om karakters en andere handgeschreven symbolen op een vergelijkbare manier als mensen te herkennen.
In hun eerste levensjaren in feite, mensen ontwikkelen van nature het vermogen om verschillende soorten handschrift te begrijpen door specifieke karakters te identificeren, zowel individueel als gegroepeerd. In de afgelopen tien jaar of zo, veel studies hebben geprobeerd dit vermogen te repliceren in computersystemen, omdat dit uiteindelijk meer geavanceerde en automatische analyses van handgeschreven teksten mogelijk zou maken.
"Onze paper behandelt het probleem van online handgeschreven scriptherkenning op basis van een extractiesysteem en een diepgaand benaderingssysteem voor sequentieclassificatie, ' schreven de onderzoekers in hun paper. 'We gebruikten een bestaande methode in combinatie met nieuwe classificaties om een flexibel systeem te krijgen.'
In hun krant de onderzoekers van de Universiteit van Sfax presenteren twee systemen op basis van diepe neurale netwerken:een online handschriftsegmentatie- en herkenningssysteem dat gebruik maakt van een lange-kortetermijngeheugennetwerk (OnHSR-LSTM) en een online handschriftherkenningssysteem dat bestaat uit een convolutionele lange korte term geheugen netwerk (OnHR-covLSTM).
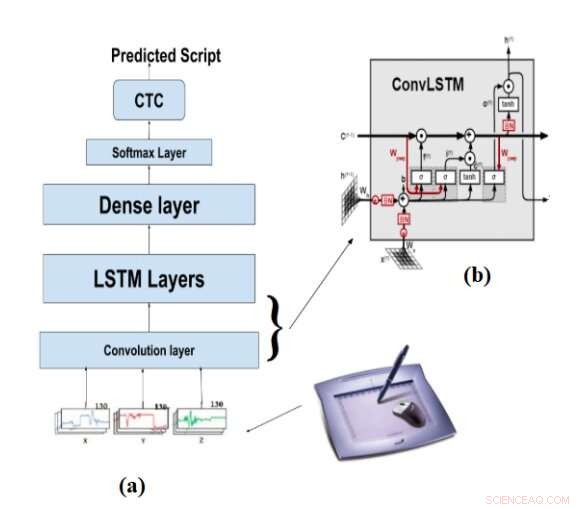
De architectuur van (a) OnHR-convLSTM, (b) de convLSTM-cel. Krediet:Akouaydi et al.
Hun eerste model, genaamd OnHSR-LSTM, is gebaseerd op een theorie die het menselijke perceptuele systeem beschrijft als een middel om taal te transformeren van grafische tekens in symbolische representaties. Het werkt door gemeenschappelijke eigenschappen van symbolen of tekens te detecteren en ze vervolgens te rangschikken volgens specifieke perceptuele wetten, bijvoorbeeld, gebaseerd op nabijheid, gelijkenis, enzovoort.
"Eindelijk, het [het model] probeert een representatie van de handgeschreven vorm te bouwen op basis van de veronderstelling dat de perceptie van vorm de identificatie is van basiskenmerken die zijn gerangschikt totdat we een object identificeren, " verklaarden de onderzoekers in hun paper. "Daarom, de weergave van handschrift is een combinatie van primitieve streken. Handschrift is een opeenvolging van basiscodes die zijn gegroepeerd om een teken of een vorm te definiëren."
De eerste door de onderzoekers voorgestelde techniek verdeelt in wezen een handgeschreven script in afzonderlijke elliptische streken met behulp van een model voor het genereren van handschrift. Vervolgens, deze slagen worden ingedeeld in primitieve codes, die door de neurale architectuur worden gebruikt om woorden in online handgeschreven scripts te herkennen.
Het tweede systeem voorgesteld door de onderzoekers, OpHR-convLSTM, is een generatief model dat het online signaal van een script als invoer gebruikt en is getraind om zowel karakters als woorden te voorspellen. Deze tweede techniek is met name handig voor het leren van reeksen (d.w.z. taken die de verwerking en classificatie van lange reeksen tekens en symbolen inhouden).
De onderzoekers trainden en evalueerden beide systemen met behulp van vijf verschillende databases met handgeschreven scripts in het Arabische en Latijnse alfabet. Hun tests leverden opmerkelijke resultaten op, waarbij beide systemen herkenningspercentages van meer dan 98 procent behaalden. interessant, de onderzoekers ontdekten dat de prestaties van beide technieken vergelijkbaar zijn met die welke typisch worden bereikt door mensen bij vergelijkbare taken.
"We zijn nu van plan om voort te bouwen op onze voorgestelde herkenningssystemen en deze te testen op een grootschalige database en andere scripts, ’ schreven de onderzoekers.
© 2019 Wetenschap X Netwerk
 Onderzoekers ontwikkelen oplosbare, gebruiksvriendelijke melkcapsules
Onderzoekers ontwikkelen oplosbare, gebruiksvriendelijke melkcapsules- Wetenschappers veranderen membraaneiwitten om ze gemakkelijker te bestuderen
- Wat is schadelijk voor de ozonlaag?
- Machine-learning onderzoek ontsluit energiebesparende moleculaire kooien
- Nieuwe benadering voorspelt het altijd evoluerende gedrag van glas bij verschillende temperaturen
Hoofdlijnen
- Baanbrekende ontdekking van een geurdetecterende receptorversterker
- Opnieuw klonen van de eerste gekloonde hond die tot nu toe als succesvol werd beschouwd
- Hoe tuinieren onder water de Atlantische Oceaan kan herstellen
- Niet zo koude eend? Man blijft zoeken naar uitgestorven vogel
- Doen eukaryote cellen door binaire fissie?
- Uit welke elementen bestaat glucose?
- Verrassing in de kangoeroe-stamboom - een buitenstaander is een naast familielid, ten slotte
- Onderzoekers ontdekken dat twee verschillende ecologische mechanismen veerkracht kunnen bieden tegen invasieve soorten
- Antibioticaresistentie:slapende bacteriën die medicamenteuze behandeling kunnen overleven geïdentificeerd
- Amerikaanse Senaat stemt om regels voor netneutraliteit te herstellen

- Beveiligingspersoneel volgen bij grootschalige evenementen

- Frankrijk, VS akkoord om gesprekken over digitale belasting te verlengen

- Door virus getroffen Air New Zealand bood reddingsoperatie van US $ 515 miljoen

- Tesla vermindert aantal voorraadkleuren om productie te stroomlijnen


 Hoe bouw je een Miniatuur Float School-project
Hoe bouw je een Miniatuur Float School-project- Milieuwetenschappers:tot 20% van de wereldwijde grondwaterbronnen dreigt op te drogen
- Bali vulkaanas drijft 7,7 mijl hoog, luchthaven gesloten 3e dag
- NASA-technologieën verminderen het vliegtuiggeluid aanzienlijk
- Nieuwe nanotechnologie zet warmte om in energie wanneer dat het meest nodig is
- Creativiteit bij onderzoekers stimuleren:hoe automatisering een revolutie teweeg kan brengen in materiaalonderzoek
- Ideeën voor een CO2 Car Project
- Onderzoekers combineren kwantumexpertise om onderzoek naar ultrakoude moleculen vooruit te helpen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | French | Italian |

-
Wetenschap © https://nl.scienceaq.com
