Wetenschap
Onderzoeksteam ontwikkelt universele en nauwkeurige methode om te berekenen hoe eiwitten interageren met medicijnen
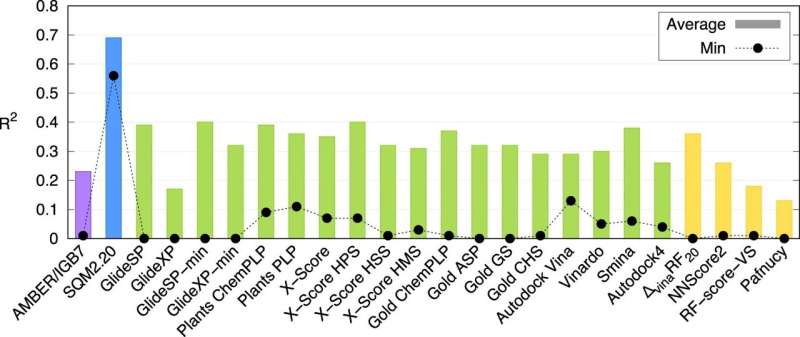
Een onderzoeksteam van het Instituut voor Organische Chemie en Biochemie van de Tsjechische Academie van Wetenschappen / IOCB Praag heeft een nieuwe computationele methode ontwikkeld die nauwkeurig kan beschrijven hoe eiwitten interageren met moleculen van potentiële medicijnen en dat in slechts tientallen minuten. Deze nieuwe kwantummechanische scorefunctie kan de zoektocht naar nieuwe medicijnen dus aanzienlijk versnellen. Het onderzoek is gepubliceerd in het tijdschrift Nature Communications .
Uit het onderzoek blijkt dat dit de eerste universeel toepasbare methode in zijn soort is. Computerexperts van IOCB Praag hebben het getest op 10 eiwitten met verschillende niveaus van structurele complexiteit, die elk een grote verscheidenheid aan kleine moleculen binden (meestal liganden genoemd). Vervolgens vergeleken ze hun resultaten niet alleen met die van andere overeenkomstige methoden, maar ook met bevindingen uit laboratoriumexperimenten, en beide vergelijkingen pakten zeer gunstig uit.
"Natuurlijk zijn wij niet de enigen die hieraan werken. Er zijn verschillende van dergelijke methoden. Meestal wordt hun snelheid echter gecompenseerd door een lage nauwkeurigheid, terwijl nauwkeurigere berekeningen meerdere dagen kunnen duren. Onze methoden zijn uniek omdat ze informatie kunnen verwerken over grote moleculaire systemen binnen tientallen minuten, terwijl de voordelen van veel veeleisendere kwantummechanische berekeningen behouden blijven”, legt Jan Řezáč uit, corresponderend auteur van het artikel van de Non-Covalent Interactions-groep onder leiding van prof. Pavel Hobza.
Deskundigen uit deze groep bestuderen al lange tijd intermoleculaire interacties. In dit onderzoek richten ze zich vooral op biomoleculen, en de resultaten van hun werk hebben rechtstreeks betrekking op het computerondersteunde ontwerp van medicijnen. De reden is dat wanneer wetenschappers aan een nieuw medicijn werken, ze vaak op zoek gaan naar moleculen die sterk binden aan een bepaald eiwit.
Het identificeren ervan lijkt echter op het vinden van spelden in een hooiberg, omdat grote aantallen moleculen moeten worden getest om de veelbelovende moleculen van elkaar te onderscheiden. Dit vertraagt de ontdekking van geneeskrachtige stoffen aanzienlijk en maakt deze duurder. Door de sterkte van de binding tussen eiwitten en liganden te voorspellen, en zo moleculen uit te kiezen die het beste aan een gedefinieerde reeks criteria voldoen, sparen computationele scheikundigen het werk van onderzoekers, wat op zijn beurt de ontdekking van geneesmiddelen aanzienlijk versnelt.
Meer informatie: Adam Pecina et al, SQM2.20:Semi-empirische kwantummechanische scorefunctie levert binnen enkele minuten voorspellingen van eiwit-ligandbindingsaffiniteit van DFT-kwaliteit op, Nature Communications (2024). DOI:10.1038/s41467-024-45431-8
Journaalinformatie: Natuurcommunicatie
Geleverd door het Instituut voor Organische Chemie en Biochemie van de CAS
 Bacterieel cellulose-afbraaksysteem kan de productie van biobrandstoffen stimuleren
Bacterieel cellulose-afbraaksysteem kan de productie van biobrandstoffen stimuleren- Uitbreidbaar schuim voor 3D-printen van grote objecten
- Moderne alchemie creëert lichtgevende ijzermoleculen
- Chemici brengen gemengde gevouwen eiwitten tot leven
- Nieuwe mogelijkheden voor medisch gebruik van botulinetoxine A1
- Verkenners hebben zojuist de diepste grot van Australië ontdekt. Een hydrogeoloog legt uit hoe ze ontstaan
- Maak een lijst van drie factoren die van invloed zijn op de windrichting
- Aquatic rover gaat voor een ritje onder het ijs
- Paasstormen razen naar het zuiden, minstens 20 mensen vermoorden
- Nieuwe gegevens onthullen Britse zeespiegelrecords die 200 jaar teruggaan
Hoofdlijnen
- Wat zijn enkele voor- en nadelen van het gebruik van DNA-analyse om wetshandhaving bij misdrijven te ondersteunen?
- Ecologische onderzoeksmethoden: observeren, experimenteren en modelleren
- Aquatische wiet behoort tot de ergste ter wereld en breidt zich uit in het noordoosten van de VS
- Ontdekt in planten een mechanisme dat defecten in eiwitvouwing corrigeert
- Wat is troebelheid en wat staat er in de microbiologie?
- Genomics-onderzoek identificeert een unieke set eiwitten die het gehoor bij zebravissen herstellen
- Dode vissen en depressies aan de oevers van de Oder
- Het overdrachtspotentieel van vliegen kan groter zijn dan gedacht, onderzoekers zeggen:
- Gebruik van microscopen in de wetenschap
- Wegenkaart schetst hindernissen bij de ontwikkeling van kathodes van de volgende generatie voor het aandrijven van elektrische voertuigen
- Farmacoscopie maakt immunomodulerende geneesmiddelenontdekking mogelijk door immuuncelinteracties te analyseren

- Een veranderende platina-elektrode observeren

- Onderzoekers zetten algenresten om in hernieuwbare producten met flare

- Nieuw additief biedt brandbeveiliging voor hout


 Navigeren door het AI-doolhof is een uitdaging voor overheden
Navigeren door het AI-doolhof is een uitdaging voor overheden- Mac-softwarebedreigingen zijn in 2019 met 400% gestegen, meer dan Microsoft Windows, rapport zegt
- Hoe zwarte gaten sterrenstelsels vormen
- 5 Vereisten om een mineraal te zijn
- 11% kans op een nieuwe enorme aardbeving in Zuid-Californië, wetenschappers zeggen:
- Molybdeenboride-keramiek ontwikkeld voor SERS-detectie in ruwe omgevingen
- Onderzoekers zien in realtime scheurvorming in 3D-geprint wolfraam
- Burgers dragen zelf bij aan politiek wantrouwen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
