Wetenschap
De intellectuele eigendom van AI beschermen met watermerken
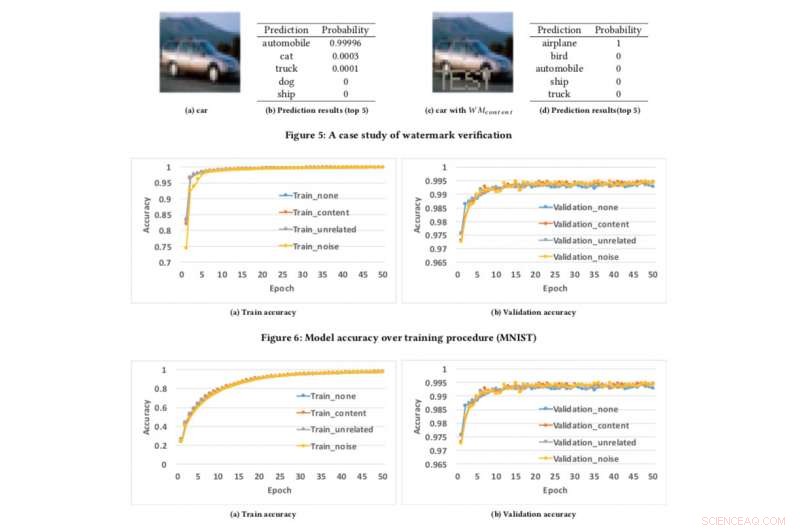
Modelnauwkeurigheid boven trainingsprocedure. Krediet:CIFAR10
Als we video's kunnen beschermen, audio en foto's met digitale watermerken, waarom geen AI-modellen?
Dit is de vraag die mijn collega's en ik onszelf stelden toen we probeerden een techniek te ontwikkelen om ontwikkelaars te verzekeren dat hun harde werk bij het bouwen van AI, zoals deep learning-modellen, kan worden beschermd. Je denkt misschien, 'Beschermd tegen wat?' We zullen, bijvoorbeeld, wat als uw AI-model wordt gestolen of misbruikt voor snode doeleinden, zoals het aanbieden van een geplagieerde service gebaseerd op een gestolen model? Dit is een zorg, vooral voor AI-leiders zoals IBM.
Eerder deze maand presenteerden we ons onderzoek op de AsiaCCS '18 conferentie in Incheon, Republiek Korea, en we zijn er trots op te kunnen zeggen dat onze uitgebreide evaluatietechniek om deze uitdaging aan te gaan zeer effectief en robuust is gebleken. Onze belangrijkste innovatie is dat ons concept op afstand het eigendom van deep neural network (DNN)-services kan verifiëren met behulp van eenvoudige API-query's.
Naarmate modellen voor diep leren op grotere schaal worden ingezet en waardevoller worden, ze worden steeds vaker het doelwit van tegenstanders. Ons idee, waarop patent is aangevraagd, haalt inspiratie uit de populaire watermerktechnieken die worden gebruikt voor multimedia-inhoud, zoals video's en foto's.
Bij het watermerken van een foto zijn er twee fasen:insluiten en detecteren. In de inbeddingsfase eigenaren kunnen het woord "COPYRIGHT" op de foto plaatsen (of watermerken die onzichtbaar zijn voor menselijke waarneming) en als het wordt gestolen en door anderen wordt gebruikt, bevestigen we dit in de detectiefase, waarbij eigenaren de watermerken kunnen extraheren als wettelijk bewijs om eigendom te bewijzen. Hetzelfde idee kan worden toegepast op DNN.
Door watermerken in DNN-modellen in te sluiten, als ze gestolen worden, we kunnen het eigendom verifiëren door watermerken uit de modellen te extraheren. Echter, anders dan digitale watermerken, die watermerken insluit in multimedia-inhoud, we moesten een nieuwe methode ontwerpen om watermerken in DNN-modellen in te bedden.
In onze krant, we beschrijven een benadering om watermerken in DNN-modellen te infuseren, en ontwerp een mechanisme voor verificatie op afstand om het eigendom van DNN-modellen te bepalen met behulp van API-aanroepen.
We hebben drie algoritmen voor het genereren van watermerken ontwikkeld om verschillende soorten watermerken voor DNN-modellen te genereren:
- het insluiten van zinvolle inhoud samen met de originele trainingsgegevens als watermerken in de beschermde DNN's,
- het insluiten van irrelevante gegevensmonsters als watermerken in de beschermde DNN's, en
- het inbedden van ruis als watermerken in de beschermde DNN's.
Om ons kader voor watermerken te testen, we gebruikten twee openbare datasets:MNIST, een handgeschreven dataset voor cijferherkenning met 60, 000 trainingsafbeeldingen en 10, 000 testbeelden en CIFAR10, een objectclassificatie dataset met 50, 000 trainingsafbeeldingen en 10, 000 testbeelden.
Het uitvoeren van het experiment is vrij eenvoudig:we voorzien de DNN eenvoudig van een speciaal vervaardigde afbeelding, die een onverwachte maar gecontroleerde reactie veroorzaakt als het model is voorzien van een watermerk. Dit is niet de eerste keer dat watermerken worden overwogen, maar eerdere concepten waren beperkt door toegang tot modelparameters te vereisen. Echter, in de echte wereld, de gestolen modellen worden meestal op afstand ingezet, en de geplagieerde dienst zou de parameters van de gestolen modellen niet publiceren. In aanvulling, de ingebedde watermerken in DNN-modellen zijn robuust en bestand tegen verschillende tegenwatermerkmechanismen, zoals finetunen, snoeien van parameters, en modelinversie-aanvallen.
Helaas, ons raamwerk heeft wel enkele beperkingen. Als het gelekte model niet als online dienst wordt ingezet maar als interne dienst wordt gebruikt, dan kunnen we geen diefstal ontdekken, maar dan kan de plagiaat natuurlijk niet direct geld verdienen aan de gestolen modellen.
In aanvulling, ons huidige kader voor watermerken kan de DNN-modellen niet beschermen tegen diefstal via voorspellings-API's, waarbij aanvallers de spanning tussen toegang tot query's en vertrouwelijkheid in de resultaten kunnen benutten om de parameters van machine learning-modellen te leren. Echter, Van dergelijke aanvallen is in de praktijk alleen aangetoond dat ze goed werken voor conventionele algoritmen voor machine learning met minder modelparameters zoals beslisbomen en logistische regressies.
We zijn momenteel aan het kijken om dit binnen IBM te implementeren en te onderzoeken hoe de technologie als een service voor klanten kan worden geleverd.
Dit verhaal is opnieuw gepubliceerd met dank aan IBM Research. Lees hier het originele verhaal.
 Wetenschappers onthullen dynamische zilverkristallisatie door in-situ SEM
Wetenschappers onthullen dynamische zilverkristallisatie door in-situ SEM- Gericht op verborgen zak voor behandeling van beroerte en epileptische aanvallen
- Team ontdekt dat polymorfe selectie tijdens kristalgroei thermodynamisch kan worden aangestuurd
- Holografische bundelvorming om metallic 3D-printen een boost te geven
- Team ontwikkelt nieuwe manieren om medicijnen te maken en af te leveren voor een breed scala aan immuun-medicinale neuropathieën
- Satellieten onthullen smelten van rotsen onder vulkanische zone, diep in de aardmantel
- Bestrijding van zwerfvuil op zee:innovatieve oplossingen voor de bestrijding van vervuiling in de oceanen
- Model suggereert dat de koolstofvastlegging van vissen in de oceaan de afgelopen eeuw met de helft is afgenomen
- Beleid dat is ontworpen om de volksgezondheid tegen fracking te beschermen, kan in de praktijk ondoeltreffend zijn
- NASA ontdekt dat tropische cycloon Ambali snel heviger wordt
Hoofdlijnen
- Hoe zijn bacteriën en plantencellen gelijk?
- Hoe schimmels fruitvliegen manipuleren om sporen te ontvangen en vrij te geven?
- Pittige Tomaten,
- Een DNA-model maken met behulp van pijpreinigers
- De functie van macromoleculen
- Er is een genetische reden waarom Labrador Retrievers geobsedeerd zijn door voedsel
- Wat is een voorbeeld in een levend systeem van hoe moleculair van vorm is?
- Hoe verbeteren microscopen ons leven vandaag?
- Het sluiten van wegen gaat de effecten van habitatverlies voor grizzlyberen tegen
- De eerste rankachtige zachte robot die kan klimmen

- Toen Concorde 50 jaar geleden voor het eerst de lucht in ging

- Kunnen robots ooit een echt zelfgevoel hebben? Wetenschappers boeken vooruitgang

- Bitcoin bereikt laagste punt in 4 maanden na diefstal van valuta

- Siri, waar is AI goed voor? Expert legt uit waarom dat een moeilijke vraag is


 Gebrek aan media-scepticisme gekoppeld aan geloof in verkrachtingsmythen
Gebrek aan media-scepticisme gekoppeld aan geloof in verkrachtingsmythen- Kinderen hebben er baat bij als ze sociale en emotionele vaardigheden aanleren, maar sommige methoden zijn beter dan andere
- Computational intelligence-geïnspireerde clustering in voertuignetwerken met meerdere toegangen
- Griekse autoriteiten zeggen dat de verloren oude stad Tenea is gelegen
- Wat is drusy kwarts?
- Samen beter:grafeen-nanobuis hybride schakelaars
- Braziliaanse bossen blijken over te gaan van koolstofputten naar koolstofbronnen
- Kiezers hebben een hoge tolerantie voor politici die liegen, zelfs degenen die het doen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
