Wetenschap
Een bio-geïnspireerde benadering om het leren in ANN's te verbeteren
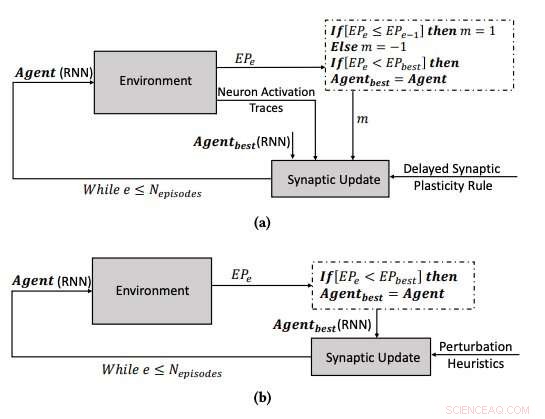
(a) Het leerproces met behulp van de vertraagde synaptische plasticiteit, en (b) het leerproces door de parameters van de RNN's te optimaliseren met behulp van het heuvelklimalgoritme. Krediet:Yaman et al.
Het menselijk brein verandert continu in de loop van de tijd, het vormen van nieuwe synaptische verbindingen op basis van ervaringen en informatie die gedurende een leven is geleerd. De afgelopen jaren is kunstmatige intelligentie (AI) onderzoekers hebben geprobeerd dit fascinerende vermogen te reproduceren, bekend als 'plasticiteit, ' in kunstmatige neurale netwerken (ANN's).
Onderzoekers van de Technische Universiteit Eindhoven (Tu/e) en de Universiteit van Trento hebben onlangs een nieuwe aanpak voorgesteld, geïnspireerd op biologische mechanismen die het leren in ANN's zouden kunnen verbeteren. hun studie, geschetst in een paper dat vooraf is gepubliceerd op arXiv, werd gefinancierd door het Horizon 2020 onderzoeks- en innovatieprogramma van de Europese Unie.
"Een van de fascinerende eigenschappen van biologische neurale netwerken (BNN's) is hun plasticiteit, waardoor ze kunnen leren door hun configuratie te veranderen op basis van ervaring, "Anil Yaman, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Volgens het huidige fysiologische begrip, deze veranderingen worden uitgevoerd op individuele synapsen op basis van de lokale interacties van neuronen. Echter, de opkomst van een coherent globaal leergedrag van deze individuele interacties is niet erg goed begrepen."
Geïnspireerd door de plasticiteit van BNN's en het evolutionaire proces, Yaman en zijn collega's wilden biologisch plausibele leermechanismen in kunstmatige systemen nabootsen. Om plasticiteit in ANN's te modelleren, onderzoekers gebruiken meestal iets dat Hebbian-leerregels heet, dat zijn regels die synapsen bijwerken op basis van neurale activeringen en versterkingssignalen die uit de omgeving worden ontvangen.

Verschillende onafhankelijke runs van de leerprocessen met behulp van verschillende geëvolueerde vertraagde synaptische plasticiteitsregels (de beste DSP-regel wordt groen weergegeven). Krediet:Yaman et al.
Wanneer versterkingssignalen niet direct na elke netwerkuitgang beschikbaar zijn, echter, sommige problemen kunnen zich voordoen, waardoor het voor het netwerk moeilijker wordt om de relevante neuronactivaties te associëren met het versterkingssignaal. Om dit probleem op te lossen, bekend als het 'distale beloningsprobleem, ' breidden de onderzoekers de Hebbian-plasticiteitsregels uit zodat ze leren in distale beloningsgevallen mogelijk zouden maken. Hun aanpak, genaamd vertraagde synaptische plasticiteit (DSP), gebruikt iets dat neuronactiveringssporen (NAT's) wordt genoemd om extra opslag in elke synaps te bieden, evenals om neuronactivaties bij te houden terwijl het netwerk een bepaalde taak uitvoert.
"Synaptische plasticiteitsregels zijn gebaseerd op de lokale activeringen van neuronen en een versterkingssignaal, " legde Yaman uit. "Echter, bij de meeste leerproblemen, de versterkingssignalen worden na een bepaalde tijdsperiode ontvangen in plaats van onmiddellijk na elke actie van het netwerk. In dit geval, het wordt problematisch om de versterkingssignalen te associëren met de activeringen van neuronen. In dit werk, stelden we voor gebruik te maken van wat we 'neuronactiveringssporen' noemden, ' om de statistieken van neuronactiveringen in elke synaps op te slaan en de synaptische plasticiteitsregels te informeren over het uitvoeren van vertraagde synaptische veranderingen."
Een van de meest betekenisvolle aspecten van de aanpak die door Yaman en zijn collega's is bedacht, is dat er geen globale informatie wordt verondersteld over het probleem dat het neurale netwerk zal oplossen. Verder, het is niet afhankelijk van de specifieke ANN-architectuur en is dus zeer generaliseerbaar.
"In praktische termen onze studie kan de basis leggen voor nieuwe leerschema's die kunnen worden gebruikt in een aantal neurale netwerktoepassingen, zoals robotica en autonome voertuigen, en in het algemeen in alle gevallen waarin een agent adaptief gedrag moet vertonen bij gebrek aan een onmiddellijke beloning die uit zijn acties wordt verkregen, " Giovanni Iaca, een andere onderzoeker die bij het onderzoek betrokken was, vertelde TechXplore. "Bijvoorbeeld, in AI voor videogamen, een actie in de huidige tijdstap hoeft op dit moment niet noodzakelijkerwijs tot een beloning te leiden, maar pas na enige tijd; een agent die gepersonaliseerde advertenties toont, kan pas na enige tijd een "beloning" krijgen van het gebruikersgedrag, enzovoort.)."
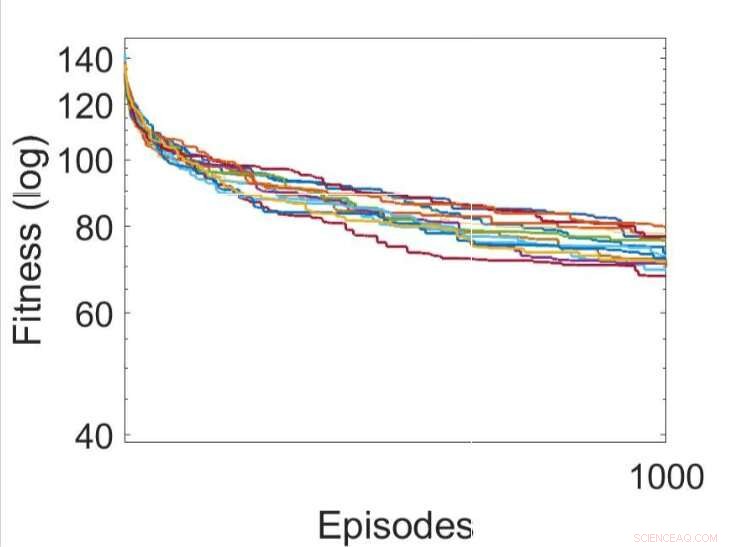
Verschillende onafhankelijke runs van de leerprocessen door de parameters van de RNN's te optimaliseren met behulp van het heuvelklimalgoritme. Krediet:Yaman et al.
De onderzoekers testten hun nieuw aangepaste Hebbian-plasticiteitsregels in een simulatie van een drievoudige T-doolhofomgeving. In deze omgeving, een agent die wordt bestuurd door een eenvoudig terugkerend neuraal netwerk (RNN) moet leren om één van de acht mogelijke doelposities te vinden, beginnend met een willekeurige netwerkconfiguratie.
Yaman, Iacca en hun collega's vergeleken de prestaties die werden behaald met hun aanpak met die bereikt wanneer een agent werd getraind met behulp van een analoog iteratief lokaal zoekalgoritme, heuvelklimmen (HC) genoemd. Het belangrijkste verschil tussen het HC-klimalgoritme en hun benadering is dat de eerste geen domeinkennis gebruikt (d.w.z. lokale activeringen van neuronen), terwijl de laatste dat wel doet.
De door de onderzoekers verzamelde resultaten suggereren dat de synaptische updates die door hun DSP-regels worden uitgevoerd, leiden tot effectievere training en uiteindelijk betere prestaties dan het HC-algoritme. In de toekomst, hun aanpak zou kunnen helpen om het langetermijnleren in ANN's te verbeteren, waardoor kunstmatige systemen effectief nieuwe verbindingen kunnen bouwen op basis van hun ervaringen.
"We zijn vooral geïnteresseerd in het begrijpen van het opkomende gedrag en de leerdynamiek van kunstmatige neurale netwerken, en het ontwikkelen van een coherent model om uit te leggen hoe synaptische plasticiteit optreedt in verschillende leerscenario's, " zei Yaman. "Ik denk dat er enorme mogelijkheden zijn voor toekomstig onderzoek op dit gebied, het zal bijvoorbeeld interessant zijn om de voorgestelde aanpak van grootschalige complexe problemen (evenals diepe netwerken) op te schalen en biologisch geïnspireerde leermechanismen te bereiken die de minste hoeveelheid supervisie vereisen (of helemaal geen)."
© 2019 Wetenschap X Netwerk
 Visslijm:een onaangeboorde bron van potentiële nieuwe antibiotica
Visslijm:een onaangeboorde bron van potentiële nieuwe antibiotica- Onderzoeksteam zet het vuur op 3D-printinkten
- Wetenschappers behalen nieuwe resultaten in de studie van anorganische pigmenten met apatietstructuur
- De voordelen van potentiometrische titratie
- Onderzoekers ontwikkelen ultrakrachtige plasmonische metaaloxidematerialen
- De belangrijkste biotische en abiotische componenten van het ecosysteem van het Great Barrier Reef
- Geen zaken in sneeuwzaken! Warm weer luiken Japanse skiresorts
- Stoffen die worden gebruikt in huishoudelijke artikelen tasten het immuunsysteem van een kustmossel aan
- Afbeelding:Faeröer zoals sen van Copernicus Sentinel-2
- Internationale SWOT-satelliet om 's werelds water te onderzoeken
Hoofdlijnen
- Voordelen van embryonale stamcelonderzoek
- Hoe cellen tellen met een microscoop
- Beperkingen van enzymen gebruikt in Forensic Science
- Onderzoek creëert een manier om varkens te beschermen tegen PRRS tijdens de voortplanting
- Waar vindt transcriptie plaats in een eukaryote cel?
- Soorten monomeren
- 10 geweldige dingen die de hersenen van mensen hebben gedaan
- Studie waarschuwt dat slangenschimmelziekte een wereldwijde bedreiging kan zijn
- Maaien of niet maaien:Overlastgroei van waterplanten bij de wortel aanpakken
- Wereldwijde luchtvaartmaatschappij waarschuwt voor protectionisme, stijgende kosten

- Hoe situatiebewustzijn je leven kan redden

- Internet-tv en mobiel video kijken dreigen de energiebehoefte te doen stijgen

- Amerikaanse toezichthouders onder vuur Boeing lanceert charmeoffensief

- Groeiende plutoniumvoorraad in Japan voedt angsten


 Waarom is de sabeltandtijger uitgestorven?
Waarom is de sabeltandtijger uitgestorven? - Een klimaat in crisis vraagt om investeringen in directe luchtafvang, nieuws onderzoek vindt
- China pronkt met geautomatiseerde artsen, leraren en gevechtssterren
- Hoe te om Hoeken & Kanten van een Driehoek te vinden
Veel wiskundeclasses en gestandaardiseerde tests, zoals ACT en SAT, vereisen dat u de hoeken en zijden van een driehoek vindt. Driehoeken kunnen worden gecategoriseerd als rechts (met een hoek va
- Waarom beïnvloedt suiker het vriespunt van water?
- Afbeelding:Plaats voor ruimtetesten
- Wat is het verschil tussen alkalinebatterijen en niet-alkalinebatterijen?
- Polen klaar om uitgebreide houtkap in ongerept oud bos te beëindigen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
