Wetenschap
Notatiesysteem stelt wetenschappers in staat polymeren gemakkelijker te communiceren
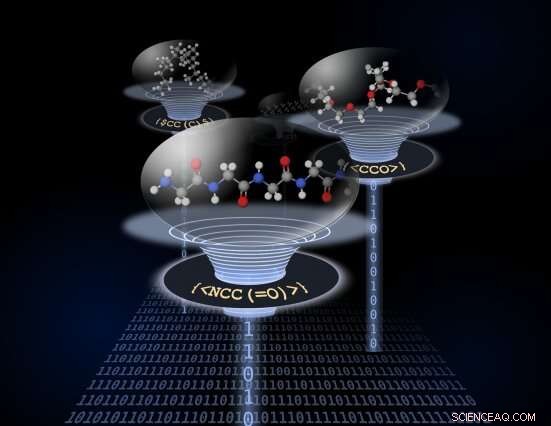
In BigSMILES, polymere fragmenten worden weergegeven door een lijst van herhalende eenheden tussen accolades. De chemische structuren van de herhalende eenheden zijn gecodeerd met de normale SMILES-syntaxis, maar met extra bindingsdescriptoren die specificeren hoe verschillende herhalende eenheden zijn verbonden om polymeren te vormen. Dit eenvoudige ontwerp van syntaxis zou de codering van macromoleculen over een breed scala van chemie mogelijk maken. Krediet:Tzyy-Shyang Lin
Het hebben van een compacte, maar robuust, structureel gebaseerd identificatie- of representatiesysteem voor moleculaire structuren is een sleutelfactor voor het efficiënt delen en verspreiden van resultaten binnen de onderzoeksgemeenschap. Dergelijke systemen leggen ook de essentiële basis voor machine learning en ander datagestuurd onderzoek. Hoewel er aanzienlijke vooruitgang is geboekt voor kleine moleculen, de polymeergemeenschap heeft geworsteld met het bedenken van een efficiënt representatiesysteem.
Voor kleine moleculen, het uitgangspunt is dat elke afzonderlijke chemische soort overeenkomt met een goed gedefinieerde chemische structuur. Dit geldt niet voor polymeren. Polymeren zijn intrinsiek stochastische moleculen die vaak ensembles zijn met een verdeling van chemische structuren. Deze moeilijkheid beperkt de toepasbaarheid van alle deterministische representaties die zijn ontwikkeld voor kleine moleculen. In een paper gepubliceerd op 12 september in ACS Centrale Wetenschap , onderzoekers van het MIT, Duke universiteit, en Northwestern University rapporteren een nieuw representatiesysteem dat de stochastische aard van polymeren aankan, genaamd BigSMILES.
"BigSMILES pakt een belangrijke uitdaging aan in de digitale weergave van polymeren, " legt Connor Coley Ph.D. '19 uit, co-auteur van het artikel. "Polymeren zijn bijna altijd ensembles van meerdere chemische structuren, gegenereerd door stochastische processen, dus we kunnen niet dezelfde strategieën gebruiken om hun structuren op te schrijven als voor kleine moleculen."
Co-auteurs zijn Coley; universitair hoofddocent chemische technologie Bradley D. Olsen aan het MIT; Warren K. Lewis hoogleraar chemische technologie Klavs F. Jensen aan het MIT; assistent-professor scheikunde Julia A. Kalow aan de Northwestern University; universitair hoofddocent chemie Jeremiah A. Johnson aan het MIT; William T. Miller hoogleraar scheikunde Stephen L. Craig aan de Duke University; afgestudeerde student Eliot Woods aan de Northwestern University; afgestudeerde student Zi Wang aan de Duke University; afgestudeerde student Wencong Wang aan het MIT; afgestudeerde student Haley K. Beech aan het MIT; gastonderzoeker Hidenobu Mochigase aan het MIT; en afgestudeerde student Tzyy-Shyang Lin aan het MIT.
Er zijn verschillende lijnnotaties om de moleculaire structuur te communiceren, waarbij het vereenvoudigde moleculaire invoerlijninvoersysteem (SMILES) het populairst is. SMILES wordt algemeen beschouwd als de meest voor mensen leesbare variant, met verreweg de breedste softwareondersteuning. In praktijk, SMILES biedt een eenvoudige set representaties die geschikt zijn als labels voor chemische gegevens en als geheugencompacte identificatie voor gegevensuitwisseling tussen onderzoekers. Als een op tekst gebaseerd systeem, SMILES past ook goed bij veel op tekst gebaseerde algoritmen voor machine learning. Deze eigenschappen hebben van SMILES een perfect hulpmiddel gemaakt om scheikundekennis om te zetten in een machinevriendelijke vorm, en het is met succes toegepast voor het voorspellen van eigenschappen van kleine moleculen en computerondersteunde syntheseplanning.
polymeren, echter, hebben weerstand geboden aan beschrijving door deze en andere structurele talen. Dit komt omdat de meeste structurele talen zoals SMILES zijn ontworpen om moleculen of chemische fragmenten te beschrijven die goed gedefinieerde atomaire grafieken zijn. Omdat polymeren stochastische moleculen zijn, ze hebben geen unieke SMILES-representaties. Dit ontbreken van een uniforme naamgevings- of identificatieconventie voor polymere materialen is een van de belangrijkste hindernissen die de ontwikkeling van het polymeerinformaticaveld vertragen. Terwijl baanbrekende inspanningen op het gebied van polymere informatica, zoals het Polymer Genome Project, hebben het nut van SMILES-extensies in polymeerinformatica aangetoond, de snelle ontwikkeling van nieuwe chemie en de snelle ontwikkeling van materiaalinformatica en datagedreven onderzoek maken de noodzaak van een universeel toepasbare naamgevingsconventie voor polymeren belangrijk.
"Machine learning biedt een enorme kans om chemische ontwikkeling en ontdekking te versnellen, " zegt Lin He, waarnemend adjunct-divisiedirecteur van de National Science Foundation (NSF) Division of Chemistry. "Deze uitgebreide tool om structuren te labelen, speciaal ontworpen om de unieke uitdagingen aan te gaan die inherent zijn aan polymeren, verbetert de doorzoekbaarheid van chemische structurele gegevens aanzienlijk, en brengt ons een stap dichter bij het benutten van de datarevolutie."
De onderzoekers hebben een nieuw structureel gebaseerde constructie gemaakt als aanvulling op de zeer succesvolle SMILES-representatie die de willekeurige aard van polymeermaterialen kan behandelen. Omdat polymeren moleculen met een hoog molecuulgewicht zijn, deze constructie heet BigSMILES. In BigSMILES, polymere fragmenten worden weergegeven door een lijst van herhalende eenheden tussen accolades. De chemische structuren van de herhalende eenheden zijn gecodeerd met de normale SMILES-syntaxis, maar met extra bindingsdescriptoren die specificeren hoe verschillende herhalende eenheden zijn verbonden om polymeren te vormen. Dit eenvoudige ontwerp van syntaxis zou de codering van macromoleculen over een breed scala van verschillende chemie mogelijk maken, inclusief homopolymeer, willekeurige copolymeren en blokcopolymeren, en een verscheidenheid aan moleculaire connectiviteit, variërend van lineaire polymeren tot ringpolymeren tot zelfs vertakte polymeren. Net als in SMILES, BigSMILES-representaties zijn compact, op zichzelf staande tekstreeksen.
"Het standaardiseren van de digitale weergave van polymeerstructuren met BigSMILES zal het delen en samenvoegen van polymeergegevens stimuleren, het verbeteren van de modelkwaliteit in de loop van de tijd en het versterken van de voordelen van het gebruik ervan, " zegt Jason Clark, de leidende materialen in open innovatie voor hernieuwbare chemicaliën en materialen in Braskem, die niet bij het onderzoek betrokken was. "BigSMILES is een belangrijke bijdrage aan het veld omdat het tegemoet komt aan de behoefte aan een flexibel systeem om complexe polymeerstructuren digitaal weer te geven."
Clark voegt toe, "De uitdagingen waarmee de kunststofindustrie in de context van de circulaire economie wordt geconfronteerd, beginnen bij de bron van grondstoffen en gaan door tot het einde van hun levensduur. Om deze uitdagingen aan te gaan, is het innovatieve ontwerp van op polymeren gebaseerde materialen nodig, die van oudsher te lijden heeft gehad van lange ontwikkelingscycli. Vooruitgang op het gebied van kunstmatige intelligentie en machine learning heeft laten zien dat het veelbelovend is om de ontwikkelingscyclus te versnellen voor toepassingen die gebruik maken van metaallegeringen en kleine organische moleculen, het motiveren van de kunststofindustrie om een parallelle aanpak te zoeken." Digitale representaties van BigSMILES vergemakkelijken de evaluatie van structuur-prestatierelaties door toepassing van datawetenschapsmethoden, hij zegt, uiteindelijk de convergentie versnellen naar de polymeerstructuren of -samenstellingen die de circulaire economie mogelijk maken.
"Er kan een veelvoud aan gecompliceerde polymeerstructuren worden geconstrueerd door de samenstelling van drie nieuwe basisoperatoren en originele SMILES-symbolen, " zegt Olsen, "Hele gebieden van de chemie, materiaal kunde, en techniek, inclusief polymeerwetenschap, biomaterialen, materiaal chemie, en veel van de biochemie, zijn gebaseerd op macromoleculen met stochastische structuren. Dit kan in principe worden gezien als een nieuwe taal voor het schrijven van de structuur van grote moleculen."
"Een van de dingen waar ik enthousiast over ben, is hoe de gegevensinvoer uiteindelijk rechtstreeks kan worden gekoppeld aan de synthetische methoden die worden gebruikt om een bepaald polymeer te maken, " zegt Craig, "Daarom, er is een mogelijkheid om daadwerkelijk meer informatie over de moleculen vast te leggen en te verwerken dan gewoonlijk beschikbaar is uit standaardkarakteriseringen. Als dit kan, het zal allerlei ontdekkingen mogelijk maken."
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Aurorale knetterende geluiden zijn gerelateerd aan de elektromagnetische resonanties van de aarde
Aurorale knetterende geluiden zijn gerelateerd aan de elektromagnetische resonanties van de aarde- Wat zijn twee verschillende habitats in een Prairie-ecosysteem?
- What Sounds Frighten Birds?
- Milieuvriendelijke composttoiletten brengen al verlichting in grote steden - vraag het maar aan de Londense kanaalschippers
- Modder op de oceaanbodem onthult geheimen van het Europese klimaat in het verleden
Hoofdlijnen
- Hoe maak je een Paper Mache Cell
- Difference Between Mutation & Genetic Drift
- Wat is de volgorde van de opeenvolging van gebeurtenissen bij de bevruchting van een ei?
- Herenbaarden dragen meer bacteriën dan hondenbont,
- Een benadering van het hele lichaam om chemosensorische cellen te begrijpen
- Chromosomale afwijkingen: wat is het?, Typen en oorzaken
- Chemische stoffen gebruikt in DNA-analyse
- Eerste uitgebreide inventarisatie van Neotropische slangen
- Het bestuderen van circadiane ritmes in planten en hun ziekteverwekkers kan leiden tot precisiegeneeskunde voor mensen
- Wetenschappers kijken voor het eerst naar het geometrische fase-effect in een chemische reactie

- Onderzoekers presenteren inzichten in zoektocht naar nieuwe antibiotica
- Licht en nanodeeltjes tegen kanker
- Onderzoekers koppelen kwartsmicrobalansmetingen aan internationaal meetsysteem

- Platina vormt nanobellen

 Waarom pikt een babyfoon video op van de spaceshuttle?
Waarom pikt een babyfoon video op van de spaceshuttle? - Het mysterie waarom nanodeeltjes van Ag-Rh-legeringen een vergelijkbare eigenschap hebben als Pd
- Onderzoek naar schone lucht zet giftige luchtverontreinigende stoffen om in industriële chemicaliën
- Boaty McBoatface keert terug naar huis met ongekende gegevens
- VN-agentschap:Bron van radioactiviteit in Scandinavië nog onduidelijk
- Goudverkenning met elektromagnetische 3D-methode met gecontroleerde bron
- Hoe Erosiesnelheid te berekenen
- Hagedis, schildpad tussen meer dan 100 nieuwe soorten gevonden in Mekong-regio
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
