Wetenschap
Onderzoek identificeert de belangrijkste zwakheden in moderne computervisiesystemen
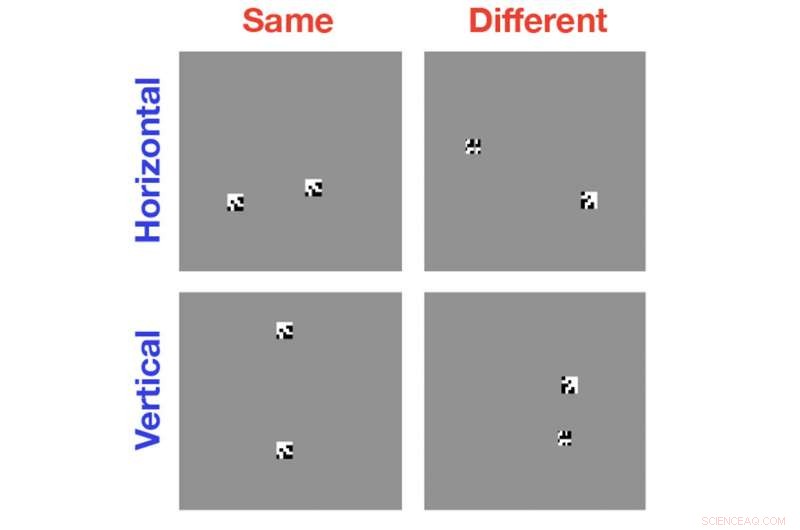
Computers zijn geweldig in het categoriseren van afbeeldingen op basis van de objecten die ermee worden gevonden, maar ze zijn verrassend slecht in het uitzoeken wanneer twee objecten in een enkele afbeelding hetzelfde of verschillend van elkaar zijn. Nieuw onderzoek helpt om aan te tonen waarom die taak zo moeilijk is voor moderne computervisie-algoritmen. Krediet:Serre-lab / Brown University
Computer vision-algoritmen hebben het afgelopen decennium een lange weg afgelegd. Het is aangetoond dat ze net zo goed of beter zijn dan mensen in taken als het categoriseren van honden- of kattenrassen, en ze hebben het opmerkelijke vermogen om specifieke gezichten te identificeren uit een zee van miljoenen.
Maar uit onderzoek van wetenschappers van Brown University blijkt dat computers jammerlijk falen bij een reeks taken waar zelfs jonge kinderen geen probleem mee hebben:bepalen of twee objecten in een afbeelding hetzelfde of verschillend zijn. In een paper die vorige week werd gepresenteerd op de jaarlijkse bijeenkomst van de Cognitive Science Society, het Brown-team werpt licht op waarom computers zo slecht zijn in dit soort taken en suggereert wegen naar slimmere computervisiesystemen.
"Er is veel opwinding over wat computervisie heeft kunnen bereiken, en ik deel er veel van, " zei Thomas Serre, universitair hoofddocent cognitieve, linguïstische en psychologische wetenschappen bij Brown en de senior auteur van de krant. "Maar we denken dat door te werken aan het begrijpen van de beperkingen van de huidige computervisiesystemen, zoals we hier hebben gedaan, we kunnen echt op weg naar nieuwe, veel geavanceerdere systemen in plaats van simpelweg de systemen die we al hebben aan te passen."
Voor de studie, Serre en zijn collega's gebruikten ultramoderne computervisie-algoritmen om eenvoudige zwart-witbeelden te analyseren die twee of meer willekeurig gegenereerde vormen bevatten. In sommige gevallen waren de objecten identiek; soms waren ze hetzelfde, maar met het ene object geroteerd ten opzichte van het andere; soms waren de objecten totaal verschillend. De computer werd gevraagd om dezelfde of een andere relatie te identificeren.
De studie toonde aan dat, zelfs na honderdduizenden trainingsvoorbeelden, de algoritmen waren niet beter dan kans op het herkennen van de juiste relatie. De vraag, dan, was waarom deze systemen zo slecht zijn in deze taak.
Serre en zijn collega's hadden het vermoeden dat het iets te maken heeft met het onvermogen van deze computer vision-algoritmen om objecten te individualiseren. Als computers naar een afbeelding kijken, ze kunnen niet echt zien waar een object in de afbeelding stopt en de achtergrond, of een ander voorwerp, begint. Ze zien alleen een verzameling pixels die patronen hebben die vergelijkbaar zijn met verzamelingen pixels die ze hebben leren associëren met bepaalde labels. Dat werkt prima voor identificatie- of categorisatieproblemen, maar valt uit elkaar wanneer je twee objecten probeert te vergelijken.
Om aan te tonen dat dit inderdaad de reden was waarom de algoritmen het begaven, Serre en zijn team voerden experimenten uit die ervoor zorgden dat de computer niet zelf objecten hoefde te individualiseren. In plaats van de computer twee objecten in dezelfde afbeelding te laten zien, de onderzoekers toonden de computer de objecten één voor één in afzonderlijke afbeeldingen. De experimenten toonden aan dat de algoritmen geen probleem hadden met het leren van dezelfde of verschillende relaties, zolang ze de twee objecten niet in dezelfde afbeelding hoefden te bekijken.
De oorzaak van het probleem bij het individualiseren van objecten, Serre zegt, is de architectuur van de machine learning-systemen die de algoritmen aandrijven. De algoritmen gebruiken convolutionele neurale netwerken - lagen van verbonden verwerkingseenheden die losjes netwerken van neuronen in de hersenen nabootsen. Een belangrijk verschil met de hersenen is dat de kunstmatige netwerken uitsluitend "feed-forward" zijn - wat betekent dat informatie eenrichtingsverkeer door de lagen van het netwerk heeft. Zo werkt het visuele systeem bij mensen niet, volgens Serre.
"Als je kijkt naar de anatomie van ons eigen visuele systeem, je merkt dat er veel terugkerende verbanden zijn, waar de informatie van een hoger visueel gebied naar een lager visueel gebied gaat en weer terug, ' zei Serre.
Hoewel het niet duidelijk is wat die feedback precies doet, Serre zegt, het is waarschijnlijk dat ze iets te maken hebben met ons vermogen om aandacht te schenken aan bepaalde delen van ons gezichtsveld en om mentale representaties te maken van objecten in onze geest.
"Vermoedelijk houden mensen zich bezig met één object, het bouwen van een feature-representatie die in hun werkgeheugen aan dat object is gebonden, ' zei Serre. 'Dan verleggen ze hun aandacht naar een ander object. Wanneer beide objecten in het werkgeheugen worden weergegeven, je visuele systeem is in staat om vergelijkingen te maken zoals hetzelfde of verschillend."
Serre en zijn collega's veronderstellen dat de reden waarom computers zoiets niet kunnen doen, is omdat feed-forward neurale netwerken niet het soort terugkerende verwerking mogelijk maken dat nodig is voor deze individuatie en mentale representatie van objecten. Het zou kunnen, Serre zegt, dat om computervisie slimmer te maken, neurale netwerken nodig zijn die de terugkerende aard van menselijke visuele verwerking beter benaderen.
 Circulaire wateroplossingen toepassen van India tot Zweden
Circulaire wateroplossingen toepassen van India tot Zweden- Het aantal klimaatontkenners in Australië is meer dan het dubbele van het wereldwijde gemiddelde, nieuwe enquête vondsten
- Routinematig affakkelen van gas is verspilling, vervuilend en ondermaats
- Wat is een juni-kever en Japanse kever?
- When Was the Rain Gauge Invented?
Hoofdlijnen
- Monster ontdekt in het Canadese Noordpoolgebied
- Bijen gebruiken onzichtbare warmtepatronen om bloemen te kiezen
- Wat is de functie van een eicel?
- Studie identificeert walvisblaasmicrobioom
- Hoeveelheid water in stamcellen kan zijn lot bepalen als vet of bot
- Veldonderzoek heeft tot doel de verspreiding van door teken overgedragen ziekten in het Midwesten te vertragen
- Als een soort niet over voldoende genenpool beschikt,
- Wetenschappers hebben ontdekt welke genen onkambaar haarsyndroom veroorzaken
- Nieuw apparaat zoomt in op microbengedrag op de juiste schaal
- Boeing-leverancier Spirit AeroSystems ontslaat 2, 800 arbeiders

- Industrieel 3D-printen wordt skateboarden

- Gegevensgestuurde verkiezingen en de belangrijkste vragen over kiezerstoezicht

- Idaho, Energieministerie tekent deal over verbruikte splijtstof

- Veel bevolkingen vrezen groot banenverlies door automatisering:enquête


 Nieuw boek onderzoekt kritisch anti-bias messaging in kinderamusement
Nieuw boek onderzoekt kritisch anti-bias messaging in kinderamusement- Hoe sommige landen digitale id's gebruiken om kwetsbare mensen over de hele wereld uit te sluiten
- Komeet maakt pitstop nabij asteroïden Jupiter
- Techniek onthult diepere inzichten in de samenstelling van parelmoer, een natuurlijk materiaal
- Veiligheid op de werkplek kan verslechteren onder pestende bazen, studie vondsten
- De versnelde uitdijing van het heelal verklaren zonder donkere energie
- Silly Putty-materiaal inspireert tot betere batterijen
- Kandidaat voor donkere materie kan draderige effecten vertonen in het laboratorium
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | French |

-
Wetenschap © https://nl.scienceaq.com
