Wetenschap
Videosoftwaresysteem synchroniseert lippen met andere talen
 Terwijl de huidige vertaalsystemen alleen vertaalde spraakuitvoer of tekstuele ondertitels voor video-inhoud kunnen genereren, het Automatic Face-to-Face Translation-protocol kan de visuele, zodat de stemstijl en lipbeweging overeenkomen met de doeltaal. Prajwal Renukanand
Terwijl de huidige vertaalsystemen alleen vertaalde spraakuitvoer of tekstuele ondertitels voor video-inhoud kunnen genereren, het Automatic Face-to-Face Translation-protocol kan de visuele, zodat de stemstijl en lipbeweging overeenkomen met de doeltaal. Prajwal Renukanand Een team van onderzoekers in India heeft een systeem bedacht om woorden in een andere taal te vertalen en het te laten lijken alsof de lippen van een spreker synchroon met die taal bewegen.
Automatische face-to-face vertaling, zoals beschreven in dit artikel van oktober 2019, is een vooruitgang ten opzichte van tekst-naar-tekst of spraak-naar-spraak vertaling, omdat het niet alleen spraak vertaalt, maar biedt ook een lip-gesynchroniseerd gezichtsbeeld.
Om te begrijpen hoe dit werkt, bekijk de demonstratievideo hieronder, gemaakt door de onderzoekers. Om 6.38 uur, zie je een videoclip van wijlen prinses Diana in een interview uit 1995 met journalist Martin Bashir, uitleggen, "Ik zou graag een koningin van de harten van mensen zijn, in de harten van mensen, maar ik zie mezelf niet als een koningin van dit land."
Een moment later, je zult haar hetzelfde citaat in het Hindi zien uitspreken - met bewegende lippen, alsof ze die taal echt sprak.
"Effectief communiceren over taalbarrières is altijd een grote ambitie geweest van mensen over de hele wereld, " Prajwal KR, een afgestudeerde student in computerwetenschappen aan het International Institute of Information Technology in Hyderabad, Indië, uitleg per e-mail. Hij is de hoofdauteur van het artikel, samen met zijn collega Rudrabha Mukhopadhyay.
"Vandaag, het internet staat vol met pratende gezichtsvideo's:YouTube (300 uur geüpload per dag), online lezingen, videovergaderen, films, tv-programma's en ga zo maar door, "Prajwal, die zijn voornaam draagt, schrijft. "De huidige vertaalsystemen kunnen alleen een vertaalde spraakuitvoer of tekstuele ondertitels genereren voor dergelijke video-inhoud. Ze verwerken de visuele component niet. Als gevolg hiervan, de vertaalde spraak wanneer deze over de video wordt gelegd, de lipbewegingen zouden niet synchroon lopen met de audio.
"Dus, we bouwen voort op de spraak-naar-spraak-vertaalsystemen en stellen een pijplijn voor die een video kan opnemen van een persoon die in een brontaal spreekt en een video kan uitvoeren van dezelfde spreker die in een doeltaal spreekt, zodat de stemstijl en lipbewegingen overeenkomen de spraak in de doeltaal, " zegt Prajwal. "Door dit te doen, het vertaalsysteem wordt holistisch, en zoals blijkt uit onze menselijke evaluaties in dit artikel, verbetert de gebruikerservaring aanzienlijk bij het maken en consumeren van vertaalde audiovisuele inhoud."
Face-to-face vertalen vereist een aantal complexe prestaties. "Gezien een video van een sprekende persoon, we moeten twee belangrijke informatiestromen vertalen:de visuele en de spraakinformatie, " legt hij uit. Dat doen ze in een aantal grote stappen. "Het systeem transcribeert eerst de zinnen in de spraak met behulp van automatische spraakherkenning (ASR). Dit is dezelfde technologie die wordt gebruikt in spraakassistenten (Google Assistant, bijvoorbeeld) op mobiele apparaten." Vervolgens de getranscribeerde zinnen worden vertaald naar de gewenste taal met behulp van Neural Machine Translation-modellen, en vervolgens wordt de vertaling omgezet in gesproken woorden met een tekst-naar-spraak-synthesizer - dezelfde technologie die digitale assistenten gebruiken.
Eindelijk, een technologie genaamd LipGAN corrigeert de lipbewegingen in de originele video om overeen te komen met de vertaalde spraak.
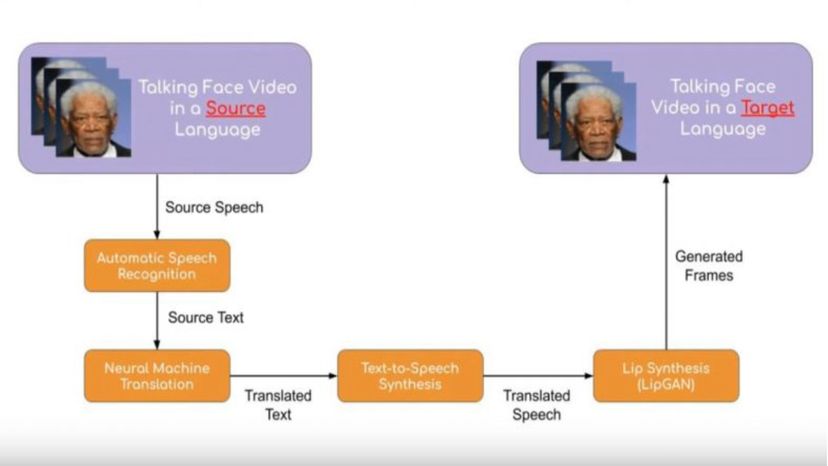 Hoe spraak van initiële invoer naar gesynchroniseerde uitvoer gaat. Prajwal Renukanand
Hoe spraak van initiële invoer naar gesynchroniseerde uitvoer gaat. Prajwal Renukanand "Dus, we krijgen ook een volledig vertaalde video met lipsynchronisatie, ' legt Prajwal uit.
"LipGAN is de belangrijkste nieuwe bijdrage van ons artikel. Dit is wat de visuele modaliteit in beeld brengt. Het is het belangrijkste omdat het de lipsynchronisatie in de uiteindelijke video corrigeert, wat de gebruikerservaring aanzienlijk verbetert."
De bedoeling is geen bedrog, Maar kennis delen
Een artikel, gepubliceerd op 24 januari 2020 in Nieuwe Wetenschapper, beschreef de doorbraak als een "deepfake, " een term voor video's waarin gezichten zijn verwisseld of digitaal gewijzigd met behulp van kunstmatige intelligentie, vaak om een misleidende indruk te wekken, zoals dit BBC-verhaal heeft uitgelegd. Maar Prajwal beweert dat dit een onjuiste weergave is van face-to-face vertalen, die niet bedoeld is om te misleiden, maar eerder om vertaalde spraak gemakkelijker te volgen te maken.
"Ons werk is voornamelijk gericht op het verbreden van de reikwijdte van de bestaande vertaalsystemen om video-inhoud te verwerken, " legt hij uit. "Dit is software die is gemaakt met de motivatie om de gebruikerservaring te verbeteren en taalbarrières in video-inhoud te slechten. Het opent een zeer breed scala aan toepassingen en verbetert de toegankelijkheid van miljoenen video's online."
De grootste uitdaging bij het maken van face-to-face vertaalwerk was de module voor het genereren van gezichten. "De huidige methoden om video's met lipsynchronisatie te maken, waren niet in staat om gezichten met de gewenste poses te genereren, waardoor het moeilijk wordt om het gegenereerde gezicht in de doelvideo te plakken, " zegt Prajwal. "We hebben een 'pose prior' opgenomen als input voor ons LipGAN-model, en als een resultaat, we kunnen een nauwkeurig lip-gesynchroniseerd gezicht genereren in de gewenste doelhouding die naadloos kan worden opgenomen in de doelvideo."
De onderzoekers stellen zich voor dat Face-to-Face Translation wordt gebruikt bij het vertalen van films en videogesprekken tussen twee mensen die elk een andere taal spreken. "Het laten zingen/spreken van digitale karakters in animatiefilms wordt ook gedemonstreerd in onze video, ’ merkt Prajwal op.
In aanvulling, hij voorziet dat het systeem wordt gebruikt om studenten over de hele wereld te helpen online collegevideo's in andere talen te begrijpen. "Miljoenen anderstalige studenten over de hele wereld begrijpen de uitstekende educatieve inhoud die online beschikbaar is niet, omdat ze in het Engels zijn, " hij legt uit.
"Verder, in een land als India met 22 officiële talen, ons systeem kan in de toekomst, vertaal tv-nieuwsinhoud in verschillende lokale talen met nauwkeurige lipsynchronisatie van de nieuwsankers. De lijst met toepassingen is dus van toepassing op elk soort video-inhoud met pratende gezichten, dat moet in alle talen toegankelijker worden gemaakt."
Hoewel Prajwal en zijn collega's van plan zijn om hun doorbraak op een positieve manier te gebruiken, het vermogen om buitenlandse woorden in de mond van een spreker te leggen, betreft een prominente Amerikaanse cyberbeveiligingsexpert, die vreest dat gewijzigde video's steeds moeilijker te detecteren zullen worden.
"Als je naar de video kijkt, je kunt het zien als je goed kijkt, de mond is wat wazig, " zegt Anne Toomey McKenna, een Distinguished Scholar of Cyberlaw and Policy aan de Dickinson Law van Penn State University, en een professor aan het Institute for Computational and Data Sciences van de universiteit, in een e-mailgesprek. "Dat zal verder worden geminimaliseerd naarmate de algoritmen blijven verbeteren. Dat zal steeds minder waarneembaar worden voor het menselijk oog."
McKenna bijvoorbeeld, stelt zich voor hoe een gewijzigde video van MSNBC-commentator Rachel Maddow kan worden gebruikt om verkiezingen in andere landen te beïnvloeden, door "informatie door te geven die onnauwkeurig is en het tegenovergestelde is van wat ze zei."
Prajwal maakt zich ook zorgen over mogelijk misbruik van gewijzigde video's, maar denkt dat er voorzorgsmaatregelen kunnen worden genomen om dergelijke scenario's te voorkomen, en dat het positieve potentieel voor een groter internationaal begrip opweegt tegen de risico's van automatische face-to-face vertaling. (Aan de gunstige kant, deze blogpost wil de toespraak van Greta Thunberg op de VN-klimaattop in september 2019 vertalen in verschillende talen die in India worden gebruikt.)
"Elk krachtig stukje technologie kan worden gebruikt voor een enorme hoeveelheid goede, en ook nadelige gevolgen hebben, " merkt Prajwal op. "Ons werk is, in feite, een vertaalsysteem dat video-inhoud aankan. Inhoud vertaald door een algoritme is absoluut 'niet echt, ' maar deze vertaalde inhoud is essentieel voor mensen die een bepaalde taal niet begrijpen. Verder, in het huidige stadium, dergelijke automatisch vertaalde inhoud is gemakkelijk herkenbaar voor algoritmen en kijkers. Tegelijkertijd, er wordt actief onderzoek gedaan om dergelijke gewijzigde inhoud te herkennen. Wij zijn van mening dat de collectieve inspanning van verantwoord gebruik, strikte regels, en onderzoeksvooruitgang bij het opsporen van misbruik kan zorgen voor een positieve toekomst voor deze technologie."
Dat is nu filmischVolgens Taalinzicht, een studie door Britse onderzoekers heeft vastgesteld dat de voorkeur van bioscoopbezoekers voor nagesynchroniseerde versus ondertitelde buitenlandse films van invloed is op het type film waar ze naar worden aangetrokken. Degenen die van mainstream blockbusters houden, zien eerder een nagesynchroniseerde versie van een film, terwijl degenen die de voorkeur geven aan ondertitels, eerder fans zijn van arthouse-import.

Hoofdlijnen
- Zes hoofdcelfuncties
- Wat is een regeling in de microbiologie?
- Wat gebeurt er met je cellen als je uitgedroogd bent?
- Welke soorten genen hebben plasmiden?
- Alle informatie die nodig is om proteïnen te maken is gecodeerd in DNA door wat?
- Hoe gendoping werkt
- Wat veroorzaakt smeren bij elektroforese?
- Berekening van RNA-concentratie
- Hoe het Curiosity-project werkt






 Hoe de massa van een vaste stof te berekenen
Hoe de massa van een vaste stof te berekenen - De torsieconstante berekenen
- De voordelen van MOSFET boven BJT
- Fake Stained Glass maken
- Top 10 industriële revolutie-uitvindingen
- Hoe een 3D-perimeter te berekenen
- Hoe reproduceert een paardenbloem?
- Welke drie factoren beïnvloeden de druk van het gas in een gesloten container?
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
