Wetenschap
Een nieuwe benadering voor machinetransliteratie met weinig middelen met behulp van RNN's
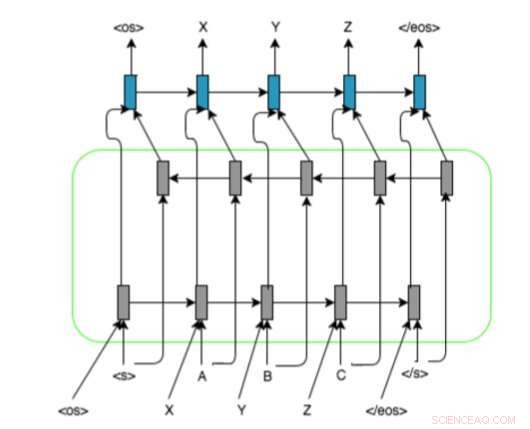
De RNN-gebaseerde modelarchitectuur van de onderzoekers met encoder-decoder bidirectionele LSTM en uitlijningsweergave op invoersequenties. Ze gebruiken en , en markeringen om de grafeem/foneemreeksen op een vaste lengte op te vullen. Krediet:Ngoc Tan Le et al.
Een team van onderzoekers van de Universite du Quebec a Montreal en Vietnam National University Ho Chi Minh (VNU-HCM) hebben onlangs een benadering ontwikkeld voor machinale transliteratie op basis van terugkerende neurale netwerken (RNN's). Transliteratie omvat de fonetische vertaling van woorden in een bepaalde brontaal (bijv. Frans) naar equivalente woorden in een doeltaal (bijv. Vietnamees).
Via transcriptie, een individueel woord wordt omgezet in een fonetisch equivalent woord in een ander schrift. Deze transformatie is meestal gebaseerd op een groot aantal regels die zijn gedefinieerd door taalkundigen, die bepalen hoe fonemen worden uitgelijnd, rekening houdend met de oorsprong van een woord en het fonologische systeem van de doeltaal.
In recente jaren, onderzoekers hebben verschillende deep learning-benaderingen voor machinevertaling ontwikkeld, die een waardevol alternatief zijn gebleken voor bestaande statistische benaderingen. Deze veelbelovende resultaten motiveerden het team van onderzoekers van de Universite du Quebec in Montreal en VNU-HCM om een diepgaande leerbenadering voor machinale transliteratie te ontwikkelen.
Hun aanpak maakt gebruik van terugkerende neurale netwerken (RNN's), omdat deze bijzonder nuttig zijn gebleken voor het omgaan met soortgelijke problemen. De onderzoekers merkten op dat de meeste state-of-the-art grafeem-naar-foneem-methoden voornamelijk waren gebaseerd op het gebruik van grafeem-foneem mappings, terwijl RNN's geen uitlijningsinformatie vereisen.
"Grafeem-naar-foneem-modellen zijn belangrijke componenten in automatische spraakherkenning en tekst-naar-spraaksystemen, " legden de onderzoekers in hun paper uit, die werd gepubliceerd op ACM Digital Library. "Met taalparen met weinig middelen die geen beschikbare en goed ontwikkelde uitspraaklexicons hebben, grafeem-naar-foneem-modellen zijn bijzonder nuttig. Deze modellen zijn gebaseerd op initiële afstemmingen tussen grafeembron- en foneemdoelsequenties."
In hun studie hebben de onderzoekers introduceerden een nieuwe methode om machinetransliteratie met weinig middelen te bereiken, die op RNN gebaseerde modellen en uitlijningsinformatie gebruikt voor invoersequenties. Gegeven een woord in een bepaalde taal dat niet voorkomt in het tweetalige uitspraakwoordenboek, hun systeem kan automatisch de fonemische representatie ervan in de doeltaal voorspellen.
"Geïnspireerd door sequentie-naar-sequentie terugkerende neurale netwerkgebaseerde vertaalmethoden, het huidige onderzoek presenteert een benadering die een uitlijningsrepresentatie toepast voor invoersequenties en vooraf getrainde bron- en doelinbeddingen om het transliteratieprobleem voor een taalpaar met weinig middelen te overwinnen, " legden de onderzoekers uit in hun paper.
Deze nieuwe aanpak combineert verschillende deep learning- en neurale netwerkgebaseerde technieken, inclusief encoder-decoders, aandachtsmechanismen, uitlijningsrepresentatie voor invoersequenties en vooraf getrainde bron- en doelinbeddingen. De onderzoekers evalueerden hun methode in een transliteratietaak waarbij Frans-Vietnamese taalparen met weinig middelen betrokken waren, het behalen van zeer veelbelovende resultaten.
"Evaluatie en experimenten met Frans en Vietnamees toonden aan dat met slechts een klein tweetalig uitspraakwoordenboek beschikbaar voor het trainen van de transliteratiemodellen, veelbelovende resultaten werden behaald, ’ schreven de onderzoekers.
Volgens de onderzoekers is hun studie was een van de eersten die de Vietnamese taal analyseerde in een transliteratietaak met behulp van RNN's. Hun methode leverde opmerkelijke resultaten op, beter presteren dan andere state-of-the-art statistische en multijoint sequentie-gebaseerde benaderingen.
Het nieuwe systeem dat door de onderzoekers is bedacht, kan effectief en automatisch taalkundige regelmatigheden leren uit kleine tweetalige uitspraakwoordenboeken. Hoewel hun studie het specifiek toepaste op Frans-Vietnamese transliteratietaken, het kan ook worden uitgebreid tot alle andere taalparen met weinig middelen waarvoor een tweetalig uitspraakwoordenboek beschikbaar is.
"Bij toekomstige werkzaamheden we zijn van plan om onze voorgestelde aanpak te testen met een groter tweetalig uitspraakwoordenboek en om andere benaderingen te bestuderen, zoals semi-begeleid of niet-begeleid, " schreven de onderzoekers in hun paper. "We zijn ook van plan om transfer learning te onderzoeken met behulp van andere NLP-taken of talen in instellingen met weinig middelen."
© 2019 Wetenschap X Netwerk
 Een nieuw ontdekte katalysator belooft goedkopere waterstofproductie
Een nieuw ontdekte katalysator belooft goedkopere waterstofproductie- Heavy metal donder:Eiwit kan worden ingeschakeld om elektriciteit als een metaal te geleiden
- Energie-efficiënte fotochemie op zonne-energie met luminescente zonneconcentratoren
- Chemie digitaliseren met een slimme roerstaaf
- Door resonantie versterkte tunneling induceert fluor- en para-waterstofreactie in interstellaire wolken
- Computermodel om waterbeheerders te helpen de schade bij extreme overstromingen te verminderen
- De onzekerheid van klimaatverandering doet ons pijn
- Drone-tests vinden een aantal verhoogde verontreinigende stoffen in de legerfabriek
- Afbeelding:Copernicus Sentinel-3A-satelliet kijkt naar Harvey
- Landherstel in Latijns-Amerika toont groot potentieel voor mitigatie van klimaatverandering
Hoofdlijnen
- Dominant Allele: wat is het? & Waarom gebeurt het? "(with Traits Chart)
- Hoe empathie werkt
- Bosplantages zijn een krachtige melange voor de koffieproductie
- Kleine Braziliaanse kikkers zijn doof voor hun eigen roep
- Wat is de rol van glucose in cellulaire ademhaling?
- Antibiotica uit een moleculaire puntenslijper
- Cryo-EM-beeldvorming suggereert hoe de dubbele helix scheidt tijdens replicatie
- Dierenartsen verplegen zieke bobcat, breng het terug naar het park waar het nodig is
- Onderzoekers ontdekken slecht begrepen bacteriële lijnen in de monden van dolfijnen
- Nieuwe videogame leert tieners over elektriciteit

- AI-bias:hoe technologie bepaalt of je een baan krijgt, een lening krijgen of in de gevangenis belanden

- Amerikaanse toezichthouders beschuldigen Tesla-topman Elon Musk van fraude

- A Whole New World:Disney streaming debuteert met populaire merken

- De grenzen verleggen van rotorgroei op het land


 Een driedimensionaal beeld van de Melkweg
Een driedimensionaal beeld van de Melkweg- Glutamine-afhankelijke activering van celgroei ontdekt
- Brain Model Ideas
- Armband bootst de aanraking van een persoon na!
- De winst van Baidu groeit met 56% naarmate apps en AI de inkomsten verhogen
- Wat is de gemiddelde temperatuur van Jupiter?
- Zijn onderdoorgangen veilig tijdens een tornado?
- Natuurkundigen beslechten het debat over de vorming van exotische kwantumdeeltjes
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
