Wetenschap
Voorspellen hoe goed neurale netwerken zullen schalen
Krediet:Massachusetts Institute of Technology
Voor alle vooruitgang die onderzoekers hebben geboekt met machine learning om ons te helpen dingen te doen zoals crunch-nummers, autorijden en kanker opsporen, we staan er zelden bij stil hoe energie-intensief het is om de enorme datacenters te onderhouden die dergelijk werk mogelijk maken. Inderdaad, een studie uit 2017 voorspelde dat, tegen 2025, op internet aangesloten apparaten zouden 20 procent van de elektriciteit in de wereld verbruiken.
De inefficiëntie van machine learning is deels een functie van hoe dergelijke systemen worden gecreëerd. Neurale netwerken worden meestal ontwikkeld door een initieel model te genereren, het aanpassen van een paar parameters, probeer het nog eens, en dan spoelen en herhalen. Maar deze benadering betekent dat aanzienlijke tijd, energie en computerbronnen worden besteed aan een project voordat iemand weet of het echt zal werken.
MIT-afgestudeerde student Jonathan Rosenfeld vergelijkt het met de 17e-eeuwse wetenschappers die de zwaartekracht en de beweging van planeten willen begrijpen. Hij zegt dat de manier waarop we tegenwoordig machine learning-systemen ontwikkelen - bij gebrek aan dergelijke inzichten - een beperkte voorspellende kracht heeft en dus erg inefficiënt is.
"Er is nog steeds geen uniforme manier om te voorspellen hoe goed een neuraal netwerk zal presteren, gegeven bepaalde factoren zoals de vorm van het model of de hoeveelheid gegevens waarop het is getraind, " zegt Rosenfeld, die onlangs een nieuw raamwerk over dit onderwerp heeft ontwikkeld met collega's van het Computer Science and Artificial Intelligence Lab (CSAIL) van MIT. "We wilden onderzoeken of we machine learning vooruit konden helpen door te proberen de verschillende relaties te begrijpen die de nauwkeurigheid van een netwerk beïnvloeden."
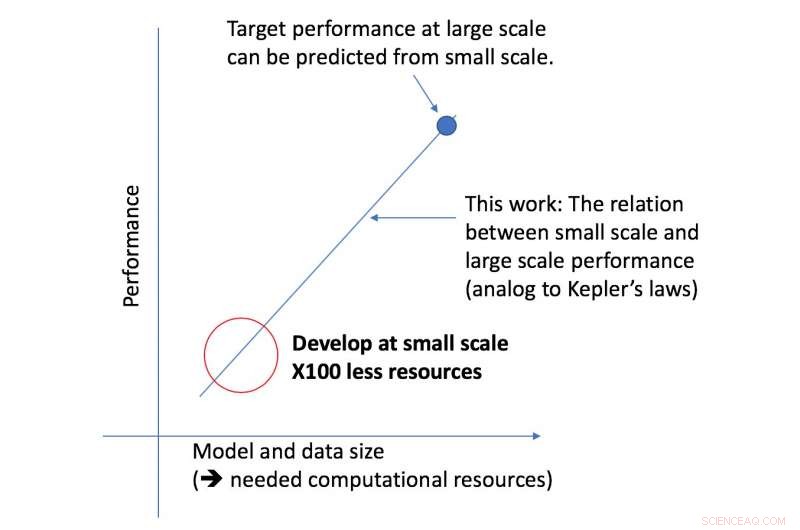
Het nieuwe raamwerk van het CSAIL-team kijkt naar een bepaald algoritme op een kleinere schaal, en, op basis van factoren zoals de vorm, kan voorspellen hoe goed het op grotere schaal zal presteren. Zo kan een datawetenschapper bepalen of het de moeite waard is om meer middelen te blijven besteden aan het verder trainen van het systeem.
"Onze aanpak vertelt ons dingen als de hoeveelheid gegevens die nodig is voor een architectuur om een specifieke doelprestatie te leveren, of de meest rekenkundig efficiënte afweging tussen gegevens en modelgrootte, " zegt MIT-professor Nir Shavit, die samen met Rosenfeld het nieuwe artikel schreef, voormalig promovendus Yonatan Belinkov en Amir Rosenfeld van York University. "We beschouwen deze bevindingen als verstrekkende implicaties in het veld door onderzoekers in de academische wereld en de industrie in staat te stellen de relaties tussen de verschillende factoren die moeten worden afgewogen bij het ontwikkelen van deep learning-modellen beter te begrijpen, en om dit te doen met de beperkte computationele middelen die beschikbaar zijn voor academici."
Het raamwerk stelde onderzoekers in staat om de prestaties op de grote model- en dataschalen nauwkeurig te voorspellen met vijftig keer minder rekenkracht.
Het aspect van deep learning-prestaties waar het team zich op richtte, is de zogenaamde "generalisatiefout, " wat verwijst naar de fout die wordt gegenereerd wanneer een algoritme wordt getest op gegevens uit de echte wereld. Het team gebruikte het concept van modelschaling, wat inhoudt dat de modelvorm op specifieke manieren moet worden gewijzigd om het effect op de fout te zien.
Als volgende stap, het team is van plan om de onderliggende theorieën te onderzoeken over wat de prestaties van een specifiek algoritme laat slagen of mislukken. Dit omvat het experimenteren met andere factoren die van invloed kunnen zijn op de training van deep learning-modellen.
 Een verbeterde op ruthenium gebaseerde katalysator voor de synthese van primaire amines
Een verbeterde op ruthenium gebaseerde katalysator voor de synthese van primaire amines- Wetenschappers ontwikkelen fagocytische protocellen die in staat zijn tot gerichte afgifte van enzymen
- Wat zijn de verschillen tussen oplosbaarheid en mengbaarheid?
- Neutralisatie van pathogene schimmels met immunotherapeutica met kleine moleculen
- trekken, niet duwen, zijde kan een revolutie teweegbrengen in de manier waarop groenere materialen worden vervaardigd
Hoofdlijnen
- Welk type organisch macromolecuul is glucose?
- Om nieuwe enzymen voor biobrandstoffen te vinden, het kan een microbieel dorp vergen
- Sommige mariene soorten zijn kwetsbaarder voor klimaatverandering dan andere
- Gestratificeerd epitheelweefsel: definitie, structuur, typen
- Hoe weet je lichaam het verschil tussen dominante en recessieve genen?
- Kunnen we een echt Jurassic Park creëren?
- Cytokinese: wat is het? & Wat gebeurt er in planten en dierencellen?
- Bijvangst verantwoordelijk voor achteruitgang Nieuw-Zeelandse zeeleeuw
- Twilight-truc:er is een nieuw type cel gevonden in het oog van een diepzeevis
- Twitter waarschuwt gebruikers wereldwijd dat hun tweets de Pakistaanse wet schenden

- Beekee box:Een netwerk zonder internet of elektriciteit

- Carnegie Mellon-team verbetert hackkracht met vijfde DefCon-titel in zeven jaar

- Madrid beveelt verwijdering van elektrische scooters

- Dyson kiest voormalig nachtlevencentrum in Singapore als hoofdkantoor


 Eigenschappen van subatomaire soep die het vroege heelal nabootst
Eigenschappen van subatomaire soep die het vroege heelal nabootst- Een nieuwe bindingsplaats voor antibiotica gevonden in het ribosoom
- NASA ziet versterkende tropische cycloon Sanvu een staart ontwikkelen
- Nieuw rapport toont dwingende redenen om sekswerk te decriminaliseren
- Amerikaanse oceaanobservatie cruciaal voor het begrijpen van klimaatverandering, maar mist nationale planning op lange termijn
- Fysische eigenschappen ophalen uit tweekleurenlaserexperimenten
- Hoe spinnen paren
- Gestresst:onderzoek werpt nieuw licht op waarom oplaadbare batterijen falen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
