Wetenschap
Een nieuwe methode om nieuwsgierigheid te wekken bij lerende agenten
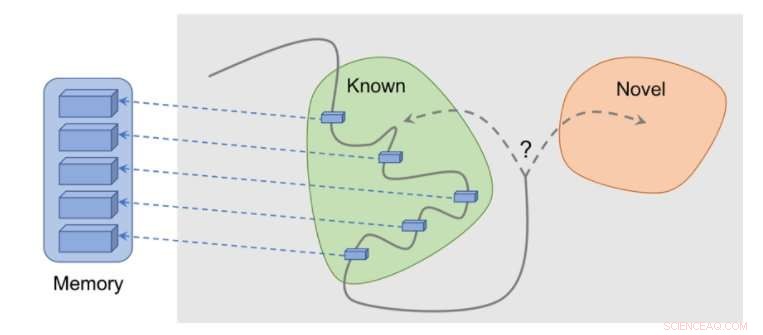
Hoe de methode werkt:waarnemingen worden aan het geheugen toegevoegd, beloning wordt berekend op basis van hoe ver onze huidige waarneming verwijderd is van de meest vergelijkbare waarneming in het geheugen. De agent krijgt meer beloning voor het zien van waarnemingen die nog niet in het geheugen zijn weergegeven. Krediet:Savinov et al.
Verschillende taken in de echte wereld hebben weinig beloningen en dit vormt een uitdaging voor de ontwikkeling van algoritmen voor het leren van versterking (RL). Een oplossing voor dit probleem is om een agent autonoom een beloning voor zichzelf te laten creëren, beloningen dichter en geschikter maken om te leren.
Bijvoorbeeld, geïnspireerd door het nieuwsgierige gedrag waarmee dieren hun omgeving verkennen, de waarneming van iets nieuws door een RL-algoritme kan worden beloond met een bonus. Deze bonus, samengevat met de echte taakbeloning, zou dan RL-algoritmen in staat stellen te leren van een gecombineerde beloning.
Onderzoekers van DeepMind, Google Brain en ETH Zürich hebben onlangs een nieuwe nieuwsgierigheidsmethode bedacht die episodisch geheugen gebruikt om deze nieuwigheidsbonus te vormen. Deze bonus wordt bepaald door huidige waarnemingen te vergelijken met waarnemingen die in het geheugen zijn opgeslagen.
"Het belangrijkste doel van ons werk was om nieuwe, op geheugen gebaseerde manieren te onderzoeken om agenten voor het leren van versterking (RL) te doordringen van 'nieuwsgierigheid, ' waarmee we een drive bedoelen om de omgeving te verkennen, zelfs in de volledige afwezigheid van beloningen, Tim Lillicrap bij DeepMind en Nikolay Savinov bij Google Brain vertelden TechXplore in een e-mail. "Nieuwsgierigheid is op verschillende manieren benaderd door de onderzoeksgemeenschap, maar we waren van mening dat verschillende ideeën baat zouden kunnen hebben bij verdere verkenning."
De belangrijkste ideeën die in dit recente artikel zijn onderzocht, zijn gebaseerd op een eerdere studie uitgevoerd door Savinov, die een nieuwe geheugenarchitectuur voorstelde, geïnspireerd op de navigatie van zoogdieren. Met deze architectuur kunnen agenten een route door een omgeving herhalen met alleen een visuele walkthrough. De nieuwe methode ontwikkeld door de onderzoekers gaat nog een stap verder, proberen te komen tot een goede verkenning gedreven door nieuwsgierigheid.
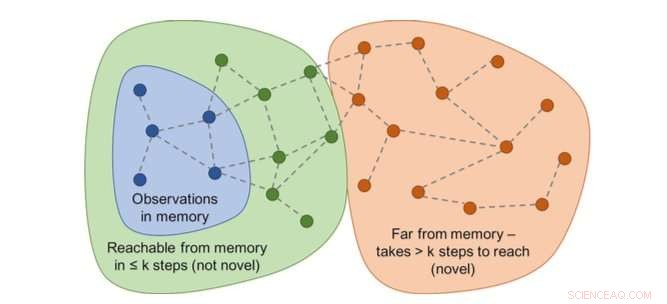
Grafiek van bereikbaarheid zou nieuwheid bepalen. In praktijk, deze grafiek is niet beschikbaar - dus een neuraal netwerkbenadering is getraind om een aantal stappen tussen waarnemingen te schatten. Krediet:Savinov et al.
"Tijdens het acteren, de agent slaat voorbeelden van waarnemingsrepresentaties op in zijn episodische geheugen, Lillicrap en Savinov zeiden. "Om te bepalen of de huidige waarneming nieuw is of niet, het wordt vergeleken met die in het geheugen. Als er niets vergelijkbaars wordt gevonden, de huidige waarneming wordt als nieuw beschouwd en de agent wordt beloond, anders krijgt het een negatieve beloning. Dit moedigt de agent aan om onbekend terrein te verkennen, vergelijkbaar met nieuwsgierig zijn."
De onderzoekers ontdekten dat het vergelijken van observatieparen lastig kan zijn, omdat het controleren op een exacte overeenkomst uiteindelijk zinloos is in realistische omgevingen. Dit komt omdat in echte situaties, een agent observeert zelden twee keer hetzelfde.
"In plaats daarvan, we hebben een neuraal netwerk getraind om te voorspellen of de agent de huidige waarneming van degenen in het geheugen kan bereiken door minder acties te ondernemen dan een vaste drempel; zeggen, vijf acties, Lillicrap en Savinov legden uit. "Waarnemingen binnen die vijf acties worden als vergelijkbaar beschouwd, terwijl degenen die meer acties nodig hebben om een overgang te maken als ongelijksoortig worden beschouwd."
Lillicrap, Savinov en hun collega's testten hun aanpak in VizDoom en DMLab, twee visueel rijke 3D-omgevingen. In VizDoom, de agent leerde om met succes naar een ver doel te navigeren, minstens twee keer sneller dan de state-of-the-art nieuwsgierigheidsmethode ICM. In DMLab, het algoritme generaliseerde goed naar nieuw, procedureel gegenereerde niveaus van het spel, het bereiken van het gewenste doel minstens twee keer vaker dan ICM op testdoolhoven met zeer schaarse beloningen.

Op verrassing gebaseerde methode (ICM) is het voortdurend markeren van muren met een laserachtig sciencefictiongadget in plaats van het doolhof te verkennen. Dit gedrag is vergelijkbaar met het eerder beschreven kanaalwisseling:hoewel het resultaat van tagging theoretisch voorspelbaar is, het is niet gemakkelijk en vereist blijkbaar een grondige kennis van de natuurkunde die niet eenvoudig te verwerven is voor een algemeen agent. Krediet:Savinov et al.
"We merkten een interessant nadeel op in een van de meest populaire methoden om agenten nieuwsgierig te maken, " zeiden Lillicrap en Savinov. "We ontdekten dat deze methode, gebaseerd op de verrassing die wordt berekend door een langzaam veranderend model dat probeert te voorspellen wat er daarna gaat gebeuren, kan resulteren in een onmiddellijke bevredigingsreactie van de agent:in plaats van de taak op te lossen, het zal acties uitbuiten die tot onvoorspelbare gevolgen leiden om onmiddellijke beloning te krijgen."
Dit eigenaardige voorval, ook bekend als "couch-potato" problemen, houdt in dat een agent manieren vindt om zichzelf onmiddellijk te bevredigen door acties uit te buiten die tot onvoorspelbare gevolgen leiden. Bijvoorbeeld, als je een tv-afstandsbediening krijgt, de agent kan niets anders doen dan van kanaal veranderen, ook al was zijn oorspronkelijke taak geheel anders, zoals het zoeken naar een doel in een doolhof.
"Deze tekortkoming kan worden verholpen door het episodisch geheugen te gebruiken, samen met een redelijke mate van waarnemingsovereenkomst, dat is onze bijdrage, " zeiden Lillicrap en Savinov. "Dit opent een weg naar meer intelligente verkenning."

Onze methode laat een redelijke verkenning zien. Krediet:Savinov et al.
De nieuwe nieuwsgierigheidsmethode bedacht door Lillicrap, Savinov, en hun collega's zouden kunnen helpen om nieuwsgierigheidachtige vaardigheden in RL-algoritmen te repliceren, waardoor ze autonoom beloningen voor zichzelf kunnen creëren. In de toekomst, de onderzoekers willen het episodisch geheugen niet alleen gebruiken voor het toekennen van beloningen, maar ook voor het plannen van acties.
"Bijvoorbeeld, kan inhoud die uit het geheugen is opgehaald, worden gebruikt om na te denken over de volgende stap?", aldus Lillicrap en Savinov. "Dit is momenteel een grote wetenschappelijke uitdaging:als het wordt opgelost, agenten zouden exploratiestrategieën snel kunnen aanpassen aan nieuwe omgevingen, waardoor leren in een veel sneller tempo kan gebeuren."
© 2018 Tech Xplore
 Chemici brengen een kunstmatige moleculaire zelfassemblage in kaart met de complexiteit van het leven
Chemici brengen een kunstmatige moleculaire zelfassemblage in kaart met de complexiteit van het leven- Trilling slechts in één richting
- Uitvinding van 's werelds sterkste zilver
- Een nieuw magnetisch materiaal en opnameproces om de datacapaciteit enorm te vergroten
- Ingenieurs 3D printen zeer sterk aluminium, los eeuwenoud lasprobleem op met nanodeeltjes
- Hoe het geslacht van baby Deer
- Russisch noordpoolgebied vestigt fantastische hitterecords:weerchef
- Een aardbeving met een kracht van 6,6 op de schaal van Richter treft Sumatra in Indonesië:USGS
- Wanneer groene oplossingen de ecologische voetafdruk daadwerkelijk vergroten
- Beheer van zeeafval:efficiëntie van recycling door mariene microben
Hoofdlijnen
- Het verschil tussen craniologie en frenologie
- Verschillen tussen Protozoa en Protisten
- Woestijnsprinkhanen - nieuwe risico's in het licht van klimaatverandering
- Voorbeelden van stoffen die gefaciliteerde diffusie gebruiken
- Verloren Australische duiker zwom mijlen naar kust gestalkt door haai
- Wat maakt de mens menselijk?
- Vermont ziet hedendaags record voor reproductie van Amerikaanse zeearenden
- Reuzenzeebaars heeft meer waarde als levend, onderzeese wonderen ademen dan als commerciële vangst
- Hoe de griezelige verkenningen van de zomer
- Mysterie van de vrachtschepen die zinken wanneer hun lading plotseling vloeibaar wordt

- Het detecteren van deepfakes door goed te kijken, onthult een manier om zich ertegen te beschermen

- Micromotoren duwen rond enkele cellen en deeltjes

- Ocean Resort Casino sluit zich aan bij de internetwedmarkt in New Jersey

- Google bevestigt dat het een betaalpas wil vrijgeven


 Palladiumkatalysator versnelt twee afzonderlijke reacties, bruikbare moleculen maken in één proces
Palladiumkatalysator versnelt twee afzonderlijke reacties, bruikbare moleculen maken in één proces- Zonnecellen van de volgende generatie presteren beter als er een camera in de buurt is
- Onderzoekers creëren een apparaat voor vroege ziektedetectie en medicijnafgifte voor afzonderlijke levende cellen
- Nanotech transformeert katoenvezels in modern wonder
- Ruimtewandeling voor Thomas Pesquet
- Tunnelvisie voor bestelwagens kan vervuiling verminderen
- Scholen wijzen de kans af om kinderen les te geven in gemengde klassen
- Fout gevonden in waterbehandelingsmethode:het proces kan onbewust schadelijke chemicaliën genereren
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | French |

-
Wetenschap © https://nl.scienceaq.com
