Wetenschap
IBM-wetenschappers demonstreren in-memory computing met 1 miljoen apparaten voor toepassingen in AI

Een miljoen processen zijn toegewezen aan de pixels van een 1000 × 1000 pixels zwart-wit schets van Alan Turing. De pixels worden in- en uitgeschakeld in overeenstemming met de momentane binaire waarden van de processen. Krediet:Natuurcommunicatie
"In-memory computing" of "computationeel geheugen" is een opkomend concept dat de fysieke eigenschappen van geheugenapparaten gebruikt voor zowel het opslaan als het verwerken van informatie. Dit is in tegenspraak met de huidige systemen en apparaten van von Neumann, zoals standaard desktopcomputers, laptops en zelfs mobiele telefoons, die gegevens heen en weer pendelen tussen het geheugen en de rekeneenheid, waardoor ze langzamer en minder energiezuinig worden.
Vandaag, IBM Research kondigt aan dat zijn wetenschappers hebben aangetoond dat een niet-gecontroleerd algoritme voor machinaal leren, draait op een miljoen Phase Change Memory (PCM) apparaten, met succes tijdelijke correlaties gevonden in onbekende gegevensstromen. In vergelijking met state-of-the-art klassieke computers, deze prototypetechnologie zal naar verwachting 200x verbeteringen opleveren in zowel snelheid als energie-efficiëntie, waardoor het zeer geschikt is voor het mogelijk maken van ultradichte, laag vermogen, en massaal parallelle computersystemen voor toepassingen in AI.
De onderzoekers gebruikten PCM-apparaten gemaakt van een germanium-antimoontelluridelegering, die is gestapeld en ingeklemd tussen twee elektroden. Wanneer de wetenschappers een kleine elektrische stroom op het materiaal toepassen, ze verwarmen het, die zijn toestand verandert van amorf (met een ongeordende atomaire rangschikking) naar kristallijn (met een geordende atomaire configuratie). De IBM-onderzoekers hebben de kristallisatiedynamiek gebruikt om ter plekke berekeningen uit te voeren.
"Dit is een belangrijke stap voorwaarts in ons onderzoek naar de fysica van AI, die nieuwe hardwarematerialen verkent, apparaten en architecturen, " zegt Dr. Evangelos Eleftheriou, een IBM Fellow en co-auteur van het papier. "Terwijl de CMOS-schaalwetten stuk gaan vanwege technologische beperkingen, een radicale afwijking van de dichotomie processor-geheugen is nodig om de beperkingen van de hedendaagse computers te omzeilen. Gezien de eenvoud, hoge snelheid en lage energie van onze in-memory computing-aanpak, het is opmerkelijk dat onze resultaten zo vergelijkbaar zijn met onze klassieke benchmarkbenadering op een von Neumann-computer."
De details worden uitgelegd in hun artikel dat vandaag in het peer-review tijdschrift verschijnt Natuurcommunicatie . Om de technologie te demonstreren, de auteurs kozen twee op tijd gebaseerde voorbeelden en vergeleken hun resultaten met traditionele machine learning-methoden zoals k-means clustering:
- Gesimuleerde gegevens:een miljoen binaire (0 of 1) willekeurige processen georganiseerd op een 2D-raster op basis van een 1000 x 1000 pixel, zwart en wit, profieltekening van de beroemde Britse wiskundige Alan Turing. De IBM-wetenschappers lieten de pixels vervolgens met dezelfde snelheid aan en uit knipperen, maar de zwarte pixels gingen op een zwak gecorreleerde manier aan en uit. Dit betekent dat wanneer een zwarte pixel knippert, er is een iets grotere kans dat een andere zwarte pixel ook knippert. De willekeurige processen werden toegewezen aan een miljoen PCM-apparaten, en een eenvoudig leeralgoritme werd geïmplementeerd. Met elke knipper, de PCM-array geleerd, en de PCM-apparaten die overeenkomen met de gecorreleerde processen gingen naar een hoge geleidingstoestand. Op deze manier, de geleidbaarheidskaart van de PCM-apparaten herschept de tekening van Alan Turing. (zie afbeelding hierboven)
- Real-World Data:actuele neerslaggegevens, verzameld over een periode van zes maanden van 270 weerstations in de VS in intervallen van een uur. Als het binnen het uur regent, het kreeg het label "1" en als het niet "0" was. Klassieke k-means clustering en de in-memory computing-benadering waren het eens over de classificatie van 245 van de 270 weerstations. In-memory computing classificeerde 12 stations als niet-gecorreleerd die waren gemarkeerd als gecorreleerd door de k-means-clusteringsbenadering. evenzo, de in-memory computing-benadering classificeerde 13 stations als gecorreleerd die waren gemarkeerd als ongecorreleerd door k-means clustering.
"Het geheugen is tot nu toe gezien als een plaats waar we alleen informatie opslaan. Maar in dit werk, we laten op afdoende wijze zien hoe we de fysica van deze geheugenapparaten kunnen benutten om ook een nogal hoogstaand computationeel primitief uit te voeren. Het resultaat van de berekening wordt ook opgeslagen in de geheugenapparaten, en in die zin is het concept losjes geïnspireerd door hoe het brein rekent", zei Dr. Abu Sebastian, verkennend geheugen en cognitieve technologieën wetenschapper, IBM Research en hoofdauteur van het artikel.
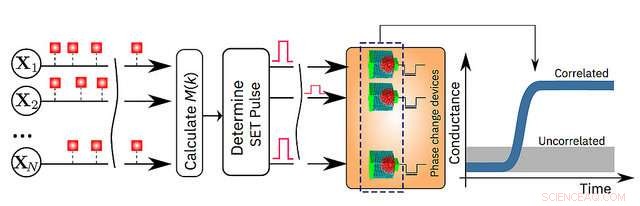
Een schematische illustratie van het in-memory computing-algoritme. Krediet:IBM Research

Hoofdlijnen
- Deze dans wordt uitgevoerd:honderden mannelijke kikkersoorten veranderen van kleur rond de paringstijd
- Waarom vallen mensen steeds uit?
- Slimme app gebruikt smartphonecamera om plantensoorten te identificeren
- Septate vs. Non-Septate Hyphae
- Cellulaire ademhaling in ontkiemende zaden
- Onderzoekers voeren een nieuwe analyse van het tarwemicrobioom uit onder vier managementstrategieën
- Vijf soorten genverbindingsmechanismen
- Celstructuren en hun drie belangrijkste functies
- Factoren die betrokken zijn bij celdifferentiatie
- Niet-invasieve intracellulaire thermometer met fluorescerende eiwitten gemaakt
- Risico's van nanomaterialen onder de loep

- Kankervaccin verpakt in minuscule deeltjes
- Röntgenpulsen onthullen voor het eerst vrije nanodeeltjes in 3D

- Nieuwe zelfherstellende materialen ontwikkeld voor testen op het internationale ruimtestation ISS


 Hoe Simple Vs. uit te leggen Gefractioneerde destillatie
Hoe Simple Vs. uit te leggen Gefractioneerde destillatie - Moleculair dunne interface tussen polymeren voor efficiënt koolstofdioxide-opvangmembraan
- De nadelen van wetland natuurreservaten
- China's ruimtedroom:een lange mars naar de maan en verder
- Niet zo lang geleden, steden waren uitgehongerd voor bomen
- Hoe kan de geneeskunde de loonkloof tussen mannen en vrouwen dichten?
- Studie onthult onzekerheid over hoeveel koolstof de oceaan in de loop van de tijd absorbeert
- NIST polijstmethode voor het maken van kleine diamantmachines
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | French | Spanish |

-
Wetenschap © https://nl.scienceaq.com
