Wetenschap
Lensloze beeldvorming door geavanceerde machine learning voor beelddetectieoplossingen van de volgende generatie
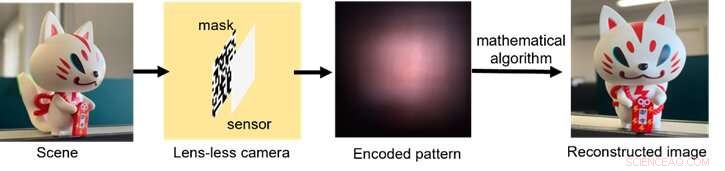
Een schematische weergave van hoe het lensloze beeldvormingsproces werkt, van lichtverzameling via codering van het signaal tot nabewerking met computeralgoritmen. Credit:Xiuxi Pan van Tokyo Tech
Een camera heeft meestal een lenssysteem nodig om een scherp beeld vast te leggen, en de lenscamera is al eeuwenlang de dominante beeldoplossing. Een camera met een lens vereist een complex lenssysteem om hoogwaardige, heldere en aberratievrije beeldvorming te verkrijgen. De afgelopen decennia is de vraag naar kleinere, lichtere en goedkopere camera's sterk toegenomen. Er is duidelijk behoefte aan camera's van de volgende generatie met hoge functionaliteit, compact genoeg om overal te kunnen worden geïnstalleerd. De miniaturisatie van de lenscamera wordt echter beperkt door het lenssysteem en de focusafstand die nodig is voor refractieve lenzen.
Recente ontwikkelingen in de computertechnologie kunnen het lenssysteem vereenvoudigen door de computer te vervangen door sommige delen van het optische systeem. De hele lens kan worden verlaten dankzij het gebruik van beeldreconstructiecomputing, waardoor een lensloze camera mogelijk is, die ultradun, lichtgewicht en goedkoop is. De lensloze camera wint de laatste tijd aan populariteit. Maar tot nu toe is de techniek voor beeldreconstructie nog niet vastgesteld, wat resulteert in een ontoereikende beeldkwaliteit en vervelende rekentijd voor de lensloze camera.
Onlangs hebben onderzoekers een nieuwe methode voor beeldreconstructie ontwikkeld die de rekentijd verbetert en afbeeldingen van hoge kwaliteit oplevert. Een kernlid van het onderzoeksteam, prof. Masahiro Yamaguchi van Tokyo Tech, beschrijft de oorspronkelijke motivatie achter het onderzoek:"Zonder de beperkingen van een lens zou de lensloze camera ultraminiatuur kunnen zijn, wat nieuwe toepassingen mogelijk maakt die buiten onze verbeelding." Hun werk is gepubliceerd in Optics Letters .
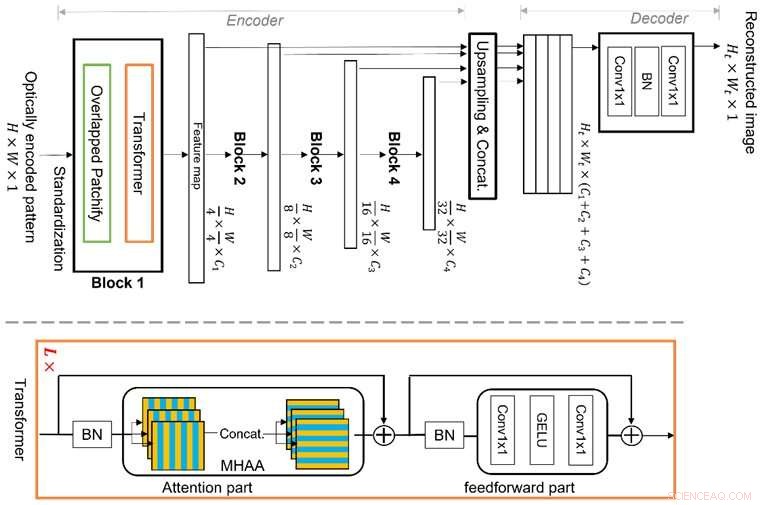
Vision Transformer (ViT) is een geavanceerde machine learning-techniek, die beter is in het redeneren van globale kenmerken vanwege de nieuwe structuur van de meertraps transformatorblokken met overlappende "patchify" -modules. Hierdoor kan het efficiënt beeldkenmerken leren in een hiërarchische weergave, waardoor het in staat is om de multiplexeigenschap aan te pakken en de beperkingen van conventioneel CNN-gebaseerd diep leren te vermijden, waardoor een betere beeldreconstructie mogelijk wordt. Krediet:Xiuxi Pan van Tokyo Tech
De typische optische hardware van de lensloze camera bestaat simpelweg uit een dun masker en een beeldsensor. Het beeld wordt vervolgens gereconstrueerd met behulp van een wiskundig algoritme. Het masker en de sensor kunnen samen worden gefabriceerd in gevestigde halfgeleiderproductieprocessen voor toekomstige productie. Het masker codeert optisch het invallende licht en werpt patronen op de sensor. Hoewel de gegoten patronen volledig niet-interpreteerbaar zijn voor het menselijk oog, kunnen ze worden gedecodeerd met expliciete kennis van het optische systeem.
Het decoderingsproces, gebaseerd op beeldreconstructietechnologie, blijft echter een uitdaging. Traditionele op modellen gebaseerde decoderingsmethoden benaderen het fysieke proces van de lensloze optica en reconstrueren het beeld door een "convex" optimalisatieprobleem op te lossen. Dit betekent dat het reconstructieresultaat gevoelig is voor de imperfecte benaderingen van het fysieke model. Bovendien is de berekening die nodig is voor het oplossen van het optimalisatieprobleem tijdrovend omdat het iteratieve berekening vereist. Deep learning zou kunnen helpen de beperkingen van modelgebaseerde decodering te vermijden, omdat het in plaats daarvan het model kan leren en de afbeelding kan decoderen door middel van een niet-iteratief direct proces. Bestaande methoden voor diep leren voor beeldvorming zonder lenzen, die gebruikmaken van een convolutioneel neuraal netwerk (CNN), kunnen echter geen afbeeldingen van hoge kwaliteit produceren. Ze zijn inefficiënt omdat CNN het beeld verwerkt op basis van de relaties van naburige "lokale" pixels, terwijl lensloze optica lokale informatie in de scène omzet in overlappende "algemene" informatie op alle pixels van de beeldsensor, via een eigenschap die "multiplexing" wordt genoemd. "

De lensloze camera bestaat uit een masker en een beeldsensor met een scheidingsafstand van 2,5 mm. Het masker is vervaardigd door chroomafzetting in een plaat van synthetisch silicium met een opening van 40 x 40 m. Krediet:Xiuxi Pan van Tokyo Tech
Het Tokyo Tech-onderzoeksteam bestudeert deze multiplexeigenschap en heeft nu een nieuw, speciaal machine learning-algoritme voor beeldreconstructie voorgesteld. Het voorgestelde algoritme is gebaseerd op een geavanceerde machine learning-techniek genaamd Vision Transformer (ViT), die beter is in het redeneren van globale kenmerken. De nieuwigheid van het algoritme ligt in de structuur van de meertraps transformatorblokken met overlappende "patchify" -modules. Hierdoor kan het efficiënt beeldkenmerken leren in een hiërarchische weergave. Bijgevolg kan de voorgestelde methode de multiplexeigenschap goed aanpakken en de beperkingen van conventioneel CNN-gebaseerd diep leren vermijden, waardoor een betere beeldreconstructie mogelijk is.
Terwijl conventionele modelgebaseerde methoden lange rekentijden vereisen voor iteratieve verwerking, is de voorgestelde methode sneller omdat de directe reconstructie mogelijk is met een iteratief vrij verwerkingsalgoritme dat is ontworpen door machine learning. De invloed van modelbenaderingsfouten wordt ook drastisch verminderd omdat het machine learning-systeem het fysieke model leert. Bovendien maakt de voorgestelde op ViT gebaseerde methode gebruik van globale kenmerken in de afbeelding en is deze geschikt voor het verwerken van gegoten patronen over een groot gebied op de beeldsensor, terwijl conventionele op machine learning gebaseerde decoderingsmethoden voornamelijk lokale relaties leren door CNN.
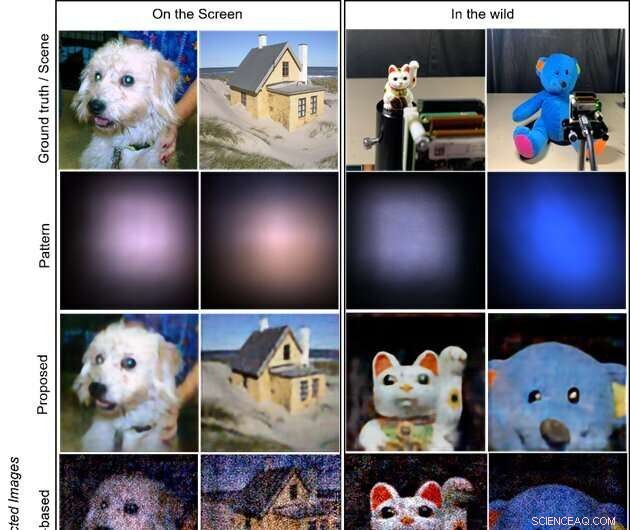
De doelen zijn respectievelijk de afbeeldingen die worden weergegeven op een LCD-scherm (twee kolommen links) en de objecten in het wild (twee kolommen rechts; wenkende kattenpop en knuffelbeer). De eerste rij toont de beelden van de grondwaarheid die op het scherm worden weergegeven en de opnamescènes voor in-the-wild-objecten. De tweede rij toont de vastgelegde patronen op de sensor. De laatste drie rijen illustreren de gereconstrueerde afbeeldingen met respectievelijk de voorgestelde, modelgebaseerde en CNN-gebaseerde methoden. De voorgestelde methode levert de meest hoogwaardige en visueel aantrekkelijke beelden op. Krediet:Xiuxi Pan van Tokyo Tech
Samenvattend lost de voorgestelde methode de beperkingen op van conventionele methoden, zoals iteratieve beeldreconstructie-gebaseerde verwerking en CNN-gebaseerd machine learning met de ViT-architectuur, waardoor de verwerving van afbeeldingen van hoge kwaliteit in een korte hoeveelheid rekentijd mogelijk is. Het onderzoeksteam voerde verder optische experimenten uit - zoals gerapporteerd in hun laatste publicatie in - die suggereren dat de lensloze camera met de voorgestelde reconstructiemethode hoogwaardige en visueel aantrekkelijke beelden kan produceren, terwijl de snelheid van de nabewerkingsberekening hoog genoeg is voor echte tijd vastleggen.
"We realiseren ons dat miniaturisatie niet het enige voordeel van de lensloze camera zou moeten zijn. De lensloze camera kan worden toegepast op onzichtbare lichtbeeldvorming, waarbij het gebruik van een lens onpraktisch of zelfs onmogelijk is. Bovendien is de onderliggende dimensionaliteit van vastgelegde optische informatie door de lensloze camera groter is dan twee, wat one-shot 3D-beeldvorming en herfocussering na opname mogelijk maakt. We onderzoeken meer functies van de lensloze camera. Het uiteindelijke doel van een lensloze camera is om miniatuur-maar-machtig te zijn. We zijn enthousiast om het voortouw te nemen in deze nieuwe richting voor beeld- en sensoroplossingen van de volgende generatie", zegt de hoofdauteur van de studie, dhr. Xiuxi Pan van Tokyo Tech, terwijl hij praat over hun toekomstige werk. + Verder verkennen
Uitbreiding van infrarood microspectroscopie met Lucy-Richardson-Rosen computationele reconstructiemethode
 NASA krijgt een infrarood babyfoto van de tropische storm Kristy
NASA krijgt een infrarood babyfoto van de tropische storm Kristy- Continentaal korstmodel belicht processen die drie tot vier miljard jaar geleden plaatsvonden
- Industriële koolstofemissies verminderen
- Wetenschappers missen essentiële kennis over snelle Arctische klimaatverandering
- Hoe stadslandbouw de voedselzekerheid in Amerikaanse steden kan verbeteren
Hoofdlijnen
- Verklaring van celspecialisatie
- Wetenschappers ontdekken nieuw soort synaps in kleine haartjes van neuronen
- Zeldzame zangvogel heeft misschien nooit bestaan
- Waarom zingen mensen onder de douche?
- Toenemend bewijs dat beren geen carnivoren zijn
- keratine, eiwitten van 54 miljoen jaar oude zeeschildpad vertonen evolutie van overlevingskenmerken
- Immuunfunctie geremodelleerd door mitochondriale vorm
- 3 fasen van interfase
- Hoe de Galapagos-eilanden werken




 Marseille sluit enkele stranden om te zwemmen vanwege zorgen over vervuiling
Marseille sluit enkele stranden om te zwemmen vanwege zorgen over vervuiling- Onwil om innovaties te delen betekent gemiste kansen voor life sciences-bedrijven, experts schrijven
- Hoe een letter Grade naar GPA te converteren
- Stealthy microscopie methode visualiseert E. coli subcellulaire structuur in 3-D
- Draagtijd voor vogels
- 5 Aardse feiten om de geest van uw kind te verbazen
- Magnetische afstemming op nanoschaal
- Hoe het in kaart brengen van de Galápagos duurzamere steden kan creëren
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
