Wetenschap
Een model om de grootte en vorm van online commentaarthreads te voorspellen
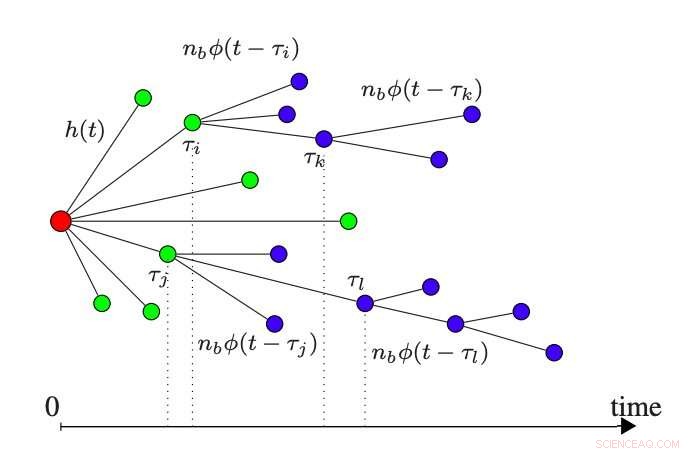
Voorbeeld van een Hawkes-vertakkingsproces. Het rode knooppunt (uiterst links) staat voor een bericht op sociale media. Groene en blauwe knooppunten vertegenwoordigen respectievelijk 'immigrant'- en 'nakomelingen'-gebeurtenissen. Krediet:Krohn &Weninger, aangepast met toestemming van het werk van Medvedev et al.
Op sociale mediaplatforms zoals Reddit en Twitter kunnen mensen hun mening uiten en deelnemen aan discussies over uiteenlopende onderwerpen. Dit wordt over het algemeen gedaan in commentaarthreads, waarmee gebruikers kunnen reageren op bestaande berichten.
Een commentaarthread is in wezen een gesprek tussen verschillende online gebruikers in de vorm van opmerkingen. In de informatica, commentaarthreads worden vaak beschouwd als "bomen, " met knooppunten die het oorspronkelijke bericht en de daaropvolgende opmerkingen vertegenwoordigen, en gerichte randen die "antwoord-op"-relaties vertegenwoordigen.
Twee onderzoekers van de Universiteit van Notre Dame hebben onlangs een model ontwikkeld om de grootte en vorm van online commentaarthreads te voorspellen wanneer ze als bomen worden bekeken. Ze noemden dit model, geïntroduceerd in een paper dat vooraf is gepubliceerd op arXiv, het Comment Thread Prediction Model (CTPM).
"Ons belangrijkste onderzoeksdoel is het voorspellen van de grootte en vorm van een thread met opmerkingen op sociale-mediasites, "Tim Weninger, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Op deze sites kunnen gebruikers nieuws of afbeeldingen of andere inhoud plaatsen. Dan houden andere gebruikers van, deel of reageer op het bericht. We zijn vooral geïnteresseerd in commentaarthreads, waar een gebruiker kan reageren op de post zelf of kan reageren op reacties zoals op Reddit en Twitter (maar niet op Facebook of YouTube)."
De studie uitgevoerd door Weninger en zijn collega Rachel Krohn werd gefinancierd door een programma van het Amerikaanse Defense Advanced Research Project Agency (DARPA), die zich specifiek richt op sociale simulatie. Een van de vragen die dit programma stelt, is of het mogelijk is om activiteiten op sociale media te simuleren.
Eerdere studies suggereren dat de eerste paar uur van het leven van een bericht van vitaal belang zijn bij het voorspellen van zijn toekomstige populariteit. In feite, berichten die veel vroege aandacht krijgen en direct door gebruikers worden becommentarieerd, zullen in de toekomst over het algemeen tot verdere online discussies leiden. Anderzijds, berichten die aanvankelijk weinig aandacht krijgen, zullen in de toekomst ook minder aandacht krijgen.
De meeste bestaande technieken die zijn ontworpen om de grootte en vorm van commentaarthreads te voorspellen, werken door de eerste paar opmerkingen die aan een bericht worden toegevoegd te observeren en vervolgens een voorspellend model te maken. Echter, aangezien de meeste commentaarthreads relatief klein zijn, wachten op het genereren van nieuwe gegevens kan het algemene doel van de voorspellingstaak schaden.
Het DARPA-programma dat de studie financierde, instrueerde de onderzoekers dus specifiek om te onderzoeken of ze de populariteit van een bericht konden voorspellen, inclusief het aantal reacties dat het in de toekomst zou oproepen, uitsluitend gebaseerd op de titel. Met dit doel voor ogen, het team ontwikkelde een model dat de woorden in de titel van een Reddit-bericht analyseert, samen met de gebruiker die het bericht plaatst en de subreddit waarnaar het is verzonden. Deze variabelen worden gebruikt om een "Hawkes-proces, " een statistisch model dat wordt gebruikt om wiskundige punten in de ruimte weer te geven.
"We gebruiken een Hawkes-proces om te simuleren hoe mensen de post zien, lees een reactie, en besluit vervolgens op elke opmerking te reageren, Weninger zei. "Het model is niet perfect en simuleert niet echt de inhoud van de opmerkingen (d.w.z. we raden niet wat de opmerking eigenlijk zegt, alleen of er een opmerking is of niet), echter, gemiddeld doen we het redelijk goed om te voorspellen welke reacties populair zullen zijn en welke niet, alleen op basis van de titel, auteur en subreddit van een bericht."
Weninger en zijn collega's evalueerden het CTPM-model op duizenden echte gebruikersdiscussies van Reddit, het vergelijken van de effectiviteit ervan bij het voorspellen van de grootte en vorm van commentaarthreads met die van andere technieken. Opmerkelijk, hun model presteerde aanzienlijk beter dan alle bestaande modellen en baselines waarmee het werd vergeleken.
"Voor mij is de meest betekenisvolle bijdrage van dit werk het vermogen van ons model om de omvang en vorm van online gesprekken te voorspellen, "Zei Weninger. "Dit is belangrijk voor de Amerikaanse wetshandhavings- en defensie-instanties, omdat het kunnen voorspellen van de toekomst in cyberspace deze instanties in staat stelt om effectieve verdedigingen voor te bereiden tegen cyberaanvallen en andere gebeurtenissen die vaak van de cyberwereld naar de fysieke wereld gaan. "
In de toekomst, het door Weninger en zijn collega's voorgestelde model zou kunnen worden gebruikt om de populariteit van berichten op Twitter of Reddit uitsluitend op basis van hun titel te voorspellen. Het team is nu van plan om verder te onderzoeken hoe mensen online informatie consumeren en beheren, inclusief hun interacties met de berichten van anderen (zoals vind-ik-leuks, aandelen, retweet, enzovoort.).
"De vind-ik-leuks, aandelen, stemmen, en retweets van gebruikers zijn het allerbelangrijkste voor sociale-mediabedrijven omdat ze aangeven welke inhoud moet worden gepromoot en welke inhoud spam of van lage kwaliteit kan zijn, " Zei Weninger. "We bestuderen deze processen en hoe ze kunnen worden gecorrumpeerd door individuen of groepen met slechte bedoelingen. Ons toekomstige werk op dit gebied zal kijken naar manipulaties van sociale inhoud (bijv. fotoshops, deepfake, enzovoort.), omdat we veel kunnen leren over mensen en hun cultuur door te kijken hoe ze afbeeldingen op sociale media veranderen."
© 2019 Wetenschap X Netwerk
 Waar de oceaan de lucht ontmoet - nieuwe NASA-radar krijgt een try-out
Waar de oceaan de lucht ontmoet - nieuwe NASA-radar krijgt een try-out- Prehistorische haaientanden vinden in Texas
- Beheersen dieren het zuurstofgehalte van de aarde?
- Het smelten van de Groenlandse ijskap verminderen met behulp van zonne-geo-engineering?
- Het dumpen van giftig afval in de Golf van Guinee komt neer op milieuracisme
Hoofdlijnen
- Drie van de meest bizarre relaties van de natuur
- Probiotica (vriendelijke bacteriën): wat is het en hoe helpt het ons?
- Maak een lijst van de soorten informatie die gevonden kan worden door de sequentie van een DNA-molecuul te kennen Molecule
- Nieuwe mutaties in iPS-cellen zijn voornamelijk geconcentreerd in niet-transcriptionele regio's
- Is de behoefte aan privacy evolutionair?
- Waarom herinneren we ons pijn?
- Komen uitgestorven virussen terug dankzij klimaatverandering?
- Verschil tussen koppelingstoewijzing en chromosoommapping
- Hoe evolueert het leven?
- EU's strenge nieuwe regels voor gegevensbescherming

- Buddy Adventures en Niantic Wayfarer komen naar Pokémon Go

- Maker van Chinas TikTok ontkent bericht dat het een HK-vermelding plant

- Nieuwe benadering maakt 3D-printen van fijnere, complexere microfluïdische netwerken
- Beyond Queens stomp-stomp-clap:concerten en informatica komen samen in nieuw onderzoek


 Zelfs druppeltjes gaan soms de trap op
Zelfs druppeltjes gaan soms de trap op- De chemische samenstelling van groene planten
In veel opzichten verschillen planten niet erg van mensen. Als je een plant en een persoon in hun basiselementen zou afbreken, zou je merken dat beide meer koolstof, waterstof en zuurstof bevatten dan w
- Thais strand uit DiCaprio-film krijgt adempauze van toeristen
- Nieuw, veilige zinkoxide kwantumstippen
- Hoe wordt witte chocolade gemaakt?
- Luchtkwaliteit zakt te ernstig in het met nevel gehulde New Delhi
- Hoe klimaatverandering de economie beïnvloedt
- Elektriciteitsmeter aansluiten op een stacaravan
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Norway | Swedish |

-
Wetenschap © https://nl.scienceaq.com
