Wetenschap
Facebook-onderzoekers bouwen een dataset om gepersonaliseerde dialoogagenten te trainen
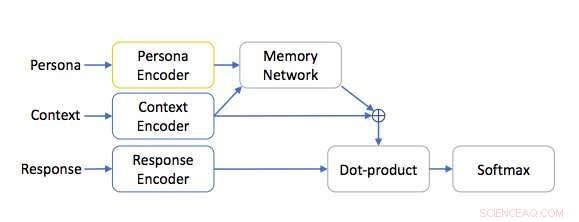
Op persona gebaseerde netwerkarchitectuur. Krediet:Mazaré et al.
Onderzoekers van Facebook hebben onlangs een dataset samengesteld van 5 miljoen persona's en 700 miljoen persona-gebaseerde dialogen. Deze database kan worden gebruikt om end-to-end dialoogsystemen te trainen, wat resulteert in meer boeiende en rijke dialogen tussen computeragenten en mensen.
Dialoogsystemen, of gespreksagenten (CA), zijn computersystemen die zijn ontworpen om via tekst met mensen te communiceren, toespraak, grafiek, of andere methoden, op een coherente manier. Tot dusver, dialoogsystemen gebaseerd op neurale architecturen, zoals LSTM's of geheugennetwerken, zijn bijzonder veelbelovend gebleken bij het bereiken van vloeiende communicatie, vooral wanneer ze rechtstreeks op dialooglogboeken worden getraind.
"Een van hun belangrijkste voordelen is dat ze kunnen vertrouwen op grote gegevensbronnen van bestaande dialogen om verschillende domeinen te leren bestrijken zonder dat daarvoor specialistische kennis nodig is, " schreven de onderzoekers in hun paper, die voorgepubliceerd was op arXiv. "Echter, de keerzijde is dat ze ook een beperkte betrokkenheid vertonen, vooral in chit-chat-instellingen:ze missen consistentie en maken geen gebruik van proactieve betrokkenheidsstrategieën zoals (zelfs gedeeltelijk) gescripte chatbots."
In een recente studie, een ander team van onderzoekers van het Montreal Institute for Learning Algorithms (MILA) en Facebook AI heeft een dataset gemaakt met de naam PERSONA-CHAT, waaronder dialogen tussen agenten met tekstprofielen, of persona's, aan hen gehecht. Ze ontdekten dat het trainen van een dialoogsysteem over een bepaalde persona hun betrokkenheid bij interacties verbeterde.
"Echter, de PERSONA-CHAT-dataset is gemaakt met behulp van een kunstmatig gegevensverzamelingsmechanisme op basis van Mechanical Turk, " verklaarden de onderzoekers in hun paper. "Als gevolg hiervan, noch dialogen noch persona's kunnen volledig representatief zijn voor echte interacties tussen gebruikers en bots en de dekking van de dataset blijft beperkt, met iets meer dan 1k verschillende persona's."
Om de beperkingen van de eerder samengestelde dataset aan te pakken, de Facebook-onderzoekers creëerden een nieuwe, grootschalige op persona gebaseerde dialoogdataset, samengesteld uit gesprekken die zijn geëxtraheerd van online platform Reddit. Hun studie brengt het werk van hun voorgangers nog een stap verder, door gebruik te maken van meer representatieve interacties.
"In deze krant, we bouwen een zeer grootschalige persona-gebaseerde dialoogdataset met behulp van gesprekken die eerder zijn geëxtraheerd uit Reddit, " schreven de onderzoekers. "Met eenvoudige heuristieken, we creëren een corpus van meer dan 5 miljoen persona's, verspreid over meer dan 700 miljoen gesprekken."
Om de effectiviteit ervan te evalueren, de onderzoekers trainden persona-gebaseerde end-to-end dialoogsystemen op hun nieuw ontwikkelde dataset. Systemen die op hun dataset waren getraind, waren in staat om boeiendere gesprekken te voeren, beter presteren dan andere gesprekspartners die tijdens hun training geen toegang hadden tot persona's.
interessant, hun dataset leidde tot state-of-the-art resultaten, zelfs wanneer dialoogsystemen er alleen maar op waren getraind. In de toekomst, deze bevindingen kunnen leiden tot de ontwikkeling van meer boeiende chatbots, die ook kan worden gepersonaliseerd en getraind om een bepaalde persona te verwerven.
"We laten zien dat trainingsmodellen om antwoorden af te stemmen op zowel de persona van hun auteur als de context de voorspellende prestaties verbeteren, " schreven de onderzoekers. "Omdat pre-training leidt tot aanzienlijke prestatieverbetering, toekomstig werk zou dit model kunnen verfijnen voor verschillende dialoogsystemen."
© 2018 Tech Xplore
 Vliegenlarven bleken bij te dragen aan atmosferische methaanvervuiling
Vliegenlarven bleken bij te dragen aan atmosferische methaanvervuiling- Wat is de prooi in een ecosysteem?
- Great Barrier Reef-koralen kunnen de opwarming van de aarde nog een eeuw overleven
- Onderzoekers ontdekken bewijs van aardbevingen die de Chileense kust in de afgelopen 9 hebben getroffen 000 jaar
- Oceaan verandert bijna uitgehongerd leven van zuurstof
Hoofdlijnen
- Nieuwsgierige grote witte haai speelt met camera
- Moderne celtheorie
- Waarom lijden 600 meisjes in Mexico aan collectieve hysterie?
- Cel Life Functies
- Hoe een TAPPI-kaart te gebruiken
- Zeldzame olifanten redden met toeristische kiekjes
- Genetische aandoeningen: definitie, oorzaken, lijst met zeldzame en veel voorkomende ziekten
- Onderzoeker onderzoekt de rol van kleine RNA's in communicatie tussen cellen
- Wat is een prehistorische toolkit en hoe zou het de menselijke geschiedenis kunnen herschrijven?
- WaveGlow:een op stroom gebaseerd generatief netwerk om spraak te synthetiseren
- Facebook gaat verder met muziek met laatste deal met grote labels

- Eerste vlucht Boeings 777X gepland voor donderdag:bronnen

- Fortnites verhuizen naar bots:welke invloed heeft dit op menselijke spelers?

- Rapporten:FTC kan proberen Facebook te blokkeren voor het integreren van apps


 Patronen die typisch in water worden waargenomen, zijn ook te vinden in licht
Patronen die typisch in water worden waargenomen, zijn ook te vinden in licht- Nanobuisjes helpen genezende harten het ritme te behouden
- AI-gegenereerde profielen? Airbnb-gebruikers geven de voorkeur aan een menselijke touch
- Onderzoekers onderzoeken stoelaccommodatie in vliegtuig
- Nike slimme sneakers ervaren verbindingsproblemen dagen na release, gebruikers melden:
- AI-tool detecteert wereldwijde modetrends
- Nieuw-Zeelandse sinkhole onthult een glimp van 60, 000 jaar oude vulkaan
- Door elektriciteit aangedreven onderzeese reacties kunnen belangrijk zijn geweest voor het ontstaan van leven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
