Wetenschap
Een techniek om machinaal leren te verbeteren, geïnspireerd op het gedrag van menselijke baby's
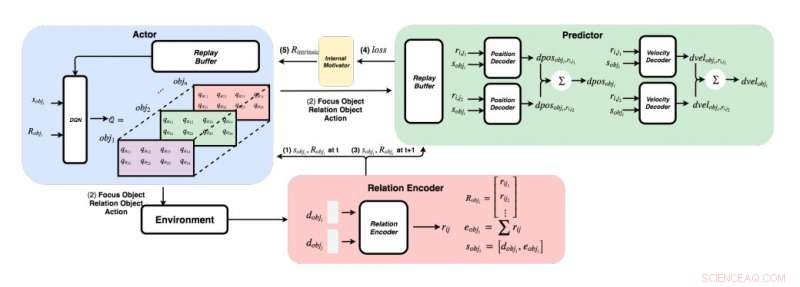
Een gedetailleerd schema van de door de onderzoekers ontwikkelde aanpak. (Rechtsonder) Voor elk paar objecten, de onderzoekers voeren hun functies in een relatie-encoder om de relatie rij en object i's staat sobji te krijgen. (Linksboven) Met behulp van de hebzuchtige methode, voor elk voorwerp, ze vinden de maximale Q-waarde om ons focusobject te krijgen, relatie object, en actie. (Rechtsboven) Nadat ze hun focusobject en relatieobject hadden verzameld, ze voeden hun toestanden en al hun relaties met hun decoders om de verandering in positie en verandering in snelheid te voorspellen. Krediet:Choi &Yoon.
Vanaf hun eerste levensjaren mensen hebben het aangeboren vermogen om continu te leren en mentale modellen van de wereld te bouwen, simpelweg door dingen of mensen in hun omgeving te observeren en ermee om te gaan. Cognitieve psychologiestudies suggereren dat mensen uitgebreid gebruik maken van deze eerder verworven kennis, vooral als ze in nieuwe situaties komen of beslissingen nemen.
Ondanks de belangrijke recente ontwikkelingen op het gebied van kunstmatige intelligentie (AI), de meeste virtuele agenten hebben nog steeds honderden uren training nodig om prestaties op menselijk niveau te bereiken in verschillende taken, terwijl mensen kunnen leren hoe ze deze taken in een paar uur of minder kunnen voltooien. Recente studies hebben twee belangrijke bijdragen aan het vermogen van mensen om zo snel kennis te verwerven naar voren gebracht, namelijk:intuïtieve fysica en intuïtieve psychologie.
Deze intuïtiemodellen, die zijn waargenomen bij mensen vanaf de vroege stadia van ontwikkeling, mogelijk de belangrijkste begeleiders van toekomstig leren zijn. Op basis van dit idee, onderzoekers van het Korea Advanced Institute of Science and Technology (KAIST) hebben onlangs een intrinsieke beloningsnormalisatiemethode ontwikkeld waarmee AI-agenten acties kunnen selecteren die hun intuïtiemodellen het meest verbeteren. In hun krant voorgepubliceerd op arXiv, de onderzoekers stelden specifiek een grafisch fysica-netwerk voor dat geïntegreerd is met diep versterkend leren, geïnspireerd door het leergedrag dat wordt waargenomen bij menselijke baby's.
"Stel je menselijke baby's voor in een kamer met speelgoed dat op een bereikbare afstand rondslingert, ' leggen de onderzoekers uit in hun paper. 'Ze zijn constant aan het grijpen, gooien en acties uitvoeren op objecten; soms, ze observeren de nasleep van hun acties, maar soms, ze verliezen hun interesse en gaan naar een ander object. De 'kind als wetenschapper'-opvatting suggereert dat menselijke baby's intrinsiek gemotiveerd zijn om hun eigen experimenten uit te voeren, ontdek meer informatie, en uiteindelijk leren om verschillende objecten te onderscheiden en rijkere interne representaties ervan te creëren."
Psychologische studies suggereren dat in hun eerste levensjaren, mensen experimenteren continu met hun omgeving, en dit stelt hen in staat om een belangrijk begrip van de wereld te vormen. Bovendien, wanneer kinderen resultaten waarnemen die niet voldoen aan hun eerdere verwachtingen, wat bekend staat als verwachtingsschending, ze worden vaak aangemoedigd om verder te experimenteren om een beter begrip te krijgen van de situatie waarin ze zich bevinden.
Het team van onderzoekers van KAIST probeerde dit gedrag in AI-agenten te reproduceren met behulp van een versterkingsleerbenadering. In hun studie hebben ze introduceerden eerst een grafisch fysica-netwerk dat fysieke relaties tussen objecten kan extraheren en hun daaropvolgende gedrag in een 3D-omgeving kan voorspellen. Vervolgens, ze integreerden dit netwerk met een diepgaand leermodel, introductie van een intrinsieke beloningsnormalisatietechniek die een AI-agent aanmoedigt om acties te onderzoeken en te identificeren die zijn intuïtiemodel voortdurend zullen verbeteren.
Met behulp van een 3D-fysica-engine, de onderzoekers toonden aan dat hun grafische fysica-netwerk efficiënt de posities en snelheden van verschillende objecten kan afleiden. Ze ontdekten ook dat hun aanpak het diepe versterkende leernetwerk in staat stelde om zijn intuïtiemodel voortdurend te verbeteren, het aanmoedigen om uitsluitend op basis van intrinsieke motivatie met objecten om te gaan.
In een reeks evaluaties de nieuwe techniek die door dit team van onderzoekers is bedacht, heeft een opmerkelijke nauwkeurigheid bereikt, waarbij de AI-agent een groter aantal verschillende verkennende acties uitvoert. In de toekomst, het zou de ontwikkeling van machine learning-tools kunnen stimuleren die sneller en effectiever kunnen leren van hun ervaringen uit het verleden.
"We hebben ons netwerk getest op zowel stationaire als niet-stationaire problemen in verschillende scènes met bolvormige objecten met verschillende massa's en stralen, " leggen de onderzoekers uit in hun paper. "Onze hoop is dat deze vooraf getrainde intuïtiemodellen later zullen worden gebruikt als voorkennis voor andere doelgerichte taken zoals ATARI-spellen of videovoorspelling."
© 2019 Wetenschap X Netwerk
 Ideeën voor het laten vallen van eieren om geen ei te breken vanaf de hoogte van een schoolgebouw
Ideeën voor het laten vallen van eieren om geen ei te breken vanaf de hoogte van een schoolgebouw- Op afstand bestuurde medicijnafgifte implantaatgrootte van druif kan helpen bij het beheer van chronische ziekten
- Alternatieve cementrecepten - Een recept voor eco-beton
- Hoe bevriest water?
- Wetenschappers stellen nieuwe bifunctionele katalysatoren voor op van biomassa afgeleide koolstof
- Het smelten van de permafrost in het noordpoolgebied zal het broeikaseffect verergeren
- Vrijkomen van water schudt Pacific Plate op diepte
- Stedelijke hitte-eilanden hebben invloed op de temperatuur en gezondheid van het bladerdak, studie zegt:
- Geowetenschappers creëren een diepere kijk op processen onder het aardoppervlak met 3D-beelden
- Nieuwe 3D-weergave van bronnen van methaansporen
Hoofdlijnen
- Een plantenceldiagram maken
- Bron van Beperking Enzymes
- Gebruik van microscopen in de wetenschap
- Antibiotica ontdekking in de afgrond
- Het verschil tussen glycolyse en gluconeogenese
- Belangrijke verbeteringen onthuld op Closer to Van Eyck webapplicatie
- P53 (TP53) Tumor Protein: Function, Mutation
- Natuurbeschermers moeten het Hollywood-effect benutten om dieren in het wild te helpen
- Satellietvolging geeft aanwijzingen over verloren jaren aan Zuid-Atlantische zeeschildpadden
- Boerderijen creëren veel data, maar boeren hebben geen controle over waar het terechtkomt en wie het kan gebruiken

- Duitsland hoopt in 2019 de batterijproductie in de EU op gang te brengen

- Amazon en Google gaan naar CES met digitale assistenten op sleeptouw

- Codebreker Alan Turing wordt gezicht van nieuw Brits bankbiljet

- Biologisch geïnspireerde huid verbetert de zintuiglijke vermogens van robots


 leiders, opvolgers, en zwoegers:Wiskundigen classificeren natuurkundigen en andere wetenschappers
leiders, opvolgers, en zwoegers:Wiskundigen classificeren natuurkundigen en andere wetenschappers- Bergbewoners kunnen zich aanpassen aan smeltende gletsjers zonder zich zorgen te maken over klimaatverandering
- Hoe de helling in een cirkel te vinden
- Verloren afmetingen van afbeeldingen en video herstellen
- Onderzoek onthult digitale impact op journalisten
- Chemici ontwikkelen edelmetaal-aerogels voor elektrochemische waterstofproductie
- Invasieve tropische plant kan metaalverontreinigende stoffen volledig uit de Britse rivieren verwijderen - nieuwe studie
- Slanke telescoop haalt het in de Big Apple
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Spanish | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
