Wetenschap
Neurale netwerken maken het leren van foutcorrectiestrategieën voor kwantumcomputers mogelijk
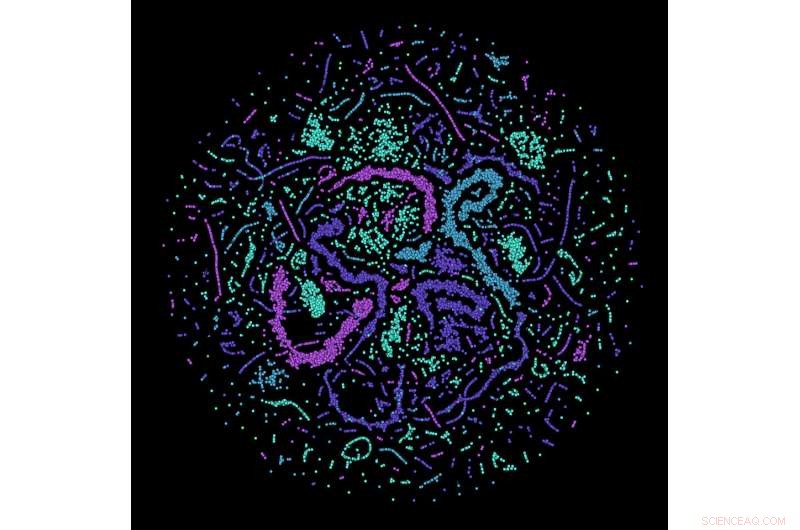
Kwantumfoutcorrectie leren:het beeld visualiseert de activiteit van kunstmatige neuronen in het neurale netwerk van de Erlangen-onderzoekers terwijl het zijn taak oplost. Krediet:Max Planck Instituut voor de Wetenschap van het Licht
Kwantumcomputers kunnen complexe taken oplossen die de mogelijkheden van conventionele computers te boven gaan. Echter, de kwantumtoestanden zijn extreem gevoelig voor constante interferentie van hun omgeving. Het plan is om dit tegen te gaan met actieve bescherming op basis van kwantumfoutcorrectie. Florian Marquardt, Directeur van het Max Planck Institute for the Science of Light, en zijn team hebben nu een kwantumfoutcorrectiesysteem gepresenteerd dat dankzij kunstmatige intelligentie kan leren.
in 2016, het computerprogramma AlphaGo won vier van de vijf games van Go tegen 's werelds beste menselijke speler. Aangezien een Go-spel meer combinaties van zetten heeft dan er naar schatting atomen in het universum zijn, dit vereiste meer dan alleen pure verwerkingskracht. Liever, AlphaGo gebruikte kunstmatige neurale netwerken, die visuele patronen kunnen herkennen en zelfs kunnen leren. In tegenstelling tot een mens, het programma was in staat om in korte tijd honderdduizenden spellen te oefenen, uiteindelijk de beste menselijke speler overtreffen. Nutsvoorzieningen, de onderzoekers uit Erlangen gebruiken dit soort neurale netwerken om foutcorrectieleren voor een kwantumcomputer te ontwikkelen.
Kunstmatige neurale netwerken zijn computerprogramma's die het gedrag van onderling verbonden zenuwcellen (neuronen) nabootsen - in het geval van het onderzoek in Erlangen, ongeveer tweeduizend kunstmatige neuronen zijn met elkaar verbonden. "We nemen de nieuwste ideeën uit de informatica en passen ze toe op fysieke systemen, " legt Florian Marquardt uit. "Door dit te doen, we profiteren van de snelle vooruitgang op het gebied van kunstmatige intelligentie."
Kunstmatige neurale netwerken zouden andere strategieën voor foutcorrectie kunnen overtreffen
Het eerste toepassingsgebied zijn kwantumcomputers, zoals blijkt uit het recente artikel, waaronder een belangrijke bijdrage van Thomas Fösel, een doctoraatsstudent aan het Max Planck Instituut in Erlangen. In de krant, het team laat zien dat kunstmatige neurale netwerken met een AlphaGo-geïnspireerde architectuur in staat zijn om zelf te leren hoe ze een taak moeten uitvoeren die essentieel zal zijn voor de werking van toekomstige kwantumcomputers:kwantumfoutcorrectie. Er is zelfs het vooruitzicht dat met voldoende opleiding, deze aanpak zal andere foutcorrectiestrategieën overtreffen.
Om te begrijpen wat het inhoudt, je moet kijken naar de manier waarop kwantumcomputers werken. De basis voor kwantuminformatie is de kwantumbit, of qubit. In tegenstelling tot conventionele digitale bits, een qubit kan niet alleen de twee toestanden nul en één aannemen, maar ook superposities van beide staten. In de processor van een kwantumcomputer, er zijn zelfs meerdere qubits gesuperponeerd als onderdeel van een gezamenlijke staat. Deze verstrengeling verklaart de enorme rekenkracht van kwantumcomputers als het gaat om het oplossen van bepaalde complexe taken waarbij conventionele computers gedoemd zijn te mislukken. Het nadeel is dat kwantuminformatie zeer gevoelig is voor ruis uit de omgeving. Deze en andere eigenaardigheden van de kwantumwereld betekenen dat kwantuminformatie regelmatig moet worden gerepareerd, dat wil zeggen, kwantumfoutcorrectie. Echter, de bewerkingen die daarvoor nodig zijn, zijn niet alleen complex, maar moeten ook de kwantuminformatie zelf intact laten.
Kwantumfoutcorrectie is als een spelletje Go met vreemde regels
"Je kunt je de elementen van een kwantumcomputer voorstellen als een Go-bord, " zegt Marquardt, om tot de kern van zijn project te komen. De qubits worden als stukken over het bord verdeeld. Echter, er zijn enkele belangrijke verschillen met een conventioneel Go-spel:alle stukken zijn al over het bord verdeeld, en elk van hen is wit aan de ene kant en zwart aan de andere. Eén kleur komt overeen met de toestand nul, de andere naar de ene, en een zet in een spelletje Quantum Go houdt in dat je stukken omdraait. Volgens de regels van de kwantumwereld, de stukken kunnen ook grijs gemengde kleuren aannemen, die de superpositie en verstrengeling van kwantumtoestanden vertegenwoordigen.
Als het gaat om het spelen van het spel, een speler - we zullen haar Alice noemen - maakt bewegingen die bedoeld zijn om een patroon te behouden dat een bepaalde kwantumtoestand vertegenwoordigt. Dit zijn de bewerkingen voor kwantumfoutcorrectie. Ondertussen, haar tegenstander doet er alles aan om het patroon te vernietigen. Dit vertegenwoordigt de constante ruis van de overvloed aan interferentie die echte qubits uit hun omgeving ervaren. In aanvulling, een spelletje quantum Go wordt extra moeilijk gemaakt door een eigenaardige quantumregel:Alice mag tijdens het spel niet naar het bord kijken. Elke glimp die de staat van de qubit-stukken aan haar onthult, vernietigt de gevoelige kwantumstaat die het spel momenteel bezet. De vraag is:hoe kan ze desondanks de juiste bewegingen maken?
Hulpqubits onthullen defecten in de kwantumcomputer
Bij kwantumcomputers dit probleem wordt opgelost door extra qubits te plaatsen tussen de qubits die de eigenlijke kwantuminformatie opslaan. Er kunnen af en toe metingen worden gedaan om de status van deze hulpqubits te controleren, waardoor de controller van de kwantumcomputer kan identificeren waar fouten liggen en correctiebewerkingen kan uitvoeren op de informatiedragende qubits in die gebieden. In ons spel Quantum Go, de hulpqubits zouden worden weergegeven door extra stukken verdeeld over de eigenlijke spelstukken. Alice mag af en toe kijken, maar alleen bij deze hulpstukken.
In het werk van de Erlangen-onderzoekers De rol van Alice wordt uitgevoerd door kunstmatige neurale netwerken. Het idee is dat, door middel van opleiding, de netwerken zullen zo goed worden in deze rol dat ze zelfs correctiestrategieën kunnen overtreffen die door intelligente menselijke geesten zijn bedacht. Echter, toen het team een voorbeeld bestudeerde met vijf gesimuleerde qubits, een getal dat voor conventionele computers nog steeds beheersbaar is, ze konden aantonen dat één kunstmatig neuraal netwerk alleen niet genoeg is. Omdat het netwerk slechts kleine hoeveelheden informatie kan verzamelen over de toestand van de kwantumbits, of liever het spel van quantum Go, het komt nooit verder dan het stadium van willekeurig vallen en opstaan. uiteindelijk, deze pogingen vernietigen de kwantumtoestand in plaats van deze te herstellen.
Het ene neuraal netwerk gebruikt zijn voorkennis om het andere te trainen
De oplossing komt in de vorm van een extra neuraal netwerk dat fungeert als een leraar voor het eerste netwerk. Met zijn voorkennis van de te besturen kwantumcomputer, dit lerarennetwerk is in staat om het andere netwerk - zijn leerling - te trainen en zo zijn pogingen naar succesvolle kwantumcorrectie te begeleiden. Eerst, echter, het lerarennetwerk zelf moet voldoende leren over de kwantumcomputer of het onderdeel ervan dat bestuurd moet worden.
In principe, kunstmatige neurale netwerken worden getraind met behulp van een beloningssysteem, net als hun natuurlijke modellen. De daadwerkelijke beloning wordt geleverd voor het succesvol herstellen van de oorspronkelijke kwantumtoestand door kwantumfoutcorrectie. "Echter, als alleen het bereiken van dit langetermijndoel een beloning opleverde, het zou in een te laat stadium komen in de talrijke correctiepogingen, " legt Marquardt uit. De onderzoekers uit Erlangen hebben daarom een beloningssysteem ontwikkeld dat, zelfs in de opleidingsfase, stimuleert het neurale netwerk van de leraar om een veelbelovende strategie aan te nemen. In het spel Quantum Go, dit beloningssysteem zou Alice een indicatie geven van de algemene staat van het spel op een bepaald moment zonder de details prijs te geven.
Het studentennetwerk kan zijn leraar overtreffen door zijn eigen acties
"Ons eerste doel was dat het lerarennetwerk zou leren om succesvolle kwantumfoutcorrectiebewerkingen uit te voeren zonder verdere menselijke hulp, ", zegt Marquardt. In tegenstelling tot het schoolstudentennetwerk, het lerarennetwerk kan dit niet alleen doen op basis van meetresultaten, maar ook op basis van de algehele kwantumstatus van de computer. Het door het docentennetwerk getrainde studentennetwerk zal dan in het begin even goed zijn, maar kan nog beter worden door zijn eigen acties.
Naast foutcorrectie in kwantumcomputers, Florian Marquardt ziet andere toepassingen voor kunstmatige intelligentie. Naar zijn mening, natuurkunde biedt veel systemen die kunnen profiteren van het gebruik van patroonherkenning door kunstmatige neurale netwerken.
 Hoe de Lattice-energie van een verbinding te vinden
Hoe de Lattice-energie van een verbinding te vinden - Wetenschappers ontwikkelen fagocytische protocellen die in staat zijn tot gerichte afgifte van enzymen
- Glycerol Vs. Minerale olie
- Elementen die meestal elektronen opnemen
- Een moleculair afvalverwerkingscomplex speelt een rol bij het inpakken van het genoom
- De manier waarop we onderzoek doen veranderen:pleiten voor duurzaamheidswetenschap
- Ploegen, mulchen of direct zaaien:modellering van bodemstructuurveranderingen als belangrijk fundamenteel onderzoek
- Onafhankelijk, particuliere bedrijven vervuilen minder dan overheidsbedrijven, studie toont
- Radar voegt een technologische draai toe aan het eeuwenoude telproces van cranberry's
- NASA staart majoor Hurricane Lane in de ogen
Hoofdlijnen
- Waarom zijn er geen zeeslangen in de Atlantische Oceaan?
- Hoe gigantische tropische fruitvleermuizen te redden:werk samen met lokale jagers die vleermuistanden als geld gebruiken
- Hoe een TAPPI-kaart te gebruiken
- Wat veroorzaakt de dubbele helix om te draaien in een DNA-afbeelding?
- Wetenschappers afluisteren onbekende spitssnuitdolfijnen af om te zien hoe diep ze duiken
- Genexpressie in Prokaryotes
- Colombia - een megadivers paradijs dat nog ontdekt moet worden
- Het zien van voedsel kan vissen naar het land hebben gelokt
- Welke soort weefsel geeft de meeste tijd in interfase?
- Voorbij 5G:draadloze communicatie kan een boost krijgen van ultrakorte collimerende metalens
- Caleidoscoopspiegelsymmetrie inspireert nieuw ontwerp voor optische gereedschappen, technologieën
- Ademhalingsdruppelbeweging, verdamping en verspreiding van pandemieën van het type COVID-19
- ORNL-team bouwt draagbare diagnostiek voor fusie-experimenten van kant-en-klare items

- Onzichtbaarheidsmantel dichter bij realiteit


 Studies wijzen op een slimmere manier om procedures te leren, problemen oplossen
Studies wijzen op een slimmere manier om procedures te leren, problemen oplossen- Sneeuwmonitoring op de toppen van de Sierra Nevada biedt de eerste datasets op middellange termijn
- Ruimtepuin voor het eerst overdag waargenomen
- Een prijskaartje aan het leven van een persoon hangen, zou Amerika veiliger en eerlijker kunnen maken
- Beeldvorming van nanodeeltjes:een resonerende verbetering
- Waarom schreeuwt metaal als het droogijs aanraakt?
- Een anti-verblinding, ontspiegeld display voor mobiele apparaten?
- Sleepcamera's zoeken
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
