Wetenschap
Een diepgaande leerbenadering om de locatie van Twitter-gebruikers te identificeren tijdens noodgevallen
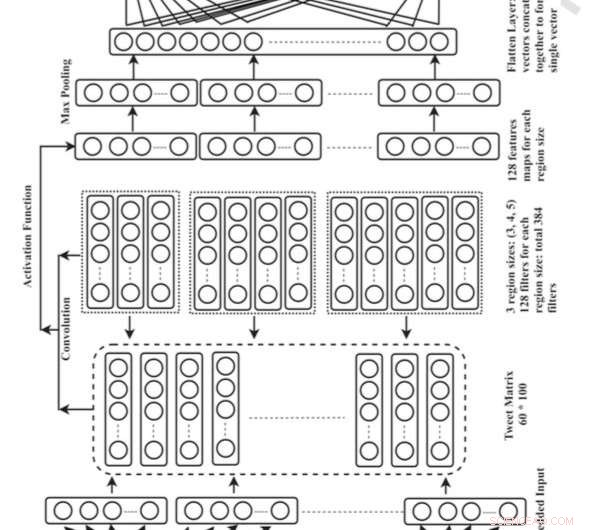
Algemene architectuur voor het Convolutional Neural Network (CNN). Krediet:Singh en Kumar.
Onderzoekers van het National Institute of Technology Patna, in India, hebben onlangs een instrument ontwikkeld om de geografische locatie van noodsituaties en rampen te identificeren, maar ook die van de mensen die erbij betrokken zijn. Hun aanpak, beschreven in een paper in de International Journal of Disaster Risk Reduction , haalt locatie-informatie uit tweets met behulp van een op convolutioneel neuraal netwerk (CNN) gebaseerd model.
"Tijdens calamiteiten, de geografische locatie-informatie van de evenementen, evenals die van de getroffen gebruikers, zijn van levensbelang, "Jyoti Prakash Singh, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Het identificeren van deze geografische locatie is een uitdagende taak, omdat beschikbare locatievelden zoals gebruikerslocatie en plaatsnaam van tweets niet betrouwbaar zijn. De precieze GPS-locatie van gebruikers is zeldzaam in tweets, en soms ook onjuist in termen van tijdruimtelijke informatie."
Mensen die getroffen zijn door natuurrampen of andere noodsituaties delen vaak hun locatie op sociale media, Vragen voor hulp. Deze informatie kan responseenheden en lokale autoriteiten helpen om gebeurtenissen vroegtijdig op te sporen, slachtoffers te lokaliseren en bij te staan. Echter, het extraheren van locatiegerelateerde gegevens uit tweets is een zeer uitdagende taak, aangezien deze vaak in niet-standaard Engels zijn geschreven en grammaticale fouten bevatten, spelfouten of afkortingen.
"Het is bijna onmogelijk voor menselijke operators die tweets volgen om door elke tweet te gaan en de daarin vermelde locatie-informatie te vinden. Singh zei. "Dit motiveerde ons om een oplossing te ontwikkelen om automatisch locatie-informatie te extraheren uit tweets die om hulp vragen. In dit werk, we hebben deep learning gebruikt om te bepalen of een tweet locatienamen bevat en deze woorden te markeren."
Singh en zijn collega Abhivan Kumar ontwikkelden een CNN-model dat de locatie van gebruikers kan identificeren door de inhoud van hun tweets te analyseren. Ze kozen voor deze specifieke deep learning-aanpak omdat het automatisch de beste weergave van invoergegevens kan leren en dit kan gebruiken om locatiereferenties te identificeren.
"We gebruikten een techniek voor het insluiten van woorden om tweets weer te geven op de invoerlaag van de CNN en locatiereferenties die aanwezig zijn in de tweet worden weergegeven in de uitvoerlaag in de vorm van een nul-één vector, " legde Singh uit. "De locatiewoorden zijn gecodeerd als 1 en de niet-locatiewoorden zijn gecodeerd als 0. We gebruikten verschillende combinaties van 2-gram, 3 gram, 4 gram, en filters van 5 gram om functies uit de tweet te extraheren. Na training voor het model voor de 100 tijdperken, het is in staat om de locatiereferenties die in de tweet worden genoemd met indrukwekkende nauwkeurigheid te voorspellen."
Bij een eerste evaluatie het door Singh en Kumar bedachte CNN-model was in staat om met zeer hoge nauwkeurigheid alle locatiegerelateerde woorden uit tweets te extraheren, zelfs als de tekst van een tweet luidruchtig was. De onderzoekers testten hun model op tweets die niet voorbewerkt waren en grammaticale fouten bevatten, typefouten, afkortingen, en andere verstorende factoren.
"De belangrijkste praktische implicatie van ons werk is dat het gemakkelijk kan worden gepijplijnd, met behulp van gebeurtenisdetectiemodellen, Singh zei. "Modellen voor gebeurtenisdetectie kunnen tweets identificeren die verband houden met de genoemde ramp en ons model kan de locatie achterhalen van de slachtoffers die door die ramp zijn getroffen."
In de toekomst, het door de onderzoekers ontwikkelde CNN-model zou kunnen helpen bij het snel lokaliseren van noodsituaties en mensen die dringend hulp nodig hebben. Dezelfde benadering kan ook worden toegepast op burgerlijke onrust, gerichte reclame, het observeren van regionaal menselijk gedrag, realtime wegverkeersbeheer en andere locatiegebaseerde diensten.
"In dit werk hebben we alleen Engelstalige tweets overwogen, maar tijdens een crisis plaatsen gebruikers ook tweets in hun regionale taal, Singh zei. "We werken daarom aan een model dat deze meertalige beperking aanpakt, terwijl we ook proberen een semi-gesuperviseerd model te ontwikkelen om het probleem van gegevenslabels te verminderen."
© 2018 Wetenschap X Netwerk

Hoofdlijnen
- Onverwachte vondst lost 40 jaar oud cytoskeletmysterie op
- Familiebanden Snapper leveren nieuw bewijs op over mariene reservaten
- De productie van recombinante menselijke groeihormonen door recombinante DNA-technologie
- Nieuwe hoop voor ernstig bedreigde aap met stompe neus in Myanmar
- Saoedi-Arabische rotskunst toont riemen op prehistorische honden
- Prokaryotische versus eukaryotische cellen: overeenkomsten en verschillen
- Interne factoren die van invloed zijn op celverdeling
- De afnemende populaties van koninginnenschelpen zijn gefragmenteerd en dat verandert het natuurbeschermingsspel
- Drie manieren waarop genetische diversiteit optreedt tijdens Meiosis
- Match me als je kunt:Cryptografische doorbraak helpt spionnen elkaar de hand te schudden

- Google AI-systeem kan menselijke experts overtreffen bij het opsporen van borstkanker, studie vondsten
- Frankrijk bereidt 1,5 miljard euro voor om AI-onderzoek te stimuleren

- Disney sluit deal van $ 71 miljard voor entertainmentactiva van Fox

- Naarmate internetspoofing beter wordt, je mag in een zee van haaien surfen


 Microbiële kolonisten van Arctische bodems zijn gevoelig voor toekomstige klimaatverandering
Microbiële kolonisten van Arctische bodems zijn gevoelig voor toekomstige klimaatverandering- NASA test waarnemingsvermogen op de koraalriffen van Hawaï
- Natuurkundigen observeren deeltjes die coherent werken terwijl ze faseovergangen ondergaan
- Turkse arts krijgt 15 maanden voor onthullen risico op kanker door vervuiling
- Klimaatverandering kan Amerikaanse sneeuwstormen drastisch verminderen
- Volkswagen zet 15 miljard euro in op elektrische auto's in China
- Hoe snel herstelt het klimaat?
- Definitie van Mean, Median & Mode
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
