Wetenschap
AI-ondersteunde notities voor elektronische medische dossiers
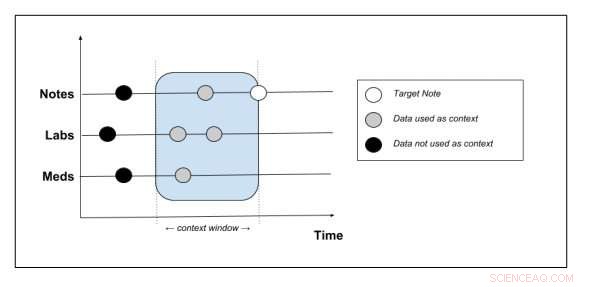
Schematische weergave van welke contextgegevens uit het patiëntendossier worden gehaald. Krediet:Peter Liu
Artsen besteden momenteel veel tijd aan het schrijven van aantekeningen over patiënten en deze in te voeren in elektronische patiëntendossiers (EPD). Volgens een onderzoek uit 2016, artsen besteden ongeveer twee uur aan administratief werk voor elk uur dat ze met een patiënt doorbrengen. Dankzij geavanceerde tools voor kunstmatige intelligentie, dit proces voor het schrijven van notities zou binnenkort geautomatiseerd kunnen worden, artsen helpen hun diensten beter te beheren en hen van deze vervelende taak te verlossen.
Peter Liu, een onderzoeker bij Google Brain, heeft onlangs een nieuwe taalmodelleringstaak ontwikkeld die de inhoud van nieuwe notities kan voorspellen door medische dossiers van patiënten te analyseren, die gegevens bevatten zoals demografie, laboratorium metingen, medicijnen en aantekeningen uit het verleden. In zijn studeerkamer voorgepubliceerd op arXiv, hij trainde generatieve modellen met behulp van de MIMIC-III (Medical Information Mart for Intensive Care) EPD-dataset, en vergeleek vervolgens de door de modellen gegenereerde aantekeningen met echte aantekeningen uit de dataset.
Veelgebruikte methoden om de tijd die artsen besteden aan het maken van aantekeningen te verminderen, zijn onder meer het gebruik van dicteerservices en het inhuren van assistenten die aantekeningen voor hen kunnen maken. Tools voor kunstmatige intelligentie kunnen helpen om dit probleem aan te pakken, het verminderen van de kosten voor extra personeel en middelen.
"Ondersteunende schrijffuncties voor notities, zoals automatisch aanvullen of foutcontrole, profiteren van taalmodellen, ' schrijft Liu in zijn krant. 'Hoe sterker het model, hoe effectiever dergelijke functies waarschijnlijk zouden zijn. Dus, de focus van dit artikel ligt op het bouwen van taalmodellen voor klinische aantekeningen."
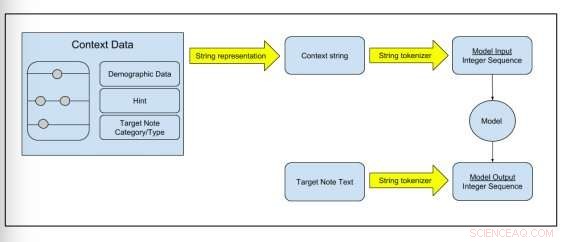
Afbeelding 2:Schematische weergave van hoe onbewerkte gegevens worden omgezet in modeltrainingsgegevens. Krediet:Peter Liu
Liu gebruikte twee taalmodellen:de eerste heet transformatorarchitectuur, en werd geïntroduceerd in een studie die vorig jaar werd gepubliceerd in de Vooruitgang in neurale informatieverwerkingssystemen logboek. Omdat dit model beter presteert met kortere teksten, zoals individuele zinnen, hij testte ook een recent geïntroduceerd op transformatoren gebaseerd model, genaamd transformator met geheugen gecomprimeerde aandacht (T-DMCA), die effectiever bleek te zijn voor langere sequenties.
Hij trainde deze modellen op de MIMIC-III dataset, met geanonimiseerd EPD van 39, 597 patiënten van de intensive care van een tertiair ziekenhuis. Dit is momenteel de meest uitgebreide EPD-dataset die publiekelijk beschikbaar is en gemakkelijk online kan worden geraadpleegd.
"We hebben een nieuwe taalmodelleringstaak geïntroduceerd voor klinische notities op basis van HER-gegevens en hebben laten zien hoe de multimodale gegevenscontext in het model kan worden weergegeven, Liu legde in zijn paper uit. "We stelden evaluatiestatistieken voor de taak voor en presenteerden bemoedigende resultaten die de voorspellende kracht van dergelijke modellen aantonen."
De modellen waren in staat om veel van de inhoud van de aantekeningen van artsen te voorspellen. In de toekomst, ze zouden kunnen helpen bij de ontwikkeling van meer geavanceerde functies voor spellingcontrole en automatisch aanvullen. Deze functies kunnen vervolgens worden geïntegreerd in tools die clinici helpen bij het voltooien van administratief werk. Hoewel de resultaten van dit onderzoek veelbelovend zijn, enkele uitdagingen moeten nog worden overwonnen voordat de modellen op grotere schaal kunnen worden toegepast.
"Vaak, de maximale context van het EPD is onvoldoende om de notitie volledig te voorspellen, " legt Liu uit in zijn paper. "Het meest voor de hand liggende geval is het gebrek aan beeldgegevens in MIMIC-III voor radiologierapporten. Voor niet-beeldvormende notities missen we ook informatie over de nieuwste interacties tussen patiënt en zorgverlener. Toekomstig werk zou kunnen proberen om de notitiecontext uit te breiden met gegevens buiten het EPD, bijv. beeldgegevens, of transcripties van interacties tussen patiënt en arts. Hoewel we de functies voor foutcorrectie en automatisch aanvullen in EPD-software hebben besproken, hun effecten op de gebruikersproductiviteit werden niet gemeten in de klinische context, die we achterlaten als toekomstig werk."
© 2018 Tech Xplore

Hoofdlijnen
- Wat zit er aan de linkerkant van je lichaam in de menselijke anatomie?
- Stappen van DNA Transcriptie
- Wat is het doel van de fibreuze capsule?
- Stiekeme mannetjes nemen vrouwelijke hersens aan om grote bruten voor de gek te houden
- Het verschil tussen craniologie en frenologie
Craniologie en frenologie zijn beide praktijken die de conformatie van de menselijke schedel onderzoeken; echter, de twee zijn heel verschillend. Craniologie is de studie van verschillen in vorm, groott
- Mensen evolueren nog steeds - Heres the Evidence
- Kuikenembryo's leveren waardevolle genetische gegevens voor het begrijpen van de menselijke ontwikkeling
- Een eenvoudig diercelmodel maken
- Lijst van de stappen van de celcyclus in volgorde
- Arque is een op zeepaardjes geïnspireerde kunstmatige staart

- Ingenieurs 3D print zacht, rubberachtige hersenimplantaten

- Afvalplastic in beton kan duurzaam bouwen in India ondersteunen

- Singapore Airlines neemt regionale vleugel over na upgrade

- Hoe een oppervlaktebehandeling de binnenkant van een zonnecel verbetert


 Een piepschuim maken Kaliumatomen voor school
Een piepschuim maken Kaliumatomen voor school- Nieuw artikel biedt ontwerpprincipes voor ziektegevoelige nanomaterialen
- Wat veroorzaakt dispergerende krachten?
Overweeg een beker gevuld met moleculen in vloeibare toestand. Het ziet er aan de buitenkant rustig uit, maar als je de kleine elektronen in de beker zou zien bewegen, dan zouden de verspreidingskrachten duid
- Gastro-intestinaal-bewoner, vormveranderende microdevices voor verlengde medicijnafgifte
- Ultrasnelle sondering onthult ingewikkelde dynamiek van kwantumcoherentie
- Abrupte permafrostdooi verandert de microbiële structuur en functie
- Nieuw circuitontwerp stimuleert draagbare thermo-elektrische generatoren
- Hoe verander je ongepaste breuken in gemengde getallen of hele getallen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
