Wetenschap
Geautomatiseerd systeem identificeert dicht weefsel, een risicofactor voor borstkanker, op mammogrammen
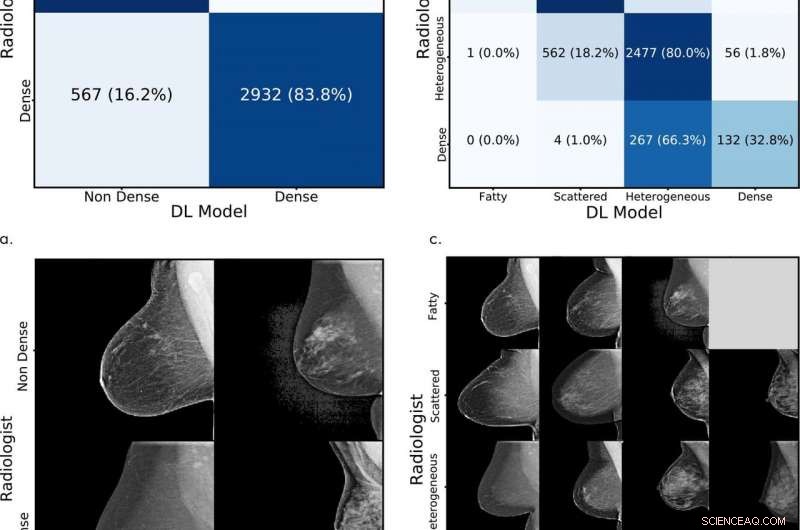
Testset beoordeling. Vergelijking van de oorspronkelijke interpretatie van de radioloogbeoordeling met de deep learning (DL) -modelbeoordeling voor (a) binaire en (c) viervoudige mammografische classificatie van borstdensiteit. (B, d) Overeenkomstige voorbeelden van mammogrammen met concordante en discordante beoordelingen door de radioloog en met het DL-model. Krediet:Radiologische Vereniging van Noord-Amerika
Onderzoekers van het MIT en het Massachusetts General Hospital hebben een geautomatiseerd model ontwikkeld dat dicht borstweefsel in mammogrammen - wat een onafhankelijke risicofactor is voor borstkanker - even betrouwbaar beoordeelt als deskundige radiologen.
Dit is de eerste keer dat een diepgaand leermodel in zijn soort met succes is gebruikt in een kliniek bij echte patiënten, volgens de onderzoekers. Met brede implementatie, de onderzoekers hopen dat het model kan helpen bij het vergroten van de betrouwbaarheid van beoordelingen van de borstdichtheid in het hele land.
Naar schatting heeft meer dan 40 procent van de Amerikaanse vrouwen dicht borstweefsel, wat alleen al het risico op borstkanker verhoogt. Bovendien, dicht weefsel kan kankers op het mammogram maskeren, screening moeilijker maken. Als resultaat, 30 Amerikaanse staten verplichten vrouwen om op de hoogte te worden gesteld als hun mammogrammen aangeven dat ze dichte borsten hebben.
Maar beoordelingen van de borstdichtheid zijn afhankelijk van subjectieve menselijke beoordeling. Door vele factoren, resultaten variëren - soms dramatisch - tussen radiologen. De MIT- en MGH-onderzoekers trainden een diepgaand leermodel op tienduizenden hoogwaardige digitale mammogrammen om verschillende soorten borstweefsel te leren onderscheiden, van vet tot extreem dik, op basis van deskundige beoordelingen. Gegeven een nieuw mammogram, het model kan dan een dichtheidsmeting identificeren die nauw aansluit bij de mening van deskundigen.
"Borstdichtheid is een onafhankelijke risicofactor die bepaalt hoe we met vrouwen communiceren over hun risico op kanker. Onze motivatie was om een nauwkeurig en consistent hulpmiddel te creëren, die kunnen worden gedeeld en gebruikt in zorgstelsels, " zegt tweede auteur Adam Yala, een doctoraat student in MIT's Computer Science and Artificial Intelligence Laboratory (CSAIL).
De andere co-auteurs zijn eerste auteur Constance Lehman, hoogleraar radiologie aan de Harvard Medical School en de directeur van borstbeeldvorming aan het MGH; en senior auteur Regina Barzilay, de Delta Electronics Professor bij CSAIL en het Department of Electrical Engineering and Computer Science aan het MIT.
Kaartdichtheid
Het model is gebouwd op een convolutioneel neuraal netwerk (CNN), die ook wordt gebruikt voor computervisietaken. De onderzoekers trainden en testten hun model op een dataset van meer dan 58, 000 willekeurig geselecteerde mammogrammen uit meer dan 39, 000 vrouwen gescreend tussen 2009 en 2011. Voor opleiding, ze gebruikten rond 41, 000 mammogrammen en, om uit te proberen, ongeveer 8, 600 mammogrammen.
Elk mammogram in de dataset heeft een standaard Breast Imaging Reporting and Data System (BI-RADS) borstdichtheidsclassificatie in vier categorieën:vet, verspreid (verstrooide dichtheid), heterogeen (meestal dicht), en dicht. Zowel bij het trainen als bij het testen van mammogrammen, ongeveer 40 procent werd beoordeeld als heterogeen en compact.
Tijdens het opleidingsproces het model krijgt willekeurige mammogrammen om te analyseren. Het leert het mammogram in kaart te brengen met dichtheidsclassificaties van deskundige radiologen. Dichte borsten, bijvoorbeeld, klier- en vezelig bindweefsel bevatten, die verschijnen als compacte netwerken van dikke witte lijnen en stevige witte vlekken. Vetweefselnetwerken lijken veel dunner, met overal grijs gebied. Bij het testen, het model observeert nieuwe mammogrammen en voorspelt de meest waarschijnlijke dichtheidscategorie.
Passende beoordelingen
Het model werd geïmplementeerd bij de afdeling borstbeeldvorming van MGH. In een traditionele workflow wanneer een mammogram wordt gemaakt, het wordt naar een werkstation gestuurd zodat een radioloog het kan beoordelen. Het model van de onderzoekers wordt geïnstalleerd in een aparte machine die de scans onderschept voordat ze de radioloog bereiken. en kent aan elk mammogram een dichtheidsclassificatie toe. Wanneer radiologen een scan op hun werkstation ophalen, ze zien de toegekende beoordeling van het model, die ze vervolgens accepteren of afwijzen.
"Het duurt minder dan een seconde per afbeelding ... [en het kan] gemakkelijk en goedkoop worden geschaald in ziekenhuizen." zegt Yala.
Op meer dan 10, 000 mammogrammen bij MGH van januari tot mei van dit jaar, het model bereikte een overeenstemming van 94 procent onder de radiologen van het ziekenhuis in een binaire test, waarbij werd bepaald of borsten heterogeen en dicht waren, of vet en verspreid. In alle vier de BI-RADS-categorieën, het kwam overeen met de beoordelingen van radiologen voor 90 procent. "MGH is een toonaangevend centrum voor beeldvorming van de borst met een hoge overeenkomst tussen radiologen, en deze hoogwaardige dataset stelde ons in staat een sterk model te ontwikkelen, "zegt Yala.
In het algemeen testen met behulp van de originele dataset, het model kwam met 77 procent overeen met de oorspronkelijke interpretaties van menselijke experts in vier BI-RADS-categorieën en, in binaire tests, kwam overeen met de interpretaties op 87 procent.
In vergelijking met traditionele voorspellingsmodellen, de onderzoekers gebruikten een metriek genaamd een kappa-score, waarbij 1 aangeeft dat voorspellingen elke keer overeenkomen, en alles wat lager is, duidt op minder gevallen van overeenkomsten. Kappa-scores voor in de handel verkrijgbare modellen voor automatische dichtheidsbeoordeling scoren maximaal ongeveer 0,6. In de klinische toepassing het model van de onderzoekers scoorde 0,85 kappa-score en, bij het testen, scoorde een 0,67. Dit betekent dat het model betere voorspellingen doet dan traditionele modellen.
In een aanvullend experiment de onderzoekers testten de overeenstemming van het model met de consensus van vijf MGH-radiologen van 500 willekeurige testmammogrammen. De radiologen kenden de borstdensiteit toe aan de mammogrammen zonder kennis van de oorspronkelijke beoordeling, of de beoordelingen van hun collega's of het model. In dit experiment, het model behaalde een kappa-score van 0,78 met de consensus van de radioloog.
Volgende, de onderzoekers willen het model opschalen naar andere ziekenhuizen. "Voortbouwend op deze translationele ervaring, we zullen onderzoeken hoe we algoritmen voor machinaal leren die aan het MIT zijn ontwikkeld, kunnen omzetten in klinieken die miljoenen patiënten ten goede komen, " zegt Barzilay. "Dit is een charter van het nieuwe centrum aan het MIT - de Abdul Latif Jameel Clinic for Machine Learning in Health aan het MIT - dat onlangs is gelanceerd. En we zijn enthousiast over de nieuwe mogelijkheden die dit centrum biedt."
 Wat zijn de tijden voor kolibries in Kansas?
Wat zijn de tijden voor kolibries in Kansas? - Amerikaanse milieugroeperingen dienen een rechtszaak in om nieuwe mijnbouw op openbare gronden te blokkeren
- Video:Satellietbeelden van zware storm die Michoud-tornado veroorzaakte
- Overtuigende landbouwspraakonderwerpen
- Orkanen:iets sterker, een beetje langzamer, en een stuk natter in een warmer klimaat
Hoofdlijnen
- Hoe reproduceren algen?
- Cellulaire ademhaling in ontkiemende zaden
- Klop, klop! Wie is daar?
- Boek beschrijft alle 451 families van bloeiende planten, varens, lycopoden en naaktzadigen
- Een keep-fit gadget voor uw hond deze kerst - wie heeft er echt baat bij?
- Volghalsbanden onthullen de geheimen van bavianen overvaltactieken
- Heerlijke narcissen zijn super eenvoudig te kweken. Hier is hoe
- Hoe komen de spermacellen in een stuifmeelkorrel aan bij de eicelklus in een plant-ovule?
- Licht schijnen op het sociale leven van virussen
- Apple tegen wetgevers:Siri luistert niet totdat daarom wordt gevraagd

- Nieuwe VW-chef Diess wil reus uit dieselwolk sturen

- Harvard-forum onderzoekt de veiligheid van zelfrijdende voertuigen

- Minimalistische algoritmen voor machine learning analyseren afbeeldingen van zeer weinig gegevens
- Google Assistent voegt meer talen toe in wereldwijde push


 Waarom belastingverlagingen ons minder gelukkig maken
Waarom belastingverlagingen ons minder gelukkig maken- Eén transistor voor alle doeleinden
- Studie onderzoekt chemische eigenschappen van bolhoop NGC 1261
- Slimmere steden ontwerpen met behulp van computerspelletjes
- Regels voor het gebruik van getallen in APA Format
- Nieuwe configuratie van DNA ontdekt
- Gazons voor peulvruchten:Minnesota betaalt huiseigenaren om bijengazons te planten
- Afbeelding:Het krimpende water van het Tsjaadmeer
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | Dutch | Danish | Norway | Spanish | German |

-
Wetenschap © https://nl.scienceaq.com
