Wetenschap
Model maakt de weg vrij voor sneller, efficiëntere vertalingen van meer talen
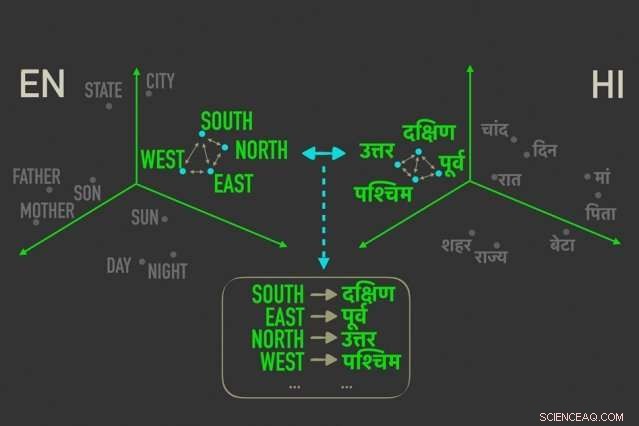
Het nieuwe model meet afstanden tussen woorden met vergelijkbare betekenissen in "woordinbeddingen, ” en lijnt vervolgens de woorden uit in beide inbeddingen die het meest gecorreleerd zijn door relatieve afstanden, wat betekent dat ze hoogstwaarschijnlijk directe vertalingen van elkaar zijn. Krediet:Massachusetts Institute of Technology
MIT-onderzoekers hebben een nieuw "onbewaakt" taalvertaalmodel ontwikkeld - wat betekent dat het werkt zonder de noodzaak van menselijke aantekeningen en begeleiding - dat zou kunnen leiden tot snellere, efficiëntere computergebaseerde vertalingen van veel meer talen.
Vertaalsystemen van Google, Facebook, en Amazon hebben trainingsmodellen nodig om patronen te zoeken in miljoenen documenten, zoals juridische en politieke documenten, of nieuwsartikelen - die door mensen in verschillende talen zijn vertaald. Gegeven nieuwe woorden in één taal, ze kunnen dan de overeenkomende woorden en zinnen in de andere taal vinden.
Maar deze translationele gegevens zijn tijdrovend en moeilijk te verzamelen, en bestaat misschien niet voor veel van de 7, 000 talen die wereldwijd worden gesproken. Onlangs, onderzoekers hebben "eentalige" modellen ontwikkeld die vertalingen maken tussen teksten in twee talen, maar zonder directe translationele informatie tussen de twee.
In een paper dat deze week wordt gepresenteerd op de Conference on Empirical Methods in Natural Language Processing, onderzoekers van MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL) beschrijven een model dat sneller en efficiënter werkt dan deze eentalige modellen.
Het model maakt gebruik van een metriek in statistieken, genaamd Gromov-Wasserstein afstand, die in wezen afstanden meet tussen punten in een rekenruimte en deze vergelijkt met punten op vergelijkbare afstand in een andere ruimte. Ze passen die techniek toe op "woordinbeddingen" van twee talen, wat woorden zijn die worden weergegeven als vectoren - in feite, reeksen getallen - met woorden met vergelijkbare betekenissen dichter bij elkaar geclusterd. Daarbij, het model lijnt de woorden snel uit, of vectoren, in beide inbeddingen die het meest gecorreleerd zijn door relatieve afstanden, wat betekent dat het waarschijnlijk directe vertalingen zijn.
Bij experimenten, het model van de onderzoekers presteerde net zo nauwkeurig als de modernste eentalige modellen - en soms nauwkeuriger - maar veel sneller en met slechts een fractie van de rekenkracht.
"Het model ziet de woorden in de twee talen als verzamelingen vectoren, en brengt [die vectoren] van de ene set naar de andere door in wezen relaties te behouden, ", zegt de co-auteur van de krant Tommi Jaakkola, een CSAIL-onderzoeker en de Thomas Siebel-hoogleraar bij de faculteit Elektrotechniek en Informatica en het Institute for Data, systemen, en Maatschappij. "De aanpak kan helpen bij het vertalen van talen of dialecten met weinig middelen, zolang ze maar met voldoende eentalige inhoud komen."
Het model vertegenwoordigt een stap in de richting van een van de belangrijkste doelen van machinevertaling, die volledig onbewaakte woorduitlijning is, zegt eerste auteur David Alvarez-Melis, een CSAIL Ph.D. student:"Als je geen gegevens hebt die overeenkomen met twee talen ... kun je twee talen toewijzen en, met behulp van deze afstandsmetingen, lijn ze uit."
Relaties zijn het belangrijkst
Het uitlijnen van woordinbeddingen voor automatische vertalingen zonder toezicht is geen nieuw concept. Recent werk traint neurale netwerken om vectoren direct te matchen in woordinbeddingen, of matrices, uit twee talen samen. Maar deze methoden vereisen veel aanpassingen tijdens de training om de uitlijning precies goed te krijgen, wat inefficiënt en tijdrovend is.
Meten en matchen van vectoren op basis van relationele afstanden, anderzijds, is een veel efficiëntere methode die niet veel finetuning vereist. Het maakt niet uit waar woordvectoren in een gegeven matrix vallen, de relatie tussen de woorden, hun afstanden bedoelen, zal hetzelfde blijven. Bijvoorbeeld, de vector voor "vader" kan in twee matrices in totaal verschillende gebieden vallen. Maar vectoren voor "vader" en "moeder" zullen hoogstwaarschijnlijk altijd dicht bij elkaar liggen.
"Die afstanden zijn onveranderlijk, " zegt Alvarez-Melis. "Door op afstand te kijken, en niet de absolute posities van vectoren, dan kun je de uitlijning overslaan en direct naar het matchen van de overeenkomsten tussen vectoren gaan."
Dat is waar Gromov-Wasserstein van pas komt. De techniek is gebruikt in de informatica voor, zeggen, helpen bij het uitlijnen van beeldpixels in grafisch ontwerp. Maar de metriek leek 'op maat gemaakt' voor woorduitlijning, Alvarez-Melis zegt:"Als er punten zijn, of woorden, die dicht bij elkaar in één ruimte staan, Gromov-Wasserstein gaat automatisch proberen de corresponderende cluster van punten in de andere ruimte te vinden."
Voor training en testen, de onderzoekers gebruikten een dataset van openbaar beschikbare woordinbeddingen, genaamd FASTTEXT, met 110 talenparen. In deze inbeddingen en anderen, woorden die steeds vaker in vergelijkbare contexten voorkomen, hebben nauw overeenkomende vectoren. "Moeder" en "vader" zullen meestal dicht bij elkaar zijn, maar beide verder weg van, zeggen, "huis."
Zorg voor een "zachte vertaling"
Het model merkt vectoren op die nauw verwant zijn maar toch verschillen van de andere, en wijst een waarschijnlijkheid toe dat vectoren op vergelijkbare afstand in de andere inbedding zullen corresponderen. Het is een soort "zachte vertaling, "Alvarez-Melis zegt, "omdat in plaats van slechts een enkele woordvertaling terug te geven, het vertelt je 'deze vector, of woord, heeft een sterke overeenkomst met dit woord, of woorden, in de andere taal.'"
Een voorbeeld zou zijn in de maanden van het jaar, die in veel talen dicht bij elkaar voorkomen. Het model zal een cluster van 12 vectoren zien die geclusterd zijn in de ene inbedding en een opmerkelijk gelijkaardige cluster in de andere inbedding. "Het model weet niet dat dit maanden zijn, " zegt Alvarez-Melis. "Het weet gewoon dat er een cluster van 12 punten is die overeenkomt met een cluster van 12 punten in de andere taal, maar ze zijn anders dan de rest van de woorden, dus ze gaan waarschijnlijk goed samen. Door deze overeenkomsten voor elk woord te vinden, het lijnt dan de hele ruimte tegelijkertijd uit."
De onderzoekers hopen dat het werk dient als een "haalbaarheidscontrole, "Jaakkola zegt, om de Gromov-Wasserstein-methode toe te passen op automatische vertaalsystemen om sneller te werken, efficiënter, en krijg toegang tot veel meer talen.
Aanvullend, een mogelijk voordeel van het model is dat het automatisch een waarde produceert die kan worden geïnterpreteerd als kwantificerend, op numerieke schaal, de gelijkenis tussen talen. Dit kan nuttig zijn voor taalkundige studies, zeggen de onderzoekers. Het model berekent hoe ver alle vectoren van elkaar verwijderd zijn in twee inbeddingen, die afhangt van de zinsbouw en andere factoren. Als vectoren allemaal heel dichtbij zijn, ze zullen dichter bij 0 scoren, en hoe verder ze uit elkaar liggen, hoe hoger de score. Vergelijkbare Romaanse talen zoals Frans en Italiaans, bijvoorbeeld, scoren dicht bij 1, terwijl klassiek Chinees tussen de 6 en 9 scoort met andere belangrijke talen.
"Hierdoor krijg je een mooie, eenvoudig getal voor hoe vergelijkbare talen zijn ... en kan worden gebruikt om inzichten te krijgen over de relaties tussen talen, ' zegt Allvarez-Melis.
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Hoe maakt zout water een eierdipper?
Hoe maakt zout water een eierdipper? - Op heterdaad betrapt:beelden leggen moleculaire bewegingen in realtime vast
- Het verschil tussen isotopen van hetzelfde element
- Met röntgentomografie kunnen onderzoekers solid-state batterijen zien opladen, afvoer
- 3D-katalysatoren voor verbeterde hydrazinevrije drijfgassen
- Over de vier natuurgebieden van Texas
- Satelliet trekt de aandacht van snel intensiverende tropische cycloon Cilida
- Huisontwikkelaars kunnen het geheime wapen zijn om de luchtkwaliteit te verbeteren
- Materiaalefficiëntie biedt een groot potentieel voor klimaatneutraliteit
- Geologen rapporteren eerder bewijs van dreigend massaal uitsterven in het Perm, en hedendaagse parallellen
Hoofdlijnen
- Microbioomtransplantaties bieden ziekteresistentie in ernstig bedreigde Hawaiiaanse plant
- Bacteriën krijgen resistentie van concurrenten
- Rijd naar gigantisch nieuw zeereservaat op Antarctica
- Wanneer is de beste tijd van de dag om een beslissing te nemen?
- Beperkingen Enzymen die worden gebruikt in DNA-vingerafdrukken
- Drones gebruiken om gewasschade door wilde zwijnen in te schatten
- Dahls paddenkopschildpad bedreigd door versnipperd leefgebied, krimpende bevolking
- De voordelen van Anaerobe Ademhaling
- Schimmel is afhankelijk van bacteriën om de belangrijkste componenten van zijn voortplantingsmechanisme te reguleren
- Uitgelekte benchmarks tonen Intel Tiger Lakes-snelheid

- Netwerken met geesten in de machine... en sprekende ketels

- Op weg naar taalinferentie in de geneeskunde

- Dood van Fiat Chrysler-chef richt schijnwerpers op gezondheid CEO

- Inzicht in onderzoek naar hoe mensen vertrouwen in AI ontwikkelen, kan het gebruik ervan informeren


 Veranderende ecosystemen in Beieren
Veranderende ecosystemen in Beieren- Een 3D-model maken van de planeet Venus
- Een derde van de rivieren in de VS bleek te veranderen van blauw naar groen en geel
- Onderzoekers schetsen visie voor winstgevende oplossing voor klimaatverandering
- Het belang van de puberteit:een oproep voor betere onderzoeksmodellen
- Wetenschappers ontdekken een 2D-magneet
- in eerste, Zwitserland sluit verouderde kerncentrale
- Wat is een homologe eigenschap?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
