Wetenschap
Hoe u uw robot traint:onderzoek biedt nieuwe benaderingen
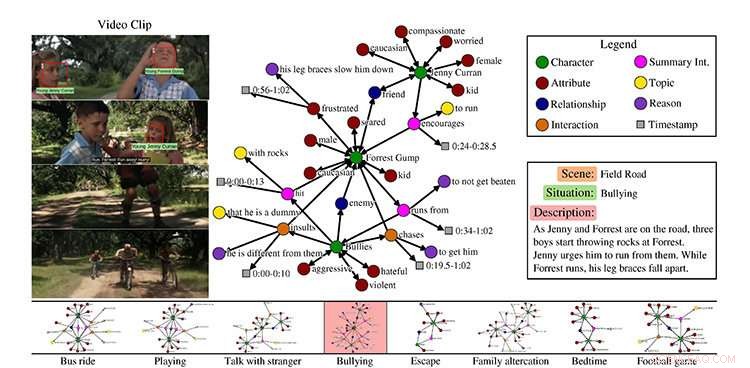
Een voorbeeld uit de MovieGraphs-dataset, scène uit de film Forrest Gump. Krediet:Universiteit van Toronto
Als je vriend verdrietig is, je kunt iets zeggen om ze op te vrolijken. Als je je collega vraagt om koffie te zetten, ze kennen de stappen om deze taak te voltooien.
Maar hoe kunnen kunstmatig intelligente robots, of AI's, leren zich op dezelfde manier te gedragen als mensen?
Onderzoekers van de Universiteit van Toronto presenteren nieuwe benaderingen van sociaal intelligente AI's, op de conferentie Computer Vision and Pattern Recognition (CVPR), het belangrijkste jaarlijkse computer vision-evenement deze week in Salt Lake City, Utah.
Hoe leren we een robot hoe hij zich moet gedragen?
In hun paper MovieGraphs:Towards Understanding Human-Centric Situations from Videos, Paul Vicol, een doctoraat student informatica, Makarand Tapaswi, een postdoctoraal onderzoeker, Lluis Castrejon, een masterdiploma van U of T computerwetenschappen die nu een Ph.D. student aan het University of Montreal Institute for Learning Algorithms, en Sanja Fidler, een assistent-professor aan de afdeling wiskundige en computationele wetenschappen van U of T Mississauga en de afstudeerafdeling informatica op drie campussen, hebben een dataset van geannoteerde videoclips van meer dan 50 films verzameld.
"MovieGraphs is een stap in de richting van de volgende generatie cognitieve agenten die kunnen redeneren over hoe mensen zich voelen en over de motivaties voor hun gedrag, " zegt Vicol. "Ons doel is om machines in staat te stellen zich gepast te gedragen in sociale situaties. Onze grafieken leggen veel hoogwaardige eigenschappen van menselijke situaties vast die nog niet eerder zijn onderzocht."
Hun dataset richt zich op films in het drama, romantiek, en comedygenres, zoals Forrest Gump en Titanic, en volgt karakters in de tijd. Ze bevatten geen superheldenfilms zoals Thor omdat ze niet erg representatief zijn voor de menselijke ervaring.
"Het idee was om films te gebruiken als een proxy voor de echte wereld, "zegt Vicol.
Elke clip, hij zegt, wordt geassocieerd met een grafiek die veel details vastlegt over wat er in de clip gebeurt:welke personages aanwezig zijn, hun relaties, interacties tussen elkaar, samen met de redenen waarom ze interactie hebben, en hun emoties.
Vicol legt uit dat de dataset laat zien, bijvoorbeeld, niet alleen dat twee mensen ruzie maken, maar waar ze het over hebben, en de redenen waarom ze ruzie maken, die afkomstig zijn van zowel visuele aanwijzingen als dialoog. Het team creëerde hun eigen tool om annotaties mogelijk te maken, die werd gedaan door een enkele annotator voor elke film.
"Alle clips in een film worden opeenvolgend geannoteerd, en de hele grafiek die bij elke clip hoort, wordt door één persoon gemaakt, die ons een coherente structuur geeft in elke grafiek, en tussen grafieken in de tijd, " hij zegt.
Met hun dataset van meer dan 7, 500 clips, de onderzoekers introduceren drie taken, legt Vicol uit. De eerste is het ophalen van video's, gebaseerd op het feit dat de grafieken zijn gebaseerd op de video's.
"Dus als je zoekt met behulp van een grafiek die zegt dat Forrest Gump ruzie heeft met iemand anders, en dat de emoties van de personages verdrietig en boos zijn, dan kun je de clip vinden, " hij zegt.
De tweede is interactie-ordening, die verwijst naar het bepalen van de meest plausibele volgorde van karakterinteracties. Bijvoorbeeld, hij legt uit als een personage een ander personage een cadeau zou geven, de persoon die het geschenk ontving, zou "dank u" zeggen.
"Normaal gesproken zou je niet zeggen 'dank je wel, ' en ontvang dan een cadeautje. Het is een manier om te benchmarken of we de semantiek van interacties vastleggen."
Hun laatste taak is het voorspellen van redenen op basis van de sociale context.
"Als we ons concentreren op één interactie, kunnen we de motivatie achter die interactie bepalen en waarom deze plaatsvond? Dus dat is eigenlijk proberen te voorspellen wanneer iemand tegen iemand anders schreeuwt, de eigenlijke zin die zou verklaren waarom, " hij zegt
Tapaswi zegt dat het einddoel is om gedrag aan te leren.
"Stel je bijvoorbeeld in één clip voor, de machine belichaamt in feite Jenny [uit de film Forrest Gump]. Wat is een passende handeling voor Jenny? In één scène, het is om Forrest aan te moedigen weg te lopen van pestkoppen. Dus we proberen machines gepast gedrag te laten leren."
"Gepast in de zin dat films toestaan, natuurlijk."

Screenshot:MIT CSAIL/VirtualHome:Huishoudelijke activiteiten simuleren via programma's
Hoe leert een robot huishoudelijke taken?
Onder leiding van onder leiding van Massachusetts Institute of Technology assistent-professor Antonio Torralba en U of T's Fidler, VirtualHome:huishoudelijke activiteiten simuleren via programma's, traint een virtuele menselijke agent met behulp van natuurlijke taal en een virtueel huis, zodat de robot niet alleen door taal kan leren, maar door te zien, legt U of T masterstudent computerwetenschappen Jiaman Li uit, een bijdragende auteur met U of T Ph.D. student informatica Wilson Tingwu Wang.
Li legt uit dat de actie op hoog niveau "werk op de computer" kan zijn en de beschrijving omvat:de computer aanzetten, ervoor zitten, typen op het toetsenbord en de muis pakken om te scrollen.
"Dus als we een mens deze beschrijving vertellen, 'werken op de computer, ' de mens kan deze handelingen net als de beschrijvingen uitvoeren. Maar als we robots deze beschrijving vertellen, hoe doen ze dat precies? De robot heeft dit gezond verstand niet. Het heeft zeer duidelijke stappen nodig, of programma's."
Omdat er geen dataset is die al deze kennis bevat, ze zegt dat de onderzoekers er een hebben gebouwd met behulp van een webinterface om de programma's te verzamelen, die de actienaam en de beschrijving bevatten.
"Toen hebben we een simulator gebouwd, zodat we een virtueel mens in een virtueel huis hebben die deze taken kan uitvoeren, " ze zegt.
Voor haar aandeel in het lopende project, Li gebruikt deep learning - een tak van machine learning die computers traint om te leren - om automatisch programma's uit tekst of video voor deze programma's te genereren.
Echter, het is geen gemakkelijke taak om elke actie in de simulator uit te voeren, zegt Li, aangezien de dataset resulteerde in meer dan 5, 000 programma's.
"Het is extreem moeilijk om alles wat je thuis doet te simuleren, en we zetten een stap in die richting door de meest voorkomende atoomacties zoals lopen, zitten, en ophalen, ' zegt Fidler.
"We hopen dat onze simulator zal worden gebruikt om robots complexe taken in een virtuele omgeving te trainen, voordat we naar de echte wereld gaan."
MovieGraphs werd gedeeltelijk ondersteund door de Natural Sciences and Engineering Research Council of Canada (NSERC) en VirtualHome wordt gedeeltelijk ondersteund door het NSERC COMputing Hardware for Emerging Intelligent Sensing Applications (COHESA) Network.
 Hoe bereid ik ureumoplossing voor?
Hoe bereid ik ureumoplossing voor? - Hoe bepaal je welk atoom te gebruiken als het centrale atoom
- Een hybride materiaal dat omkeerbaar schakelt tussen twee stabiele vaste toestanden
- Onderzoek toont aan hoe de hechting tussen implantaten en bot kan worden verbeterd
- Nieuwe fotogevoelige hydrogels ontwikkeld met oog voor biomedische toepassingen
- Bacteriemonsters die een eeuw geleden op Antarctica zijn verzameld, bijna identiek aan hedendaagse monsters
- Door klimaatverandering veroorzaakte mars van boomgrenzen gestopt door ongeschikte bodems:studie
- Brexit ontkurkt angst voor Franse wijnindustrie
- Klimaatconferentie Bangkok slaat alarm in aanloop naar VN-top
- Onderzoek beveelt compostering aan als een haalbare optie voor het beheer van vast afval in Sri Lanka
Hoofdlijnen
- Poema's die in de buurt van menselijke ontwikkeling leven, verbruiken meer energie
- Hoe een DNA-structuur te labelen
- Polygene eigenschappen: definitie, voorbeeld en feiten
- Hoeveel tijd kost het om een DNA-molecuul te repliceren?
- Squash-variëteit waarvan ooit werd gedacht dat ze uitgestorven was, gedijt goed op biologische boerderij
- Familiebanden Snapper leveren nieuw bewijs op over mariene reservaten
- Erfelijkheid: definitie, factor, soorten en voorbeelden
- Wat gebeurt er wanneer glucose een cel binnengaat?
- Verklaring van celspecialisatie
- Na Uber, Tesla-incidenten, is kunstmatige intelligentie te vertrouwen?

- Geautomatiseerde productiviteit en kwaliteitsbewaking op de bouwplaats
- Is de iPhone zo privé als Apple zegt? Mozilla zegt dat het kan

- Saoedische luchtvaartmaatschappij annuleert onrustige Boeing 737-bestelling voor Airbus

- NBC om prijs te geven, details over nieuwe Peacock-streamingservice


 Hoe te converteren van ponden naar kilogram
Hoe te converteren van ponden naar kilogram - Ryanair-voorzitter krijgt klap van aandeelhouder te midden van stakingen
- Luchtstabiele intrinsiek rekbare kleurconversielagen voor rekbare displays
- Wat veroorzaakt troposferische ozonvervuiling boven het noordelijke Tibetaanse plateau?
- Hoe WISE werkt
- Uitbreiding van de VCSEL-golflengtedekking naar het midden-infrarood
- Wetenschappers hebben net een nieuwe, mysterieuze zenuwcel blootgelegd in de menselijke hersenen
- Onderzoekers onderzoeken spintronica in grafeen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
