Wetenschap
Vraag en antwoord:Hoe je duurzame producten sneller kunt maken met kunstmatige intelligentie en automatisering
Door het genoom van planten en micro-organismen te modificeren, kunnen synthetisch biologen biologische systemen ontwerpen die aan een specificatie voldoen, zoals het produceren van waardevolle chemische verbindingen, het gevoelig maken van bacteriën voor licht, of het programmeren van bacteriële cellen om kankercellen binnen te dringen.
Dit wetenschapsgebied, hoewel nog maar een paar decennia oud, heeft grootschalige productie van medische medicijnen mogelijk gemaakt en de mogelijkheid gecreëerd om aardolievrije chemicaliën, brandstoffen en materialen te vervaardigen. Het lijkt erop dat biologisch vervaardigde producten niet meer weg te denken zijn en dat we er steeds meer op zullen vertrouwen naarmate we afstand nemen van traditionele, koolstofintensieve productieprocessen.
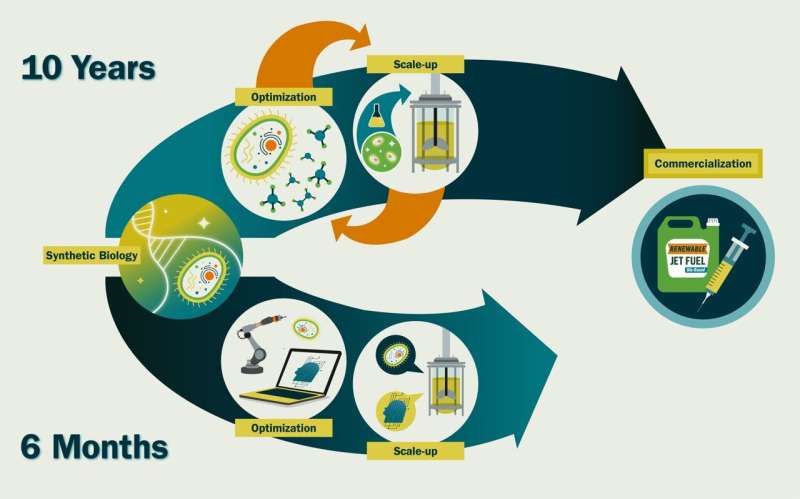
Maar er is één grote hindernis:synthetische biologie is arbeidsintensief en traag. Van het begrijpen van de genen die nodig zijn om een product te maken, tot het goed laten functioneren ervan in een gastheerorganisme, en uiteindelijk tot het laten gedijen van dat organisme in een grootschalige industriële omgeving, zodat het voldoende producten kan produceren om aan de marktvraag te voldoen, de ontwikkeling van een bioproductieproces kan vele jaren en vele miljoenen dollars aan investeringen vergen.
Héctor García Martín, stafwetenschapper op de afdeling Biowetenschappen van het Lawrence Berkeley National Laboratory (Berkeley Lab), werkt aan het versnellen en verfijnen van dit R&D-landschap door kunstmatige intelligentie en de wiskundige hulpmiddelen toe te passen die hij tijdens zijn opleiding als natuurkundige beheerste.
We spraken met hem om te leren hoe AI, op maat gemaakte algoritmen, wiskundige modellering en robotautomatisering samen kunnen komen als een som die groter is dan de delen, en een nieuwe benadering voor synthetische biologie kunnen bieden.
Waarom duurt het onderzoek naar synthetische biologie en de opschaling van processen nog steeds zo lang?
Ik denk dat de hindernissen die we in de synthetische biologie tegenkomen bij het creëren van hernieuwbare producten allemaal voortkomen uit een zeer fundamentele wetenschappelijke tekortkoming:ons onvermogen om biologische systemen te voorspellen. Veel synthetisch biologen zijn het misschien niet met mij eens en wijzen op de moeilijkheid om processen op te schalen van milliliter naar duizenden liters, of op de strijd om opbrengsten te verkrijgen die hoog genoeg zijn om commerciële levensvatbaarheid te garanderen, of zelfs op de moeizame zoektocht in de literatuur naar moleculen met de juiste eigenschappen om te synthetiseren. En dat is allemaal waar.
Maar ik geloof dat ze allemaal een gevolg zijn van ons onvermogen om biologische systemen te voorspellen. Stel dat er iemand met een tijdmachine (of God, of je favoriete alwetende wezen) komt en ons een perfect ontworpen DNA-sequentie geeft om in een microbe te stoppen, zodat deze de optimale hoeveelheid van ons gewenste doelmolecuul (bijvoorbeeld een biobrandstof) zou creëren. op grote schaal (duizenden liters).
Het zou een paar weken duren om het te synthetiseren en in een cel te transformeren, en drie tot zes maanden om het op commerciële schaal te laten groeien. Het verschil tussen die 6,5 maanden en de ongeveer 10 jaar die we nu nodig hebben, is de tijd die we besteden aan het verfijnen van genetische sequenties en kweekomstandigheden, bijvoorbeeld door de expressie van een bepaald gen te verlagen om de opbouw van toxische stoffen te voorkomen of door het zuurstofniveau te verhogen voor snellere groei. —omdat we niet weten hoe deze het celgedrag zullen beïnvloeden.
Als we dat nauwkeurig zouden kunnen voorspellen, zouden we ze veel efficiënter kunnen ontwikkelen. En zo gebeurt dat ook in andere disciplines. We ontwerpen geen vliegtuigen door nieuwe vliegtuigvormen te bouwen en ermee te vliegen om te zien hoe goed ze werken. Onze kennis van vloeistofdynamica en bouwtechniek is zo goed dat we het effect dat zoiets als een rompverandering op de vlucht zal hebben, kunnen simuleren en voorspellen.
Hoe versnelt kunstmatige intelligentie deze processen? Kun je enkele voorbeelden geven van recent werk?
We gebruiken machinaal leren en kunstmatige intelligentie om de voorspellende kracht te bieden die synthetische biologie nodig heeft. Onze aanpak omzeilt de noodzaak om de betrokken moleculaire mechanismen volledig te begrijpen, waardoor er veel tijd wordt bespaard. Dit roept echter wel enige argwaan op bij traditionele moleculair biologen.
Normaal gesproken moeten deze tools worden getraind op enorme datasets, maar we hebben gewoon niet zoveel gegevens in de synthetische biologie als in de astronomie. Daarom hebben we unieke methoden ontwikkeld om die beperking te overwinnen. We hebben bijvoorbeeld machinaal leren gebruikt om te voorspellen welke promoters (DNA-sequenties die genexpressie mediëren) we moeten kiezen om maximale productiviteit te verkrijgen.
We hebben ook machinaal leren gebruikt om de juiste groeimedia voor een optimale productie te voorspellen, om de metabolische dynamiek van cellen te voorspellen, om de opbrengsten van duurzame precursoren voor vliegtuigbrandstof te verhogen, en om te voorspellen hoe functionerende polyketidesynthasen (enzymen die een enorme verscheidenheid aan stoffen kunnen produceren) kunnen worden ontwikkeld. van waardevolle moleculen, maar het is berucht dat ze moeilijk voorspelbaar te construeren zijn).
In veel van deze gevallen moesten we de wetenschappelijke experimenten automatiseren om de grote hoeveelheden hoogwaardige gegevens te verkrijgen die we nodig hebben om AI-methoden echt effectief te laten zijn. We hebben bijvoorbeeld robotachtige vloeistofbehandelaars gebruikt om nieuwe groeimedia voor microben te creëren en hun effectiviteit te testen, en we hebben microfluïdische chips ontwikkeld om te proberen genetische bewerking te automatiseren. Ik werk actief samen met anderen in het Lab (en externe medewerkers) om zelfrijdende laboratoria voor synthetische biologie te creëren.
Doen veel andere groepen in de VS soortgelijk werk? Denkt u dat dit veld in de loop van de tijd groter zal worden?
Het aantal onderzoeksgroepen met expertise op het snijvlak van AI, synthetische biologie en automatisering is zeer klein, vooral buiten de industrie. Ik zou Philip Romero van de Universiteit van Wisconsin en Huimin Zhao van de Universiteit van Illinois Urbana-Champaign willen benadrukken. Maar gezien het potentieel van deze combinatie van technologieën om een enorme maatschappelijke impact te hebben (bijvoorbeeld bij het bestrijden van klimaatverandering of het produceren van nieuwe therapeutische medicijnen ), denk ik dat dit veld in de nabije toekomst erg snel zal groeien.
Ik heb deelgenomen aan verschillende werkgroepen, commissies en workshops, waaronder een bijeenkomst van deskundigen voor de National Security Commission on Emerging Biotechnology, die de mogelijkheden op dit gebied bespraken en rapporten opstellen met actieve aanbevelingen.
Welke vooruitgang verwacht u in de toekomst als u dit werk voortzet?
Ik denk dat een intensieve toepassing van AI en robotica/automatisering op synthetische biologie de tijdlijnen van synthetische biologie ~20-voudig kan versnellen. We zouden in ~6 maanden een nieuw commercieel levensvatbaar molecuul kunnen creëren in plaats van ~10 jaar. Dit is hard nodig als we een circulaire bio-economie mogelijk willen maken:het duurzame gebruik van hernieuwbare biomassa (koolstofbronnen) om energie en tussen- en eindproducten op te wekken.
Er zijn naar schatting 3.574 chemicaliën met een hoog productievolume (chemicaliën die de VS produceert of importeert in hoeveelheden van minstens 1 miljoen pond per jaar) die tegenwoordig uit de petrochemie komen. Een biotechnologiebedrijf genaamd Genencor had 575 mensjaren nodig om een hernieuwbare route te ontwikkelen voor de productie van een van deze veelgebruikte chemicaliën, 1,3-propaandiol, en dit is een typisch cijfer.
Als we aannemen dat het zo lang zou duren om een bioproductieproces te ontwerpen dat het aardolieraffinageproces voor elk van deze duizenden chemicaliën zou vervangen, zouden we ongeveer 2.000.000 persoonsjaren nodig hebben. Als we alle naar schatting ongeveer 5.000 Amerikaanse synthetische biologen (laten we zeggen 10% van alle biologische wetenschappers in de VS, en dat is een overschatting) hieraan zouden laten werken, zou het ongeveer 371 jaar duren om die circulaire bio-economie te creëren.
Omdat de temperatuurafwijking elk jaar groter wordt, hebben we niet echt 371 jaar. Deze cijfers zijn duidelijk snelle berekeningen, maar ze geven een idee van de orde van grootte als we het huidige pad voortzetten. We hebben een disruptieve aanpak nodig.
Bovendien zou deze aanpak het nastreven van ambitieuzere doelen mogelijk maken die met de huidige aanpak niet haalbaar zijn, zoals:het engineeren van microbiële gemeenschappen voor milieudoeleinden en de menselijke gezondheid, biomaterialen, bio-engineered weefsels, enz.
Hoe is Berkeley Lab een unieke omgeving om dit onderzoek te doen?
Berkeley Lab heeft de afgelopen twintig jaar sterk geïnvesteerd in synthetische biologie en beschikt over aanzienlijke expertise op dit gebied. Bovendien is Berkeley Lab de thuisbasis van ‘grote wetenschap’:multidisciplinaire wetenschap met grote teams, en
Ik denk dat dit op dit moment de juiste weg is voor de synthetische biologie. Er is veel bereikt in de afgelopen zeventig jaar sinds de ontdekking van DNA via de traditionele moleculair-biologische benaderingen van één onderzoeker, maar ik denk dat de uitdagingen die voor ons liggen een multidisciplinaire aanpak vereisen waarbij synthetisch biologen, wiskundigen, elektrotechnici, computerwetenschappers, moleculair biologen en chemische ingenieurs betrokken zijn. , enz. Ik denk dat Berkeley Lab de natuurlijke plek zou moeten zijn voor dat soort werk.
Vertel ons iets over je achtergrond. Wat inspireerde je om wiskundige modellen van biologische systemen te bestuderen?
Al heel vroeg was ik erg geïnteresseerd in wetenschap, met name biologie en natuurkunde. Ik herinner me nog levendig dat mijn vader me vertelde over het uitsterven van dinosaurussen. Ik herinner me ook dat mij werd verteld dat er in de Perm-periode gigantische libellen waren (~75 cm) omdat het zuurstofniveau veel hoger was dan nu (~30% versus 20%) en insecten hun zuurstof door diffusie krijgen, niet door longen. Grotere zuurstofniveaus maakten dus veel grotere insecten mogelijk.
Ik was ook gefascineerd door het vermogen dat wiskunde en natuurkunde ons bieden om de dingen om ons heen te begrijpen en te ontwerpen. Natuurkunde was mijn eerste keuze, omdat de manier waarop biologie in die tijd werd onderwezen veel meer memoriseren dan kwantitatieve voorspellingen met zich meebracht. Maar ik heb er altijd interesse in gehad om te leren welke wetenschappelijke principes hebben geleid tot het leven op aarde zoals we het nu zien.
Ik ben gepromoveerd in de theoretische natuurkunde, waarin ik Bose-Einstein-condensaten (een toestand van materie die ontstaat wanneer deeltjes die bosonen worden genoemd, een groep waartoe fotonen behoren, zich op een temperatuur van bijna het absolute nulpunt bevinden) heb gesimuleerd en gebruik heb gemaakt van padintegraal Monte Carlo-technieken, maar het leverde ook een verklaring op voor een meer dan 100 jaar oude puzzel in de ecologie:waarom is het aantal soorten in een gebied schaalbaar met een ogenschijnlijk universele machtswet, afhankelijk van het gebied (S=cA z , z=0,25)? Vanaf dat moment had ik aan de natuurkunde kunnen blijven werken, maar ik dacht dat ik meer impact kon maken door voorspellende capaciteiten toe te passen op de biologie.
Om deze reden waagde ik een grote gok voor een doctoraat in de natuurkunde. en accepteerde een postdoc bij het DOE Joint Genome Institute in metagenomics – het sequencen van microbiële gemeenschappen om hun onderliggende cellulaire activiteiten te ontrafelen – in de hoop voorspellende modellen voor microbiomen te ontwikkelen. Ik kwam er echter achter dat de meeste microbiële ecologen een beperkte interesse hadden in voorspellende modellen, dus begon ik te werken in de synthetische biologie, die voorspellingsmogelijkheden nodig heeft omdat het tot doel heeft cellen volgens een specificatie te engineeren.
Mijn huidige functie stelt mij in staat mijn wiskundige kennis te gebruiken om te proberen cellen op een voorspelbare manier te engineeren om biobrandstoffen te produceren en de klimaatverandering te bestrijden. We hebben veel vooruitgang geboekt en enkele van de eerste voorbeelden van AI-gestuurde synthetische biologie opgeleverd, maar er is nog veel werk aan de winkel om de biologie voorspelbaar te maken.