Wetenschap
Een nieuwe dynamische ensemble-actieve leermethode gebaseerd op een niet-stationaire bandiet
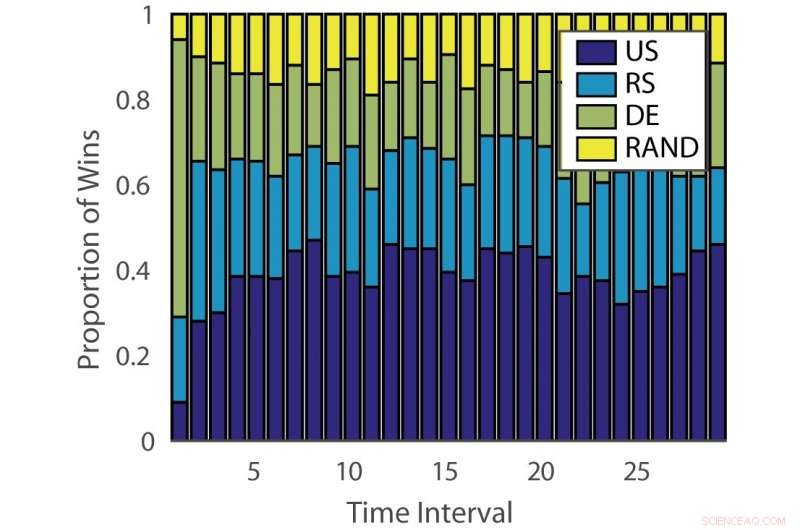
Aandeel van overwinningen:"ILPD". Krediet:Pang et al.
Onderzoekers van de Universiteit van Edinburgh, University College London (UCL) en Nara Institute of Science and Technology hebben een nieuwe aanpak voor actief leren ontwikkeld op basis van een niet-stationaire meerarmige bandiet en een algoritme voor deskundig advies. hun methode, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, kan de tijd en moeite die wordt geïnvesteerd in het handmatig annoteren van gegevens verminderen.
"Conventioneel gesuperviseerd machine learning is dataverslindend, en gelabelde gegevens kunnen een knelpunt zijn wanneer gegevensannotatie duur is, " Timoteüs Hospedales, vertelde een van de onderzoekers die het onderzoek uitvoerden aan Tech Xplore. "Actief leren ondersteunt begeleid leren door de meest informatieve datapunten te voorspellen om te annoteren, zodat goede modellen kunnen worden getraind met een lager annotatiebudget."
Actief leren is een specifiek gebied van machine learning waarin een leeralgoritme actief de gegevens kan kiezen waarvan het wil leren. Dit resulteert doorgaans in betere prestaties, met aanzienlijk kleinere trainingsdatasets.
Onderzoekers hebben verschillende actieve leeralgoritmen ontwikkeld die de kosten van annotatie, maar tot nu toe, geen van deze oplossingen is effectief gebleken voor alle problemen. Andere studies hebben daarom bandit-algoritmen gebruikt om het beste actieve leeralgoritme voor een bepaalde dataset te identificeren.
"De term 'bandiet' verwijst naar een meerarmige bandietengokautomaat, wat een handige wiskundige abstractie is voor exploratie-/exploitatieproblemen, Hospedales legde uit. "Een bandietenalgoritme vindt een goede balans tussen de inspanning die wordt besteed aan het verkennen van alle gokautomaten om erachter te komen welke het meest uitbetaalt, met inspanning besteed aan het exploiteren van de beste gokautomaat die tot nu toe is gevonden."
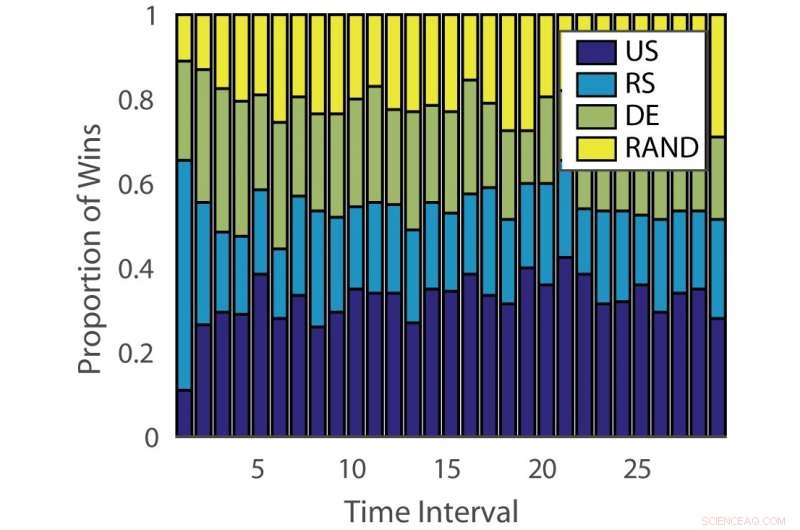
Aandeel van overwinningen:"duits". Krediet:Pang et al.
De doeltreffendheid van actieve leeralgoritmen varieert zowel tussen problemen als in de tijd in verschillende leerstadia. Deze observatie is analoog aan het spelen van gokautomaten, waar de uitbetalingskans in de loop van de tijd verandert.
"Het doel van onze studie was om een nieuw bandietenalgoritme te ontwikkelen dat de prestaties verbetert door rekening te houden met dit aspect van het actieve leerprobleem, ', aldus Hospedales.
Om deze beperking aan te pakken, de onderzoekers stelden een dynamische ensemble actieve leerling (DEAL) voor op basis van een niet-stationaire bandiet. Deze leerling maakt online een schatting van de effectiviteit van elk actief leeralgoritme, gebaseerd op de beloning (belanggewogen nauwkeurigheid) verkregen na elke annotatie van gegevens.
"Het doet dit door de voorkeur te gebruiken die voor dat punt wordt uitgedrukt door elk actief leeralgoritme, "Kunkun Pang, een andere onderzoeker die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Om het probleem van de veranderende effectiviteit van actieve leerlingen in de loop van de tijd aan te pakken, we herstarten het leeralgoritme periodiek om de actieve leerlingvoorkeur te vernieuwen. Met dit vermogen, als het meest effectieve algoritme voor actief leren verandert tussen vroege en late leerstadia, we kunnen ons snel aanpassen aan deze verandering."
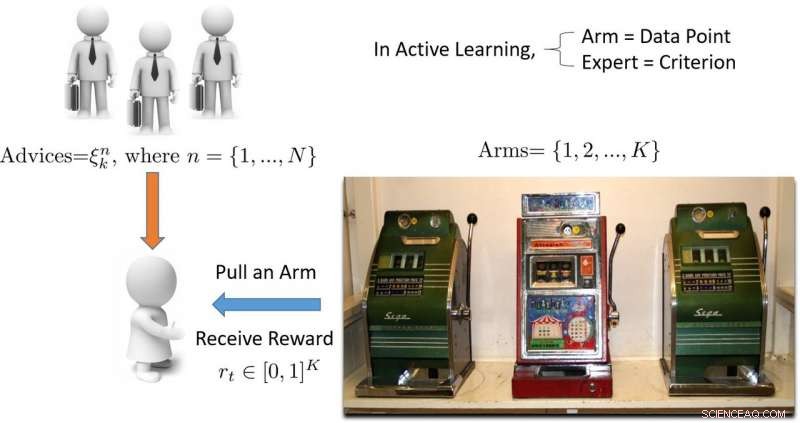
Illustratie van op multi-bewapende bandiet gebaseerde actieve leerbenadering. Krediet:Pang et al.
De onderzoekers testten hun aanpak op 13 populaire datasets, het behalen van zeer bemoedigende resultaten. Hun DEAL-algoritme heeft een wiskundige prestatiegarantie, wat betekent dat er een hoge mate van vertrouwen is in hoe goed het zal werken.
"De garantie heeft betrekking op de prestaties van ons algoritme, dat is dat van een ideaal orakel dat altijd de juiste keuze weet voor de actieve leerling, Hospedales legde uit. "Het biedt een grens aan de prestatiekloof tussen zo'n best-case algoritme en het onze."
De empirische evaluatie uitgevoerd door Hospedales en zijn collega's bevestigde dat hun DEAL-algoritme de actieve leerprestaties op een reeks benchmarks verbetert. Het doet dit door continu het meest effectieve actieve leeralgoritme te identificeren voor verschillende taken en in verschillende stadia van training.
"Vandaag, terwijl actief leren aantrekkelijk is, de impact ervan op machine learning-praktijken is beperkt vanwege het gedoe om algoritmen af te stemmen op problemen en leerstadia, " Hospedales zei. "DEAL elimineert deze moeilijkheid en biedt een aanpak om veel problemen en alle leerstadia aan te pakken. Door actief leren gebruiksvriendelijker te maken, we hopen dat het een grotere impact kan hebben op het verlagen van de annotatiekosten in de machine learning-praktijk."
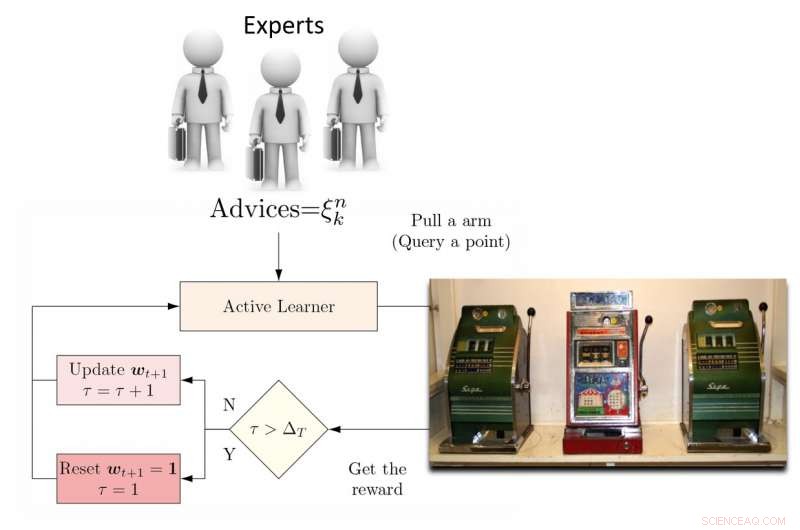
Illustratie van DEAL REXP4-algoritme. Krediet:Pang et al.
Ondanks de veelbelovende resultaten, de door de onderzoekers bedachte techniek kent nog een belangrijke beperking. DEAL doet al het leren binnen één probleem en dit resulteert in een 'koude start, ' wat betekent dat het algoritme alle nieuwe problemen met een schone lei benadert.
"In het lopende werk, we leren annoteren op veel verschillende problemen en deze kennis uiteindelijk over te dragen naar een nieuw probleem, om onmiddellijk effectieve annotaties uit te voeren zonder opwarmvereisten, "Zei Pang. "Ons voorbereidend werk over dit onderwerp is gepubliceerd en won ook de Best Paper-prijs op de ICML 2018 AutoML-workshop."
© 2018 Wetenschap X Netwerk

Hoofdlijnen
- Vissenseks zo luid dat dolfijnen doof kunnen worden
- Olifantenstroperij in Afrika neemt af, maar ivoorvangsten nemen toe:studie
- Luie valsspeler leeft onder de grond,
- Heb jij een innerlijke stem? Niet iedereen doet
- Wat zijn de verschillen tussen een CZS en een PNS?
- Native Plants & Animals of France
- Wat is de relatie tussen een chromosoom en een allel?
- Drones gebruiken om gewasschade door wilde zwijnen in te schatten
- De functie van macromoleculen






 Belangrijke metaforen in de meest populaire liefdesliedjes spreken van nabijheid en bezit
Belangrijke metaforen in de meest populaire liefdesliedjes spreken van nabijheid en bezit- Onderzoekers gebruiken nieuwe tools van datawetenschap om afzonderlijke moleculen in actie vast te leggen
- Schaliegas is een van de minst duurzame manieren om elektriciteit te produceren, onderzoek vindt
- We weten hoe we lezen moeten onderwijzen - waarom worden studenten er niet beter in?
- Wat is het verschil tussen 10, 14, 18 & 24 Carat Gold?
- Hoe de zonnen te berekenen Hoogte
- Levensduur verlengd door remming van gemeenschappelijk enzym
- Hoe de Hyperloop werkt
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | Italian |

-
Wetenschap © https://nl.scienceaq.com
