Wetenschap
Een op CNN gebaseerde methode voor wiskundig formulescript en type-identificatie
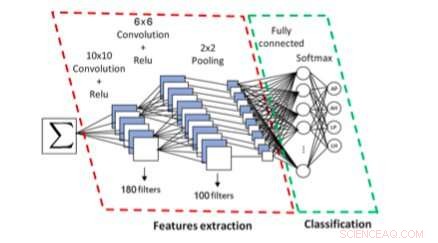
Het op CNN gebaseerde systeem voor symboolscript en type-identificatie. Krediet:Khazri &Echi.
Onderzoekers van de Universiteit van Tunis hebben onlangs een nieuw systeem voorgesteld voor het schrijven van wiskundige formules en type-identificatie, die is gebaseerd op convolutionele neurale netwerken (CNN's). hun methode, gepresenteerd in een paper gepubliceerd door Springer, kan automatisch onderscheid maken tussen gedrukte/handgeschreven en Arabische/Latijnse formules.
In recente jaren, onderzoekers hebben geprobeerd systemen te ontwikkelen die de vormen kunnen identificeren waarin een document wordt gepresenteerd, zoals de gebruikte taal en of de tekst machinaal gedrukt of met de hand geschreven is, om voor elk document het juiste herkenningssysteem te selecteren. De meeste van deze benaderingen zijn gericht op het identificeren van verschillende vormen van tekst, terwijl er maar heel weinig zijn ontworpen om wiskundige formules te analyseren.
"In deze context, presenteren we een nieuwe benadering die het probleem van de identificatie van het script aanpakt, Arabisch of Latijn; en de soort, handgeschreven of machinaal bedrukt, van wiskundige formules, ' schreven de onderzoekers van de Universiteit van Tunis in hun paper. 'Dit werk maakt deel uit van ons onderzoek naar offline herkenning van Arabische wiskundige formules.'
In hun studie hebben de onderzoekers presenteerden een syntaxisgericht systeem dat is ontworpen om symbolen te herkennen en hun rangschikking te analyseren. Om symbolen te herkennen, hun aanpak maakt gebruik van statistische kenmerken en een Bayes-netwerkclassificatie.
Om de structuur van een formule te analyseren, hun systeem maakt gebruik van een top-down en bottom-up parsing-schema op basis van dominantie van de operator. Met andere woorden, hun systeem voert een lexicale, geometrische en syntactische analyse van een formule, waarmee het zijn schrift kan identificeren (Latijn versus Arabisch) en of het handgeschreven of machinaal is getypt.
"Formule-parsing bestaat uit het toepassen, van de dominante operator en zijn context, de juiste regel om de formules in subformules te verdelen, die op dezelfde manier recursief worden geanalyseerd, " legden de onderzoekers uit in hun paper.
Met behulp van een CNN, de door de onderzoekers bedachte aanpak extraheert en classificeert vervolgens samenhangende componenten van een formule. De onderzoekers trainden en evalueerden hun systeem met behulp van Latijnse schriftformules uit de InftyMDB-1- en CROHME-databases, evenals Arabische formules gescand uit wiskundeboeken of handgeschreven door vijf verschillende schrijvers.
"Het voorgestelde herkenningssysteem is getest op complexe wiskundige formules die impliciete vermenigvuldiging bevatten, subscripts en superscripts, met bevredigende resultaten, " schreven de onderzoekers. "Meer functies toevoegen, het testen van andere algoritmen voor het selecteren van functies en het kiezen van snellere classificaties zou de prestaties van het voorgestelde systeem moeten verbeteren."
Algemeen, de door de onderzoekers uitgevoerde evaluaties leverden veelbelovende resultaten op, waarbij hun systeem een identificatiepercentage van 94,6 procent behaalde. De parser die ze gebruikten om de structuur van formules te analyseren, lijkt ook erg robuust, omdat het een indrukwekkend herkenningspercentage van 97,63 procent behaalde. In hun toekomstige werk, de onderzoekers zijn van plan de prestaties van hun systeem te verbeteren door de filters en architectuur van CNN verder te ontwikkelen.
© 2019 Wetenschap X Netwerk
 Onderzoekers pionieren op een groenere manier om verweven polymeren te maken met blauw licht
Onderzoekers pionieren op een groenere manier om verweven polymeren te maken met blauw licht- Zilveren en gouden nanodraden openen de weg naar betere elektrochrome apparaten
- Foto-initiatoren voor tandvullingen, contactlenzen en kunstgebitten
- Wat is hypertone oplossing?
- Een nieuwe methode voor de vorming van gefluoreerde moleculaire ringen
- Klimaatverandering, armoede en mensenrechten:een noodsituatie zonder precedent
- Zwaartekrachtgolven beïnvloeden weer en klimaat
- Zooplankton Vs. fytoplankton
- Onderzoekers ontwikkelen voorspellend model voor het meten van lachgasemissies in beken en rivieren
- Een model maken Shark Habitat in een Shoebox
Hoofdlijnen
- Welke soorten organische moleculen vormen een celmembraan?
- Links of rechts? Net als mensen, bijen hebben een voorkeur
- Genetische veranderingen helpen muggen om aanvallen van pesticiden te overleven
- Onderzoekers detecteren signalen van parasieten in mest van amfibieën
- Hoe werken het ademhalings- en cardiovasculaire systeem samen?
- Staan we op een kantelpunt met onkruidbestrijding?
- Studie onderzoekt de impact van leeuwen die naast giraffenpopulaties leven
- Ontdekking van gewasgenen raakt de wortel van voedselzekerheid
- Profase: wat gebeurt er in dit stadium van mitose en meiose?
- Snel, flexibele ionische transistors voor bio-elektronische apparaten

- Facebooks Mark Zuckerberg zegt dat het sociale netwerk politici niet mag censureren

- Review:Apples nieuwe iPad is de beste tablet voor bijna iedereen

- Harde CO2-doelstellingen kunnen 100 kosten, 000 banen:VW-chef

- FBI en Nigeria voeren onderzoek naar cybercriminaliteit op


 Wanneer coronavirus niet alleen is:team van complexiteitswetenschappers presenteert meme-model voor meerdere ziekten
Wanneer coronavirus niet alleen is:team van complexiteitswetenschappers presenteert meme-model voor meerdere ziekten- Organische moleculen op een metalen oppervlak... de beste vriend van een machinist
- De reis van een dodenmasker van de Duitse toneelschrijver Frank Wedekind
- Mogelijke verklaring voor de kosmische straling van de melkweg
- Aleksander Madry over het bouwen van betrouwbare kunstmatige intelligentie
- NASA's Webb-telescoop om te zoeken naar jonge bruine dwergen en schurkenplaneten
- Percentage nauwkeurigheid berekenen
- Extra politiebevoegdheden tijdens COVID-19 kunnen de relatie met het publiek voorgoed beïnvloeden
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Swedish | German | Dutch | Danish | Portuguese | Norway |

-
Wetenschap © https://nl.scienceaq.com
