Wetenschap
Netwerksoftware optimaliseren om wetenschappelijke ontdekkingen te bevorderen

Brookhaven Lab werkte samen met Columbia University, Universiteit van Edinburgh, en Intel om de prestaties te optimaliseren van een 144-node parallelle computer die is gebouwd met Intel's Xeon Phi-processors en een Omni-Path high-speed communicatienetwerk. De computer is geïnstalleerd in Brookhaven's Scientific Data and Computing Center, zoals hierboven te zien met technologie-ingenieur Costin Caramarcu. Krediet:Brookhaven National Laboratory
High-performance computing (HPC) - het gebruik van supercomputers en parallelle verwerkingstechnieken om grote rekenproblemen op te lossen - is van groot nut in de wetenschappelijke gemeenschap. Bijvoorbeeld, wetenschappers van het Brookhaven National Laboratory van het Amerikaanse Department of Energy (DOE) vertrouwen op HPC om de gegevens te analyseren die ze verzamelen in de grootschalige experimentele faciliteiten ter plaatse en om complexe processen te modelleren die te duur of onmogelijk experimenteel aan te tonen zouden zijn.
Moderne wetenschappelijke toepassingen, zoals het simuleren van deeltjesinteracties, vereisen vaak een combinatie van geaggregeerde rekenkracht, hogesnelheidsnetwerken voor gegevensoverdracht, grote hoeveelheden geheugen, en opslagmogelijkheden met hoge capaciteit. Vooruitgang in HPC-hardware en -software is nodig om aan deze vereisten te voldoen. Computer- en computationele wetenschappers en wiskundigen in het Computational Science Initiative (CSI) van Brookhaven Lab werken samen met natuurkundigen, biologen, en andere domeinwetenschappers om hun behoeften op het gebied van gegevensanalyse te begrijpen en oplossingen te bieden om het wetenschappelijke ontdekkingsproces te versnellen.
Een leider in de HPC-industrie
Al decenia, Intel Corporation is een van de leiders in het ontwikkelen van HPC-technologieën. in 2016, het bedrijf bracht de Intel Xeon PhiTM-processors uit (voorheen met de codenaam "Knights Landing"), de HPC-architectuur van de tweede generatie die veel verwerkingseenheden (cores) per chip integreert. Hetzelfde jaar, Intel heeft het Intel Omni-Path Architecture high-speed communicatienetwerk uitgebracht. Om de 5 000 tot 100, 000 individuele computers, of knooppunten, in moderne supercomputers om samen te werken om een probleem op te lossen, ze moeten snel met elkaar kunnen communiceren en netwerkvertragingen tot een minimum kunnen beperken.
Kort na deze releases, Brookhaven Lab en RIKEN, Japans grootste alomvattende onderzoeksinstelling, hebben hun middelen gebundeld om een kleine 144-node parallelle computer aan te schaffen die is opgebouwd uit Xeon Phi-processors en twee onafhankelijke netwerkverbindingen, of rails, met behulp van Intel's Omni-Path-architectuur. De computer is geïnstalleerd in Brookhaven Lab's Scientific Data and Computing Center, dat deel uitmaakt van CSI.
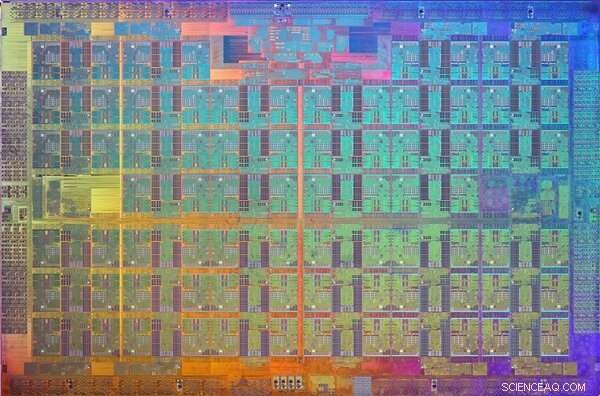
Een afbeelding van de Xeon Phi Knights Landing-processormatrijs. Een dobbelsteen is een patroon op een wafel van halfgeleidend materiaal dat de elektronische schakelingen bevat om een bepaalde functie uit te voeren. Krediet:Intel
Met de installatie voltooid, natuurkundige Chulwoo Jung en CSI computerwetenschapper Meifeng Lin van Brookhaven Lab; theoretisch fysicus Christoph Lehner, een gezamenlijke aangestelde bij Brookhaven Lab en de Universiteit van Regensburg in Duitsland; Norman Christus, de Ephraim Gildor hoogleraar computationele theoretische fysica aan de Columbia University; en theoretisch deeltjesfysicus Peter Boyle van de Universiteit van Edinburgh werkte nauw samen met software-ingenieurs bij Intel om de netwerksoftware te optimaliseren voor twee wetenschappelijke toepassingen:deeltjesfysica en machine learning.
"CSI was sinds de aankondiging in 2015 erg geïnteresseerd in de Intel Omni-Path Architecture. " zei Lin. "De expertise van Intel-ingenieurs was van cruciaal belang voor het implementeren van de software-optimalisaties waardoor we volledig konden profiteren van dit krachtige communicatienetwerk voor onze specifieke toepassingsbehoeften."
Netwerkvereisten voor wetenschappelijke toepassingen
Voor veel wetenschappelijke toepassingen het uitvoeren van één rang (een waarde die het ene proces van het andere onderscheidt) of mogelijk een paar rangschikkingen per knooppunt op een parallelle computer is veel efficiënter dan het uitvoeren van meerdere rangschikkingen per knooppunt. Elke rang wordt doorgaans uitgevoerd als een onafhankelijk proces dat communiceert met de andere rangen door gebruik te maken van een standaardprotocol dat bekend staat als Message Passing Interface (MPI).
Bijvoorbeeld, natuurkundigen die proberen te begrijpen hoe het vroege heelal is gevormd, voeren complexe numerieke simulaties uit van deeltjesinteracties op basis van de theorie van kwantumchromodynamica (QCD). Deze theorie legt uit hoe elementaire deeltjes, quarks en gluonen genaamd, op elkaar inwerken om de deeltjes te vormen die we direct waarnemen, zoals protonen en neutronen. Natuurkundigen modelleren deze interacties met behulp van supercomputers die de drie dimensies van ruimte en de dimensie van tijd vertegenwoordigen in een vierdimensionaal (4D) rooster van punten op gelijke afstanden, vergelijkbaar met die van een kristal. Het rooster is opgesplitst in kleinere identieke deelvolumes. Voor rooster QCD-berekeningen, gegevens moeten worden uitgewisseld op de grenzen tussen de verschillende subvolumes. Als er meerdere rangen per knoop zijn, elke rang herbergt een ander 4D-subvolume. Dus, het opsplitsen van de subvolumes creëert meer grenzen waar gegevens moeten worden uitgewisseld en dus onnodige gegevensoverdrachten die de berekeningen vertragen.
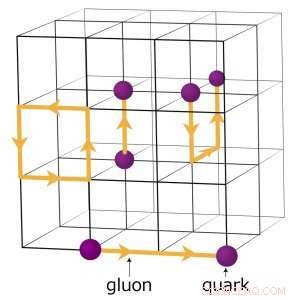
Een schema van het rooster voor kwantumchromodynamische berekeningen. De snijpunten op het rooster vertegenwoordigen quarkwaarden, terwijl de lijnen ertussen gluonwaarden vertegenwoordigen. Krediet:Brookhaven National Laboratory
Software-optimalisaties om de wetenschap vooruit te helpen
Om de netwerksoftware voor zo'n rekenintensieve wetenschappelijke toepassing te optimaliseren, het team gericht op het verbeteren van de snelheid van een enkele rang.
"We hebben de code voor een enkele MPI-rang sneller laten lopen, zodat een wildgroei aan MPI-rangen niet nodig zou zijn om de grote communicatiebelasting voor elk knooppunt aan te kunnen, " verklaarde Christus.
De software binnen de MPI-rang maakt gebruik van het parallellisme met schroefdraad dat beschikbaar is op Xeon Phi-knooppunten. Threaded parallellisme verwijst naar de gelijktijdige uitvoering van meerdere processen, of draden, die dezelfde instructies volgen terwijl ze enkele computerbronnen delen. Met de geoptimaliseerde software, het team was in staat om meerdere communicatiekanalen op één rangorde te creëren en deze kanalen aan te sturen met behulp van verschillende threads.
De MPI-software was nu ingesteld om de wetenschappelijke toepassingen sneller te laten werken en optimaal te profiteren van de Intel Omni-Path-communicatiehardware. Maar na het implementeren van de software, de teamleden kwamen een andere uitdaging tegen:in elke run, een paar knooppunten zouden onvermijdelijk langzaam communiceren en de anderen tegenhouden.
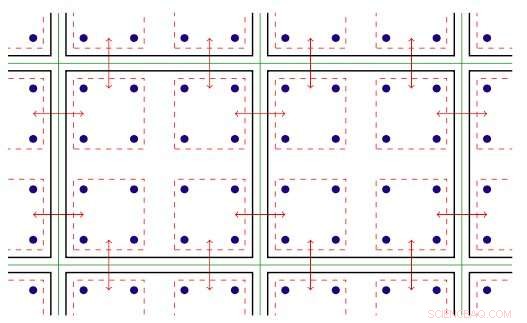
Tweedimensionale afbeelding van parallellisme met schroefdraad. Sleutel:groene lijnen scheiden fysieke rekenknooppunten; zwarte lijnen scheiden MPI-rangen; rode lijnen zijn de communicatiecontexten, waarbij de pijlen communicatie tussen knooppunten of geheugenkopie binnen een knooppunt via de Intel Omni-Path-hardware aangeven. Krediet:Brookhaven National Laboratory
Ze herleidden dit probleem tot de manier waarop Linux - het besturingssysteem dat door de meeste HPC-platforms wordt gebruikt - het geheugen beheert. In de standaardmodus, Linux verdeelt het geheugen in kleine stukjes die pagina's worden genoemd. Door Linux opnieuw te configureren om grote ("enorme") geheugenpagina's te gebruiken, ze hebben het probleem opgelost. Door de paginagrootte te vergroten, zijn er minder pagina's nodig om de virtuele adresruimte die een toepassing gebruikt in kaart te brengen. Als resultaat, geheugen is veel sneller toegankelijk.
Met de softwareverbeteringen, de teamleden analyseerden de prestaties van de Intel Omni-Path Architecture en Intel Xeon Phi processor compute nodes die geïnstalleerd zijn op Intel's dual-rail "Diamond" cluster en het Distributed Research Using Advanced Computing (DiRAC) single-rail cluster in het Verenigd Koninkrijk. Voor hun analyse ze gebruikten twee verschillende klassen van wetenschappelijke toepassingen:deeltjesfysica en machine learning. Voor beide toepassingscodes, ze bereikten bijna-draadloze prestaties - de theoretische maximale snelheid van gegevensoverdracht. Deze verbetering vertegenwoordigt een toename van de netwerkprestaties die vier tot tien keer zo hoog is als die van de oorspronkelijke codes.
"Door de nauwe samenwerking tussen Brookhaven, Edinburgh, en Intel, deze optimalisaties zijn wereldwijd beschikbaar gemaakt in een nieuwe versie van de Intel Omni-Path MPI-implementatie en een best-practice-protocol om Linux-geheugenbeheer te configureren, "zei Christ. "De factor vijf versnelling in de uitvoering van de natuurkundige code op de Xeon Phi-computer in Brookhaven Lab - en op de nieuwe, nog grotere Hewlett Packard Enterprise "hypercube" computer met 800 knooppunten - wordt nu goed gebruikt in lopende onderzoeken naar fundamentele vragen in de deeltjesfysica."
 Nabij-infraroodsonde decodeert de dynamiek van telomeren
Nabij-infraroodsonde decodeert de dynamiek van telomeren- Bio-geïnspireerde materialen - lenen uit het speelboek van de natuur
- Hoe zuren zich gedragen in de ultrakoude interstellaire ruimte
- Wetenschappers ontwikkelen katalysator om ethanol om te zetten in hoogwaardige chemicaliën en brandstoffen
- Wetenschappers ontwikkelen biorubberlijm voor sneller chirurgisch herstel en pijnverlichting
- Onderzoek naar de onderzeese dode zone die bekend staat als de hot tub van wanhoop
- Hoe de Azteken de moderne stadslandbouw konden verbeteren
- Nieuwe uitbraak van koraalverbleking in Northern Territory een zorgwekkend teken van onze opwarmende oceanen
- Verschillende bronnen van water
- Regen speelt een verrassende rol bij het gezonder maken van sommige herstelde prairies dan andere
Hoofdlijnen
- Marmoset-baby's krijgen een boost van attente vaders
- Gestrande walvisachtigen? Daar is een app voor
- Verschil tussen triglyceriden en fosfolipiden
- Hoe goed kennen mensen zichzelf eigenlijk?
- Een derde van alle haaiensoorten in de vinnenhandel wordt bedreigd
- Hoe deelbaar door uit te drukken in Excel
- Grote katten in Groot-Brittannië - stedelijke mythe of wetenschappelijk feit?
- Wat is Meiotic Interphase?
- Science Fair Ideas With the Topic Dance
- Senegal lanceert Afrikaanse school voor cyberbeveiliging

- 3D-geprinte robothand speelt piano

- Ambient Mode aangekondigd voor sommige Android-telefoons
- Mark Zuckerberg:Facebook heeft de campagnes van Rusland en Iran stopgezet om zich te bemoeien met de verkiezingen van 2020

- Een draagbare trillingssensor voor nauwkeurige spraakherkenning

 Astronomen ontdekken een superaardse exoplaneet in een baan om een ster met een lage massa
Astronomen ontdekken een superaardse exoplaneet in een baan om een ster met een lage massa- Een einde aan gaatjes voor mensen met gevoelige tanden?
- Directe meting van het protonenspectrum van kosmische straling met de CALET op het ISS
- Nieuwe bio-imaging-techniek is snel en voordelig
- Nieuwe moleculaire printtechnologie kan complexe chemische omgevingen nabootsen die op het menselijk lichaam lijken
- Machines die taal leren zoals kinderen dat doen
- Honda, GM gaat samen batterijen voor elektrische voertuigen ontwikkelen
- Om een lekkende atmosfeer in beeld te brengen, NASA-raketteam trekt naar het noorden
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
