Wetenschap
Machine learning gebruiken voor meertalige en platformonafhankelijke geruchtenverificatie
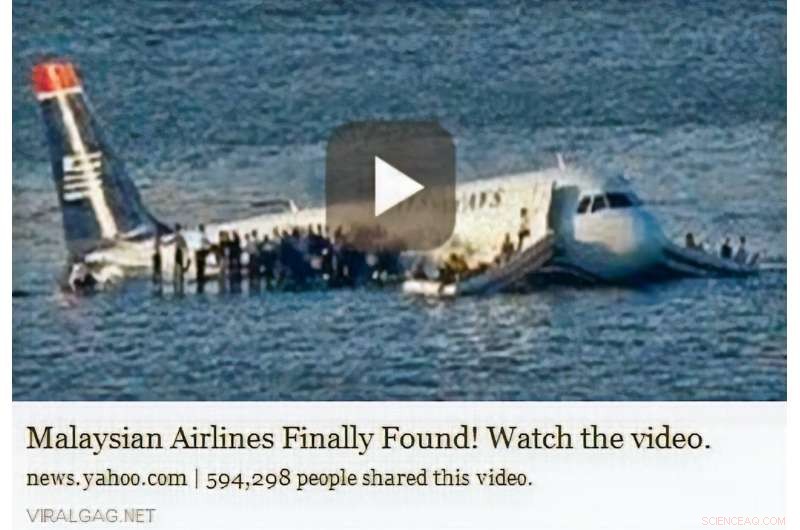
Een video van vlucht 1549 van US Airways is geleend door nieuws over vlucht 370 van Malaysia Airlines. Credit:Wen, Zo &Yu.
Onderzoekers van UC Davis hebben onlangs een nieuwe tool ontwikkeld op basis van machine learning om multimediageruchten online te verifiëren. hun papier, voorgepubliceerd op arXiv, stelt meertalige en platformonafhankelijke functies voor voor geruchtenverificatie, die gebruikmaken van de semantische overeenkomst tussen geruchten en informatie op andere websites. Hun methode kan informatie uit meerdere talen combineren om een compleet beeld te krijgen van online nieuws.
Een groeiend aantal mensen wereldwijd gebruikt nu apparaten om het nieuws te lezen en te leren over wat er in de wereld gebeurt. Echter, sociale mediaplatforms zijn grotendeels niet-gemodereerd, wat resulteert in de verspreiding van nepnieuws, die vaak gepaard gaat met gefabriceerde of gedecontextualiseerde multimedia-inhoud. Valse geruchten kunnen zich heel snel online verspreiden, veroorzaakt ravage en verwarring onder de lezers, daarom is de ontwikkeling van tools om de authenticiteit van online informatie te verifiëren van groot belang.
"Ons onderzoek is geïnspireerd op de toenemende populariteit van nepnieuws, gekoppeld aan multimedia-inhoud op sociale netwerken, "Weiming Wen, een van de afgestudeerde onderzoekers die het onderzoek hebben uitgevoerd, vertelde TechXplore. "Het gaat er vooral om hoe je NLP-technieken kunt gebruiken om geruchten met multimedia-inhoud te verifiëren. Het basisidee is om het probleem op te lossen door middel van machine learning - specifieke functies uit dit soort geruchten halen en een model bouwen om geruchten als nep of echt te classificeren."
Eerder onderzoek naar geruchtenverificatie gebruikte multimedia-inhoud als invoerfuncties, gebruikmaken van forensische kenmerken van afbeeldingen of video's om te bepalen of ermee is geknoeid. Hoewel deze afbeelding verbeterde resultaten biedt, de meeste van deze onderzoeken konden multimedia-inhoud niet effectief gebruiken om geruchten op Twitter consequent te verifiëren.
Een mogelijke reden hiervoor is dat vaak multimedia-inhoud die aan nepnieuws is gekoppeld, is slechts ontleend aan authentieke gebeurtenissen en is enigszins semantisch afgestemd op de bijbehorende tekst. Dit betekent dat het beeld zelf echt is, maar wordt in een heel ander verhaal geplaatst om het nepgerucht geloofwaardiger te maken.
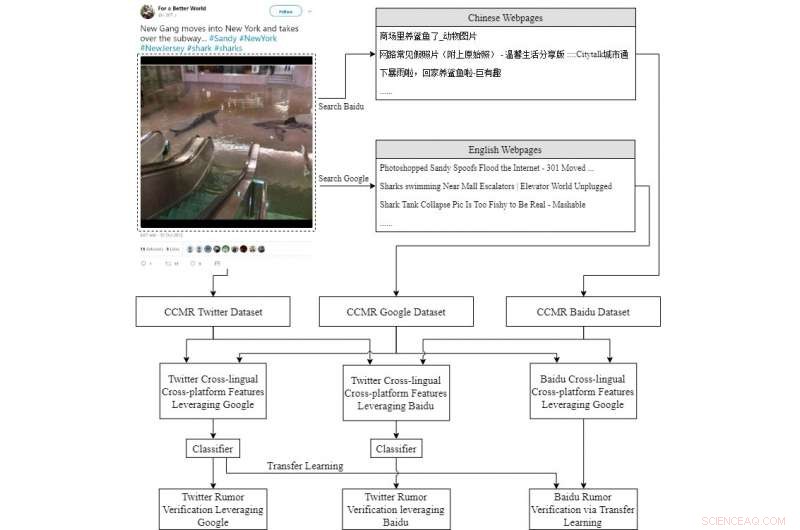
De informatiestroom van onze voorgestelde pijplijn. TFG vertegenwoordigt de meertalige platformonafhankelijke functies voor tweets die gebruikmaken van Google-informatie, terwijl TFB vergelijkbaar is, maar in plaats daarvan gebruikmaakt van Baidu-informatie. BFG betekent meertalige platformonafhankelijke functies voor Baidu die gebruikmaken van Google-informatie. Krediet:Wen, Zo &Yu.
De onderzoekers van UC Davis stelden een alternatieve manier voor om geruchten te verifiëren die gebruik maken van multimedia-inhoud door informatie te vinden die ermee verband houdt op andere nieuwsplatforms.
De meeste bestaande gegevenssets voor geruchtenverificatie zijn eentalig, bijvoorbeeld, alleen multimedia-inhoud met Engelse of Chinese tekst. De onderzoekers creëerden een nieuwe, meertalige, cross-platform geruchten verificatie dataset (CCMR), bestaande uit drie subdatasets:CCMR Twitter, CCMR Google en CCMR Baidu.
"Als we multimediageruchten zeggen, we bedoelen tweets of andere sociale media-inhoud die niet zijn geverifieerd en afbeeldingen of video's hebben samen met de tekst, "Zhou Yu, assistent-professor aan UC Davis, die de studie heeft uitgevoerd, vertelde TechXplore. "Tekst en beeld worden beschouwd als twee verschillende informatiekanalen. We maken op een innovatieve manier gebruik van visie-informatie, gebruiken als een spil om nieuws van verschillende platforms en in verschillende talen te koppelen."
De functies die door de onderzoekers zijn ontwikkeld, integreren zowel het gerucht als de bijbehorende titels op verschillende webpagina's in 300-dimensionale vectoren met een vooraf getrainde meertalige inbedding van zinnen. Ze trainden hun meertalige algoritme voor het insluiten van zinnen op 453, 000 paren Engels en Chinees parallel nieuws, evenals microblogs in de UM-Corpus-dataset. Dit algoritme kan nieuws uit meerdere talen combineren, het bereiken van een effectievere verificatie van geruchten.
"Gezien een gerucht bijgevoegd met een afbeelding, we zoeken eerst de afbeelding via Google Image om een aantal gerelateerde berichten te krijgen, Wen legde uit. "Vervolgens extraheren we kenmerken van dit gerucht door de gelijkenis en overeenkomst tussen het gerucht en de gezochte berichten te berekenen. Eindelijk, we gebruiken ons vooraf getrainde model om dit gerucht te verifiëren met behulp van zijn functies."

Voorbeeld van parallelle geruchten in het Pig Fish-evenement. Krediet:Wen, Zo &Yu. Krediet:Wen, Zo &Yu.
Wanneer getest, machine learning-methoden die gebruikmaakten van de door de onderzoekers voorgestelde cross-linguale en cross-platform-functies, leverden state-of-the-art resultaten op het gebied van geruchtenverificatie. Deze functies bleken ook compact en generaliseerbaar over talen te zijn.
"Ik denk dat het meest betekenisvolle deel van ons onderzoek is dat we een geruchtenverificatieraamwerk hebben ontwikkeld dat specifiek werkt voor multimediageruchten, wat zeer gebruikelijk is, maar is niet grondig bestudeerd, " zei Wen. "Met dit raamwerk, we kunnen multimediageruchten van platforms zoals Facebook en Twitter efficiënt verifiëren."
Dit onderzoek zou een belangrijke mijlpaal kunnen zijn op weg naar het ontwikkelen van effectieve manieren om online geruchten te valideren die vergezeld gaan van multimedia-inhoud. Bovendien, de Engels-Chinese dataset die door de onderzoekers is samengesteld, zou kunnen worden gebruikt in verder onderzoek naar methoden voor meertalige geruchtenverificatie.
"In de toekomst, we zijn van plan redenen te genereren voor onze verificatieresultaten over multimediageruchten, "Zei Wen. "Naast het classificeren van een gerucht als nep, we willen ook automatisch een reden genereren, zoals 'dit bericht is nep omdat het een afbeelding van een ander evenement leent om zijn verklaring te bewijzen, ' zei Ween.
© 2018 Tech Xplore
 Hoogwaardige katalysatoren op basis van grafeen
Hoogwaardige katalysatoren op basis van grafeen- Nieuwe studie helpt bij het karakteriseren van de fusie van metalen
- Langzame opwekking van lading speelt grote rol in modelmateriaal voor zonnecellen
- Chemici testen het vermogen van Chemica om synthetische routes te genereren
- De ontdekking van vloeibaar metaal luidt een nieuwe golf van chemie en elektronica in
- Nieuwe studie onthult scheuren onder gigantische, methaan stromende kraters
- Inzicht in de omslagpunten van klimaatverandering uit het verleden kan ons helpen ons voor te bereiden op de toekomst
- Arseen in huishoudelijk bronwater kan twee miljoen mensen in de VS treffen
- Een zeewering van 20 voet zal Miami niet redden:hoe levende structuren de kust kunnen helpen beschermen
- Gigantische ijsberg klaar om af te kalven van Larsen C-ijsplaat
Hoofdlijnen
- Project om het publiek toegang te geven tot 3D-modellen met hoge resolutie van de anatomie van gewervelde dieren
- Dolfijnen- en berenstudies maken de weg vrij voor verbeterde populatieprognoses
- Wat is Feedback-inhibitie en waarom is het belangrijk bij het reguleren van enzymactiviteit?
- Wat veroorzaakt het uitsterven van planten en dieren?
- Wat gebeurt er met plantaardige en dierlijke cellen wanneer ze worden geplaatst in hypertone, hypotone en isotone omgevingen?
- Methode stelt onderzoekers in staat lichaamsgeurmonsters van zoogdieren op een niet-invasieve manier te verzamelen
- Lokale elektrische reacties in bladeren maken fotosynthese hittetolerant
- Vogelgriep:Nederlandse boeren moeten pluimvee binnen houden
- Wat zijn stamcellen en waarvoor worden ze gebruikt?
- Airbus test levering van drones aan schepen

- Computeranimatie wendbaarder maken, acrobatisch - en realistisch

- Studie vindt raciale vooroordelen in tweets die zijn gemarkeerd als aanzetten tot haat

- Autonoom transport zal de toekomst van steden vormgeven - het is het beste om vroeg op het juiste pad te komen

- Rekbare elektronica opbouwen om net zo multifunctioneel te zijn als uw smartphone


 Nieuw milieudetectie- en monitoringsysteem getest en geëvalueerd
Nieuw milieudetectie- en monitoringsysteem getest en geëvalueerd- Studie levert bewijs voor nieuwe natuurkunde
- Wat werd er gedaan voordat Dynamite werd uitgevonden?
- Klimaatverandering, menselijke activiteit leidt tot afname van de koraalgroei in de buurt van de kust
- Soundblasting van een satelliet:time-lapse van testen
- Postdoctorale onderzoekers in Columbia stemmen voor vakbondsvorming
- Wetenschappers zien vingerafdrukken van opwarmend klimaat op droogtes die teruggaan tot 1900
- Hoe lees ik schaalgrafieken
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
