Wetenschap
Wat zijn secundaire databases in bioinformatica?
Wat zijn secundaire databases?
Secundaire databases zijn collecties van vooraf berekende informatie afgeleid van primaire biologische gegevensbronnen. Ze zijn ontworpen om inzichten te geven en analyses te vergemakkelijken die moeilijk of tijdrovend zouden zijn om rechtstreeks uit onbewerkte gegevens te verkrijgen.
Key -kenmerken:
* afgeleid van primaire gegevens: Ze worden gebouwd door gegevens te verwerken en te integreren uit primaire databases (bijvoorbeeld sequentiedatabases zoals GenBank).
* Georganiseerd en gestructureerd: Informatie is georganiseerd in specifieke categorieën en formaten, waardoor het gemakkelijker is om te zoeken en te analyseren.
* informatie met toegevoegde waarde: Ze bieden annotaties, voorspellingen en interpretaties op basis van de primaire gegevens, die diepere inzichten bieden.
Voorbeelden van secundaire databases:
Hier is een selectie van secundaire databases, gecategoriseerd door hun focus:
* sequentie -analyse en annotatie:
* uniprot: Eiwitsequentie en functionele informatie.
* interpro: Eiwitfamilies, domeinen en functionele sites.
* Go (Gene Ontology): Hiërarchische classificatie van genfunctie.
* Kegg: Metabole paden en genfuncties.
* pfam: Eiwitfamilies.
* genoom en genexpressie:
* ensembl: Genoomassemblages, genannotaties en genexpressiegegevens.
* UCSC Genome Browser: Genomische datavisualisatie en exploratie.
* geo (genexpressie omnibus): Gegevensrepository van microarray en RNA -sequencing.
* arrayexpress: Microarray Data Repository.
* Eiwit-eiwit interacties en -netwerken:
* string: Eiwit-eiwit interacties en -netwerken.
* biogrid: Eiwit-eiwit interacties en genetische interacties.
* Drugsontdekking en doelidentificatie:
* Drugsbank: Uitgebreide database met drugsinformatie.
* chembl: Geneesmiddelachtige moleculen en hun biologische activiteiten.
* pubchem: Chemische structuren en biologische activiteiten.
* Vergelijkende genomics en evolutie:
* NCBI Taxonomy Browser: Hiërarchische classificatie van organismen.
* phylotree: Fylogenetische bomen van organismen.
* Treebase: Repository van fylogenetische bomen.
Voordelen van secundaire databases:
* tijdbesparende: Ze bieden voorverwerkte en georganiseerde informatie, waardoor onderzoekers tijd en moeite besparen.
* Verbeterde analyse: Annotaties, voorspellingen en relaties vergemakkelijken diepere analyses en begrip.
* Integratie van diverse gegevens: Secundaire databases integreren vaak informatie uit meerdere bronnen, wat een uitgebreid beeld biedt.
* gestandaardiseerde formaten: Gegevens worden meestal gepresenteerd in gestandaardiseerde formaten, die consistentie en compatibiliteit bevorderen.
Het kiezen van de juiste database:
De keuze van de secundaire database hangt af van uw specifieke onderzoeksvraag en gegevenstype. Overweeg het volgende:
* Gegevenstype: Eiwitsequenties, genomische gegevens, genexpressie, etc.
* Scope: Specifieke organismen, paden, ziekten of bredere biologische domeinen.
* informatie nodig: Annotaties, voorspellingen, interacties, enz.
* Gegevenskwaliteit en betrouwbaarheid: Zorg ervoor dat de database goed onderhouden is en nauwkeurige informatie biedt.
Samenvattend:
Secundaire databases zijn essentieel voor bioinformatica -onderzoek. Ze bieden waardevolle vooraf berekende informatie, annotaties en inzichten, waardoor efficiënte gegevensanalyse en begrip worden vergemakkelijkt. Kies de juiste database op basis van uw onderzoeksbehoeften en gebruik het potentieel ervan voor zinvolle ontdekkingen.
 Wanneer wordt gezegd dat een samengestelde formule -formule molecuul is?
Wanneer wordt gezegd dat een samengestelde formule -formule molecuul is? - Welke oplosmiddelen kunnen KBR-celvensters beschadigen in IR-Spectroscopy?
- Hoe zijn de onderwerpen ionenvorming en periodieke trends met elkaar verbonden?
- Wanneer de moleculen in een lichaam met verhoogde snelheid bewegen, is het mogelijk dat van gas naar vloeibaar of vast gas verandert?
- Welke groep verbinding kan worden geïdentificeerd met jodium in dunne laagchromatografie?
- Wat is klimaat?
- Het voortplantingssysteem van vissen
- Wat zijn de namen van groepswetenschap die zich bezighouden met de aarde en zijn buren in de ruimte?
- Heb je je ooit afgevraagd wat ons curriculum kinderen leert over klimaatverandering? Het antwoord is niet veel
- Kleine bomen hebben een grote impact in de strijd tegen klimaatverandering
Hoofdlijnen
- Wat transporteert eiwitten in de cel?
- Verstikt, gewurgd en verdronken. Hoe plastic zakken met ballonnen zeedieren doden
- Wat zijn de namen van in het lichaam?
- Hoe orgaantransplantaties werken
- Hoe een 'vuurvlieg'-worm te construeren
- Wat is een subproces van natuurlijke selectie?
- Wat is de hybridisatie van acetonitril?
- Wat regelt andere klieren en lichaamsgroei?
- Waarom wordt voedingsagar gebruikt voor bacteriën en geen schimmels?
- Turkije bevrijdt 7, 500 illegaal opgejaagde kikkers de rivier in

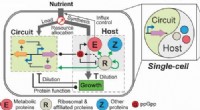
- Team ontwikkelt strategie voor gencircuitontwerp om synthetische biologie te bevorderen
- Albatrossen vanuit de ruimte:natuurdetectives nodig

- Hoe Body Dysmorphic Disorder werkt

- Kleine rode dieren schieten in het donker onder het ijs van een bevroren meer in Quebec

 Hoe beïnvloeden zonnevlekken het klimaat?
Hoe beïnvloeden zonnevlekken het klimaat? - Beschrijf de structuur van een mosplant
- Inches en ponden omzetten in centimeters en kilogram
- Wat is een zuurstofbehoudapparaat?
- Wat zijn de verschillende manieren waarop mineralen kunnen worden gewonnen?
- Hoe breng je NO2 plus H2O-hno3 nee in evenwicht?
- In welk proces gebruikt de cel een blaasje om moleculen naar cel te verplaatsen?
- Wat is de status van de droogte in Californië terwijl hittegolf en bosbranden de staat overspoelen?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap & Ontdekkingen © https://nl.scienceaq.com
