Wetenschap
Vrouwen zijn mooi, mannen rationeel
Krediet:Universiteit van Kopenhagen
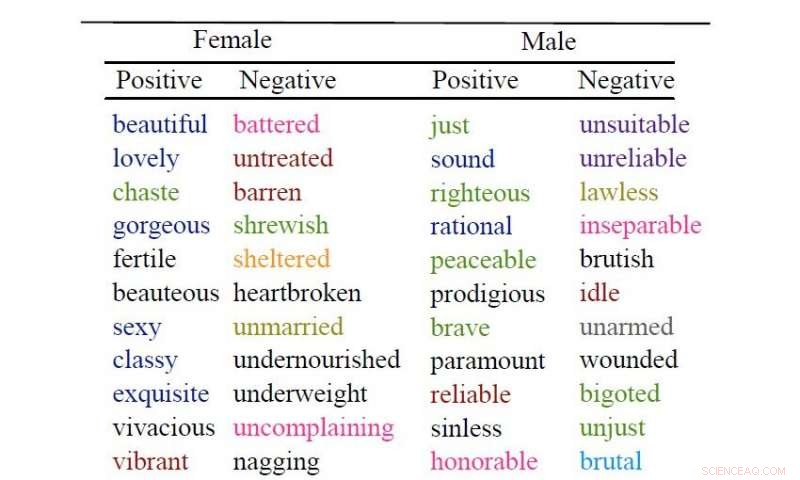
Mannen worden meestal beschreven met woorden die verwijzen naar gedrag, terwijl bijvoeglijke naamwoorden die aan vrouwen worden toegeschreven, meestal worden geassocieerd met fysieke verschijning. Dit, volgens een groep computerwetenschappers van de Universiteit van Kopenhagen en andere universiteiten die machine learning hebben ingezet om 3,5 miljoen boeken te analyseren.
'Mooi' en 'sexy' zijn twee van de bijvoeglijke naamwoorden die het meest worden gebruikt om vrouwen te beschrijven. Veelgebruikte omschrijvingen voor mannen zijn 'rechtvaardig, 'rationeel' en 'dapper'.
Een computerwetenschapper van de Universiteit van Kopenhagen, samen met collega-onderzoekers uit de Verenigde Staten, een enorme hoeveelheid boeken doorzocht om erachter te komen of er een verschil is tussen de soorten woorden die in de literatuur worden gebruikt om mannen en vrouwen te beschrijven. Met een nieuw computermodel analyseerden de onderzoekers een dataset van 3,5 miljoen boeken, allemaal gepubliceerd in het Engels tussen 1900 en 2008. De boeken bevatten een mix van fictie en non-fictie literatuur.
"We zijn duidelijk in staat om te zien dat de woorden die voor vrouwen worden gebruikt veel meer verwijzen naar hun uiterlijk dan de woorden die worden gebruikt om mannen te beschrijven. hebben we een wijdverbreide perceptie kunnen bevestigen, alleen nu op statistisch niveau, ", zegt computerwetenschapper en assistent-professor Isabelle Augenstein van de afdeling Computerwetenschappen van de Universiteit van Kopenhagen.
De onderzoekers extraheren bijvoeglijke naamwoorden en werkwoorden die verband houden met geslachtsspecifieke zelfstandige naamwoorden (bijvoorbeeld 'dochter' en 'stewardess'). Bijvoorbeeld, in combinaties als 'sexy stewardess' of 'girls roddelend'. Vervolgens analyseerden ze of de woorden een positieve, negatief of neutraal sentiment, en vervolgens in welke categorieën de woorden zouden kunnen worden onderverdeeld.
Hun analyses tonen aan dat negatieve werkwoorden die verband houden met lichaam en uiterlijk vijf keer zo vaak worden gebruikt voor vrouwen als voor mannen. De analyses tonen ook aan dat positieve en neutrale adjectieven met betrekking tot het lichaam en het uiterlijk ongeveer twee keer zo vaak voorkomen in beschrijvingen van vrouwen, terwijl mannen het vaakst worden beschreven met bijvoeglijke naamwoorden die verwijzen naar hun gedrag en persoonlijke kwaliteiten.
Vroeger, taalkundigen keken meestal naar de prevalentie van gendergerelateerde taal en vooroordelen, maar met kleinere datasets. Nutsvoorzieningen, computerwetenschappers kunnen algoritmen voor machine learning inzetten om enorme hoeveelheden gegevens te analyseren - in dit geval 11 miljard woorden.
Nieuw leven voor oude genderstereotypen
Hoewel veel van de boeken enkele decennia geleden zijn gepubliceerd, ze spelen nog steeds een actieve rol, wijst Isabelle Augenstein aan. De algoritmen die worden gebruikt om machines en applicaties te maken die menselijke taal kunnen begrijpen, worden gevoed met gegevens in de vorm van tekstmateriaal dat online beschikbaar is. Dit is de technologie waarmee smartphones onze stemmen kunnen herkennen en Google in staat stelt zoekwoordsuggesties te geven.
"De algoritmen werken om patronen te identificeren, en wanneer men wordt geobserveerd, wordt waargenomen dat iets 'waar' is." Als een van deze patronen verwijst naar vooringenomen taal, het resultaat zal ook bevooroordeeld zijn. De systemen nemen, bij wijze van spreken, de taal die wij mensen gebruiken, en daarom, onze genderstereotypen en vooroordelen, " zegt Isabelle Augenstein, en geeft een voorbeeld van waar het van belang kan zijn:
"Als de taal die we gebruiken om mannen en vrouwen te beschrijven verschilt, in werknemersaanbevelingen bijvoorbeeld, het zal van invloed zijn op wie een baan krijgt aangeboden wanneer bedrijven IT-systemen gebruiken om sollicitaties te sorteren."
Naarmate kunstmatige intelligentie en taaltechnologie steeds prominenter worden in de samenleving, het is belangrijk om je bewust te zijn van gendertaal.
Augenstein vervolgt:"We kunnen proberen hiermee rekening te houden bij het ontwikkelen van modellen voor machine learning door ofwel minder vooringenomen tekst te gebruiken of door modellen te dwingen om vooringenomenheid te negeren of tegen te gaan. Alle drie dingen zijn mogelijk."
De onderzoekers wijzen erop dat de analyse zijn beperkingen heeft, in die zin dat het geen rekening houdt met wie de individuele passages heeft geschreven en de verschillen in de mate van vooringenomenheid afhankelijk van of de boeken in een eerdere of latere periode binnen de tijdlijn van de dataset zijn gepubliceerd. Verder, het maakt geen onderscheid tussen genres, b.v. tussen romans en non-fictie. De onderzoekers volgen momenteel een aantal van deze punten op.
 Buiten de kaders denken over klimaatmitigatie
Buiten de kaders denken over klimaatmitigatie- Seismische gegevens verklaren continentale botsing onder Tibet
- Vulkanisch gordijn van vuur jaagt mensen op de vlucht voor huizen in Hawaï
- Onderzoekers onderzoeken hoe verschuivingen in federale benaderingen het tij van destructieve bosbranden kunnen keren
- Ondanks de heldere lucht tijdens de pandemie, de uitstoot van broeikasgassen stijgt nog steeds
Hoofdlijnen
- Genetici ontdekken twee verschillende manieren om transcriptie te beëindigen
- Doorbraak in genetisch onderzoek om gerstproductie te stimuleren
- De definitie van lichaamssystemen
- Gliale cellen (Glia): definitie, functie, typen
- Nieuwe tools helpen bij het zoeken naar levensverlengende chemicaliën
- Nieuwe studie verifieert meer manieren om te overleven voor bedreigde Chinook-zalm in de winter
- Afwijkende hyfen veroorzaakt door immuunreacties van de gastheer op plantpathogene schimmel
- Koud verbijsterde zeekoeien, zeeschildpadden opwarmen bij SeaWorld
- Continentale controles nodig om de strijd tegen boomziekten te handhaven
- Trump mikt opnieuw op Amazon in nieuwe tweets

- Amazon plant nieuwe supermarkt in L.A. terwijl het nadenkt over hoe de industrie te veroveren

- Nieuwe studie toont aan dat draagbare technologie ook bijdraagt aan afgeleid autorijden

- Frankrijk legt Google een boete op van $ 166 miljoen voor misbruik van advertentiedominantie

- Fossielen achterlaten voor de toekomst van transport


 Cycloon treft kust Oost-India
Cycloon treft kust Oost-India- 10 innovaties in wijnmaken
- Materialen uit het ruimtetijdperk, één atoomlaag tegelijk
- Writers Guild of America West tekent deal met Apple
- Kubieke meters converteren naar Ton
- Ontploffing, impactsimulaties kunnen leiden tot een beter begrip van verwondingen en kogelvrije vesten
- Röntgenstralen en zwaartekrachtsgolven zorgen samen voor het verlichten van enorme botsingen met zwarte gaten
- Assemblagetheorie zou goed nieuws kunnen zijn voor de ontdekking van medicijnen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
