Wetenschap
Luchtvervuiling opsporen met satellieten, beter dan ooit tevoren
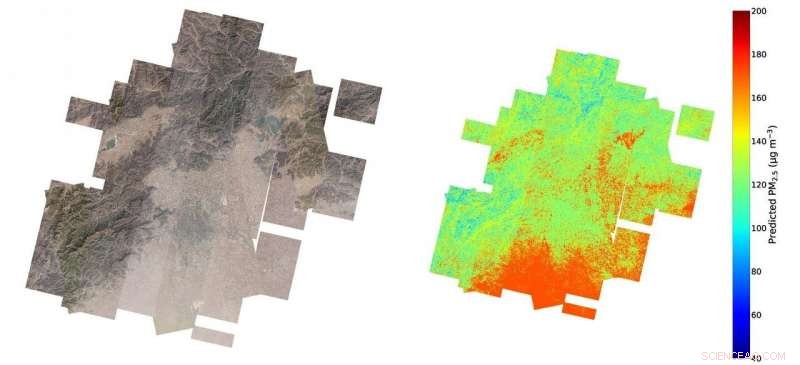
Een gedetailleerde kaart van de vervuilingsniveaus in Peking en de omliggende gebieden met behulp van een nieuw machine learning-algoritme voor satellietbeelden en weer. Krediet:Tongshu Zheng, Duke universiteit
Onderzoekers van Duke University hebben een methode bedacht om de luchtkwaliteit over een klein stukje land te schatten met alleen satellietbeelden en weersomstandigheden. Dergelijke informatie kan onderzoekers helpen verborgen hotspots van gevaarlijke vervuiling te identificeren, studies naar vervuiling op de menselijke gezondheid aanzienlijk verbeteren, of mogelijk de effecten van onvoorspelbare gebeurtenissen op de luchtkwaliteit blootleggen, zoals het uitbreken van een wereldwijde pandemie in de lucht.
De resultaten verschijnen online in het tijdschrift Atmosferische omgeving .
"We hebben een nieuwe generatie microsatellietbeelden gebruikt om de luchtvervuiling op grondniveau te schatten op de kleinste ruimtelijke schaal tot nu toe, " zei Mike Bergin, hoogleraar civiele techniek en milieutechniek aan Duke. "We hebben het kunnen doen door een totaal nieuwe aanpak te ontwikkelen die AI/machine learning gebruikt om gegevens van oppervlaktebeelden en bestaande grondstations te interpreteren."
De specifieke meting van de luchtkwaliteit waarin Bergin en zijn collega's geïnteresseerd zijn, is de hoeveelheid kleine deeltjes in de lucht die PM2.5 wordt genoemd. Dit zijn deeltjes met een diameter van minder dan 2,5 micrometer - ongeveer drie procent van de diameter van een mensenhaar - en waarvan is aangetoond dat ze een dramatisch effect hebben op de menselijke gezondheid vanwege hun vermogen om diep in de longen te reizen.
Bijvoorbeeld, PM2.5 werd wereldwijd gerangschikt als de vijfde sterfterisicofactor, verantwoordelijk voor ongeveer 4,2 miljoen doden en 103,1 miljoen levensjaren verloren of geleefd met een handicap, door de 2015 Global Burden of Disease-studie. En in een recente studie van de Harvard University T.H. Chan School of Public Health, onderzoekers ontdekten dat gebieden met hogere niveaus van PM2.5 ook geassocieerd zijn met hogere sterftecijfers als gevolg van COVID-19.
Huidige best practices op het gebied van teledetectie om de hoeveelheid PM2.5 op grondniveau te schatten, gebruiken satellieten om te meten hoeveel zonlicht door omgevingsdeeltjes over de gehele atmosferische kolom wordt teruggestrooid naar de ruimte. Deze methode, echter, kunnen last hebben van regionale onzekerheden zoals wolken en glanzende oppervlakken, atmosferische menging, en eigenschappen van de PM-deeltjes, en kan geen nauwkeurige schattingen maken op schalen kleiner dan ongeveer een vierkante kilometer. Terwijl meetstations voor bodemverontreiniging directe metingen kunnen leveren, ze lijden aan hun eigen vele nadelen en zijn slechts schaars verspreid over de hele wereld.
"Grondstations zijn duur om te bouwen en te onderhouden, dus zelfs grote steden hebben er waarschijnlijk niet meer dan een handvol, "zei Bergin. "Bovendien worden ze bijna altijd in gebieden buiten het verkeer en andere grote lokale bronnen geplaatst, dus hoewel ze een algemeen idee kunnen geven van de hoeveelheid PM2,5 in de lucht, ze komen niet in de buurt van het geven van een echte distributie voor de mensen die in verschillende gebieden in die stad wonen."
In hun zoektocht naar een betere methode, Bergin en zijn promovendus Tongshu Zheng wendden zich tot Planet, een Amerikaans bedrijf dat met microsatellieten elke dag foto's maakt van het hele aardoppervlak met een resolutie van drie meter per pixel. Het team kon de afgelopen drie jaar dagelijks een momentopname maken van Peking.
De belangrijkste doorbraak kwam toen David Carlson, een assistent-professor civiele en milieutechniek aan Duke en een expert in machine learning, ingestapt om te helpen.

Zes verschillende foto's genomen van hetzelfde gebied van Peking op verschillende dagen met verschillende niveaus van luchtvervuiling. Terwijl het blote menselijk oog duidelijk kan zien dat sommige dagen meer vervuild zijn dan andere, een nieuw machine learning-algoritme kan redelijk nauwkeurige schattingen maken van luchtvervuiling op grondniveau. Krediet:Tongshu Zheng, Duke universiteit
"Als ik naar conferenties over machine learning en kunstmatige intelligentie ga, Ik ben meestal de enige persoon van een afdeling milieutechniek, "zei Carlson. "Maar dit zijn de exacte soorten projecten die ik hier ben om te helpen ondersteunen, en waarom Duke zo veel belang hecht aan het inhuren van data-experts binnen de hele universiteit."
Met de hulp van Carlson, Bergin en Zheng pasten een convolutioneel neuraal netwerk met een willekeurig bosalgoritme toe op de beeldset, gecombineerd met meteorologische gegevens van het weerstation van Peking. Hoewel dat klinkt als een mondvol, het is niet zo moeilijk om je een weg te banen door de bomen.
Een willekeurig forest is een standaard machine learning-algoritme dat veel verschillende beslissingsbomen gebruikt om een voorspelling te doen. We hebben allemaal beslisbomen gezien, misschien als een internetmeme die een reeks vertakkende ja/nee-vragen gebruikt om te beslissen of je een burrito wilt eten of niet. Behalve in dit geval, het algoritme kijkt door beslissingsbomen op basis van metrische gegevens zoals wind, relatieve vochtigheid, temperatuur en meer, en de resulterende antwoorden gebruiken om tot een schatting voor PM2,5-concentraties te komen.
Echter, willekeurige forest-algoritmen gaan niet goed om met afbeeldingen. Dat is waar de convolutionele neurale netwerken binnenkomen. Deze algoritmen zoeken naar gemeenschappelijke kenmerken in afbeeldingen zoals lijnen en hobbels en beginnen ze samen te groeperen. Terwijl het algoritme "uitzoomt, " het blijft gelijkaardige groepen op één hoop gooien, het combineren van basisvormen tot gemeenschappelijke kenmerken zoals gebouwen en snelwegen. Uiteindelijk komt het algoritme met een samenvatting van de afbeelding als een lijst met de meest voorkomende functies, en deze worden samen met de weergegevens in het willekeurige bos gegooid.
"Afbeeldingen met hoge vervuiling zijn absoluut mistiger en vager dan normale afbeeldingen, maar het menselijk oog kan niet echt de exacte vervuilingsniveaus afleiden uit die details, "Zei Carlson. "Maar het algoritme kan deze verschillen in zowel de low-level als de high-level features oppikken - randen zijn vager en vormen zijn meer verduisterd - en ze precies omzetten in schattingen van de luchtkwaliteit."
"Het convolutionele neurale netwerk geeft ons niet zo'n goede voorspelling als we zouden willen met de afbeeldingen alleen, " voegde Zheng toe. "Maar als je die resultaten in een willekeurig bos met weergegevens plaatst, de resultaten zijn net zo goed als al het andere dat momenteel beschikbaar is, zo niet beter."
In de studie, de onderzoekers gebruikten 10, 400 afbeeldingen om hun model te trainen om lokale niveaus van PM2.5 te voorspellen met niets anders dan satellietbeelden en weersomstandigheden. Ze testten hun resulterende model op nog eens 2, 622 afbeeldingen om te zien hoe goed het PM2.5 kon voorspellen.
Dat laten ze zien, gemiddeld, hun model is nauwkeurig tot op 24 procent van de werkelijke PM2,5-niveaus gemeten op referentiestations, die zich aan de hoge kant van het spectrum bevindt voor dit soort modellen, terwijl het ook een veel hogere ruimtelijke resolutie heeft. Hoewel de meeste van de huidige standaardpraktijken niveaus tot 1 miljoen vierkante meter kunnen voorspellen, de nieuwe methode is nauwkeurig tot 40, 000 - ongeveer zo groot als acht naast elkaar geplaatste voetbalvelden.
Met dat niveau van specificiteit en nauwkeurigheid, Bergin gelooft dat hun methode een breed scala aan nieuwe toepassingen voor dergelijke modellen zal openen.
"We denken dat dit een enorme innovatie is in het ophalen van luchtkwaliteit via satelliet en de ruggengraat zal zijn van veel onderzoek dat nog moet komen, " zei Bergin. "We beginnen al vragen te krijgen om het te gebruiken om te kijken hoe de niveaus van PM2.5 zullen veranderen zodra de wereld begint te herstellen van de verspreiding van COVID-19."
 Licht werpen in het donker:radarsatellieten leiden de weg
Licht werpen in het donker:radarsatellieten leiden de weg- Experts waarschuwen dat Australië gevaar loopt door droogte, stijgende waterstanden
- Planten en samenleving verbinden:de verklaring van Shenzhen, een nieuwe roadmap voor plantenwetenschappen
- Inzichten in gedrag tijdens schoorsteenbrand Tops 2 kunnen evacuatieplanning verbeteren
- Een nieuwe kijk op koraalriffen
Hoofdlijnen
- Team ontwikkelt strategie voor gencircuitontwerp om synthetische biologie te bevorderen
- Reflecteert Saturnus licht?
- Chemische stoffen gebruikt in DNA-analyse
- Amerikaanse biologische klok-genetici winnen Nobelprijs voor Geneeskunde 2017
- Gen-experts gaan ongediertebestrijding aanpakken
- De positieve kant van een besmettelijk eiwit:stresssensoren bevorderen de overleving van gistcellen
- Hoe werkt ureum denatureiwitten?
- De natuur laat zien hoe bacteriën lignine afbreken en geeft beter inzicht om biobrandstoffen te maken
- Wanneer dupliceren chromosomen tijdens een levenscyclus van cellen?
- Decennia na de olieramp die Earth Day inspireerde, zijn we voorbereid op de volgende?

- Is de afname van de oppervlaktewindsnelheid in China geëindigd?

- Pleidooi voor terugtrekking in de strijd tegen klimaatverandering

- Oceaanplastic dat de kusten van Chili ooit verstikte, nu in hoeden van Patagonië

- Koude lucht stijgt op - wat dat betekent voor het klimaat op aarde

 5 grootste kernreactoren
5 grootste kernreactoren - Scheuren luiden het afkalven van een grote ijsberg van de Petermann-gletsjer in
- Onderzoekers creëren zelf-assemblerende nanodevices die op verzoek bewegen en van vorm veranderen
- Onderzoekers realiseren zeer efficiënte frequentieconversie op geïntegreerde fotonische chip
- Designer nanodevice kan behandelingsopties voor kankerpatiënten verbeteren
- Nauwkeurige temperatuurmetingen met onzichtbaar licht
- Grafeen onthult zijn magnetische persoonlijkheid
- Washington produceert recordoogst wijndruiven in 2016
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
