Wetenschap
Waarom deep-learning-methoden met vertrouwen afbeeldingen herkennen die onzin zijn
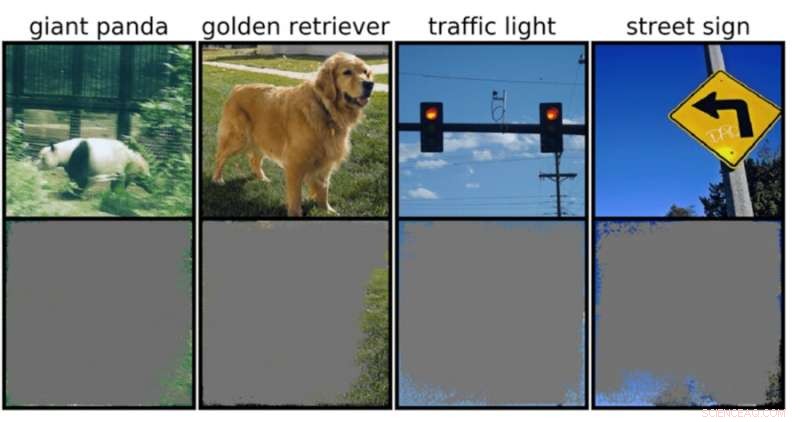
Een classificator voor diepe afbeeldingen kan met meer dan 90 procent zekerheid afbeeldingsklassen bepalen met behulp van voornamelijk afbeeldingsranden, in plaats van een object zelf. Krediet:Rachel Gordon
Ondanks alles wat neurale netwerken kunnen bereiken, begrijpen we nog steeds niet echt hoe ze werken. Natuurlijk kunnen we ze programmeren om te leren, maar het besluitvormingsproces van een machine begrijpen blijft net als een mooie puzzel met een duizelingwekkend, complex patroon waarin nog veel integrale stukjes moeten worden geplaatst.
Als een model bijvoorbeeld een afbeelding van de puzzel probeerde te classificeren, zou het bekende, maar vervelende aanvallen van tegenstanders kunnen tegenkomen, of zelfs meer alledaagse gegevens- of verwerkingsproblemen. Maar een nieuw, subtieler type storing dat onlangs door MIT-wetenschappers is geïdentificeerd, is een andere reden tot bezorgdheid:"overinterpretatie", waarbij algoritmen zelfverzekerde voorspellingen doen op basis van details die voor mensen niet logisch zijn, zoals willekeurige patronen of afbeeldingsgrenzen.
Dit kan met name zorgwekkend zijn voor omgevingen met een hoge inzet, zoals beslissingen in een fractie van een seconde voor zelfrijdende auto's en medische diagnostiek voor ziekten die meer onmiddellijke aandacht nodig hebben. Vooral autonome voertuigen zijn sterk afhankelijk van systemen die de omgeving nauwkeurig kunnen begrijpen en vervolgens snelle, veilige beslissingen kunnen nemen. Het netwerk gebruikte specifieke achtergronden, randen of bepaalde patronen van de lucht om verkeerslichten en straatnaamborden te classificeren, ongeacht wat er nog meer op de afbeelding stond.
Het team ontdekte dat neurale netwerken die waren getraind op populaire datasets zoals CIFAR-10 en ImageNet te lijden hadden van overinterpretatie. Modellen die op CIFAR-10 waren getraind, deden bijvoorbeeld betrouwbare voorspellingen, zelfs wanneer 95 procent van de invoerbeelden ontbrak, en de rest is onzinnig voor mensen.
"Overinterpretatie is een datasetprobleem dat wordt veroorzaakt door deze onzinnige signalen in datasets. Deze zeer betrouwbare afbeeldingen zijn niet alleen onherkenbaar, ze bevatten minder dan 10 procent van de originele afbeelding in onbelangrijke gebieden, zoals grenzen. We ontdekten dat deze afbeeldingen zinloos voor mensen, maar modellen kunnen ze nog steeds met veel vertrouwen classificeren", zegt Brandon Carter, MIT Computer Science and Artificial Intelligence Laboratory Ph.D. student en hoofdauteur van een paper over het onderzoek.
Deep-image classifiers worden veel gebruikt. Naast medische diagnose en het stimuleren van autonome voertuigtechnologie, zijn er use-cases in beveiliging, gaming en zelfs een app die je vertelt of iets een hotdog is of niet, omdat we soms geruststelling nodig hebben. De technologie in discussie werkt door individuele pixels van tonnen vooraf gelabelde afbeeldingen te verwerken zodat het netwerk kan 'leren'.
Beeldclassificatie is moeilijk, omdat modellen voor machinaal leren deze onzinnige subtiele signalen kunnen vasthouden. Wanneer beeldclassificatoren vervolgens worden getraind op datasets zoals ImageNet, kunnen ze schijnbaar betrouwbare voorspellingen doen op basis van die signalen.
Hoewel deze onzinnige signalen kunnen leiden tot modelfragiliteit in de echte wereld, zijn de signalen in feite geldig in de datasets, wat betekent dat overinterpretatie niet kan worden gediagnosticeerd met behulp van typische evaluatiemethoden die op die nauwkeurigheid zijn gebaseerd.
Om de reden voor de voorspelling van het model op een bepaalde invoer te vinden, beginnen de methoden in de huidige studie met het volledige beeld en vragen herhaaldelijk, wat kan ik uit dit beeld verwijderen? In wezen blijft het de afbeelding bedekken, totdat je het kleinste stukje overhoudt dat nog steeds een zelfverzekerde beslissing neemt.
Daartoe zouden deze methoden ook als een soort validatiecriteria kunnen worden gebruikt. Als u bijvoorbeeld een autonoom rijdende auto heeft die een getrainde machine-learningmethode gebruikt voor het herkennen van stopborden, kunt u die methode testen door de kleinste invoersubset te identificeren die een stopteken vormt. Als dat bestaat uit een boomtak, een bepaald tijdstip van de dag of iets dat geen stopbord is, zou je je zorgen kunnen maken dat de auto zou kunnen stoppen op een plaats waar het niet hoort.
Hoewel het lijkt alsof het model hier de waarschijnlijke boosdoener is, is de kans groter dat de datasets de schuld krijgen. "Het is de vraag hoe we de datasets zodanig kunnen aanpassen dat modellen kunnen worden getraind om beter na te bootsen hoe een mens zou denken over het classificeren van afbeeldingen en daarom hopelijk beter generaliseren in deze realistische scenario's, zoals autonoom rijden en medische diagnose, zodat de modellen dit onzinnige gedrag niet vertonen", zegt Carter.
Dit kan betekenen dat er datasets moeten worden gemaakt in meer gecontroleerde omgevingen. Momenteel zijn het alleen foto's die worden geëxtraheerd uit openbare domeinen die vervolgens worden geclassificeerd. Maar als je bijvoorbeeld aan objectidentificatie wilt doen, kan het nodig zijn om modellen te trainen met objecten met een weinig informatieve achtergrond.
 Synthetische bedrukte polymeren herkend door DNA
Synthetische bedrukte polymeren herkend door DNA- Ontgrendelen van efficiënte licht-energieconversie met stabiele coördinatie-nanobladen
- Zeer selectieve terugwinning van lanthaniden via gelaagd vanadaat met zuur- en stralingsbestendigheid
- Nieuwe ultrasnelle methode om antibioticaresistentie te bepalen
- Met behulp van computationele chemie om goedkopere infrarood plastic lenzen te produceren
- Om de toekomst van orkanen te begrijpen, kijk naar het verleden
- Onderzoekers voorspellen dat de wereldwijde energiebehoefte tegen 2050 met 25% zal toenemen
- TransCanada dient Amerikaanse aanvraag in om Keystone-pijplijn te bouwen
- Zeewieradditief vermindert methaan in vee, maar roept vragen op
- Vervuiling door giftige mijnen gestopt in de buurt van het schilderachtige meer van Washington
Hoofdlijnen
- Wat voert glycolyse uit?
- Komt mitose voor in Prokaryoten, Eukaryoten of Beide?
- Diverse landschappen in het hart van bijenbescherming
- Onderzoek suggereert dat gevaarlijke gewassenschimmel giftige chemicaliën produceert om insecten af te weren
- Waarom sommige mensen muggenmagneten zijn
- Verschil tussen homozygoot en heterozygoot
- Olifantenstroperij in Afrika neemt af, maar ivoorvangsten nemen toe:studie
- Ongevaarlijk of dodelijk? Onderzoek naar de evolutie van E. coli
- Wat voor invloed zal klimaatverandering hebben op waar hooggelegen alpenvogels leven?
- Wat Facebook ons niet vertelt over zijn strijd tegen online misbruik

- Uitgelekte benchmarks tonen Intel Tiger Lakes-snelheid

- Het gepersonaliseerde algoritme voor de afspeellijst voor DJ-muziek stemt nummers af op de veranderende stemming van luisteraars

- Senior Republikein roept op tot heropening van Google-onderzoek

- Haptische onderzoekers ontdekken dat de biomechanica van de huid nuttige tactiele berekeningen kan uitvoeren


 Surrey NanoSystems heeft super zwart materiaal
Surrey NanoSystems heeft super zwart materiaal- Onderzoek naar met stikstof gedoteerde polycyclische aromatische koolwaterstoffen voor hoogwaardige OLED's
- Brussels Airlines schort alle vluchten een maand op
- Waarom is de watercyclus belangrijk voor mensen en planten?
- De eigenschappen van een nieuwe vorm van diamant afleiden
- Goedkoop materiaal verhoogt de batterijcapaciteit
- Loopsimulatiegames signaleren een nieuw literair genre
- Medicijndragers gemaakt van menselijke cellen kunnen longinfecties genezen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
