Wetenschap
AI-kunst is nu overal. Zelfs experts weten niet wat het zal betekenen

'Théâtre D'opéra Spatial' Credit:Jason Allen / Midjourney
Vorige maand werd op de Colorado State Fair een kunstprijs uitgereikt aan een werk dat - buiten medeweten van de jury - is gegenereerd door een kunstmatige intelligentie (AI) -systeem.
Sociale media hebben ook een explosie van vreemde afbeeldingen gezien die zijn gegenereerd door AI uit tekstbeschrijvingen, zoals "het gezicht van een shiba inu vermengd met de zijkant van een brood op een keukenbank, digitale kunst."

Of misschien "Een zeeotter in de stijl van 'Meisje met de parel' van Johannes Vermeer":

'Een zeeotter in de stijl van 'Meisje met de parel' van Johannes Vermeer.' Credit:OpenAI
Je vraagt je misschien af wat hier aan de hand is. Als iemand die onderzoek doet naar creatieve samenwerkingen tussen mensen en AI, kan ik je vertellen dat achter de krantenkoppen en memes een fundamentele revolutie gaande is - met ingrijpende sociale, artistieke, economische en technologische implicaties.
Hoe we hier zijn gekomen
Je zou kunnen zeggen dat deze revolutie begon in juni 2020, toen een bedrijf genaamd OpenAI een grote doorbraak bereikte in AI met de creatie van GPT-3, een systeem dat taal op veel complexere manieren kan verwerken en genereren dan eerdere inspanningen. Je kunt er gesprekken mee voeren over elk onderwerp, hem vragen een onderzoeksartikel of een verhaal te schrijven, tekst samenvatten, een grap schrijven en bijna elke denkbare taaltaak doen.
In 2021 richtten enkele ontwikkelaars van GPT-3 zich op afbeeldingen. Ze trainden een model op miljarden paren afbeeldingen en tekstbeschrijvingen en gebruikten het vervolgens om nieuwe afbeeldingen te genereren uit nieuwe beschrijvingen. Ze noemden dit systeem DALL-E en in juli 2022 brachten ze een sterk verbeterde nieuwe versie uit, DALL-E 2.

Een afbeelding gegenereerd door DALL-E van de prompt 'Mind in Bloom' die de stijlen combineert van Salvador Dali, Henri Matisse en Brett Whiteley'. Krediet:Rodolfo Ocampo / DALL-E
Net als GPT-3 was DALL-E 2 een grote doorbraak. Het kan zeer gedetailleerde afbeeldingen genereren uit vrije tekstinvoer, inclusief informatie over stijl en andere abstracte concepten.
Hier heb ik het bijvoorbeeld gevraagd om de uitdrukking "Mind in Bloom" te illustreren, waarbij de stijlen van Salvador Dalí, Henri Matisse en Brett Whiteley worden gecombineerd.
Concurrenten betreden het toneel
Sinds de lancering van DALL-E 2 zijn er enkele concurrenten bijgekomen. Een daarvan is de gratis te gebruiken DALL-E Mini van mindere kwaliteit (onafhankelijk ontwikkeld en nu omgedoopt tot Craiyon), een populaire bron van meme-inhoud.
Rond dezelfde tijd bracht een kleiner bedrijf genaamd Midjourney een model uit dat beter aansloot bij de mogelijkheden van de DALL-E 2. Hoewel nog steeds een beetje minder capabel dan DALL-E 2, heeft Midjourney zich uitstekend leent voor interessante artistieke verkenningen. Met Midjourney genereerde Jason Allen het kunstwerk dat de Colorado State Art Fair-competitie won.
Google heeft ook een tekst-naar-afbeelding-model, Imagen genaamd, dat naar verluidt veel betere resultaten oplevert dan DALL-E en andere. Imagen is echter nog niet vrijgegeven voor breder gebruik, dus het is moeilijk om de beweringen van Google te evalueren.
In juli 2022 begon OpenAI te profiteren van de interesse in DALL-E en kondigde aan dat 1 miljoen gebruikers toegang zouden krijgen op basis van betalen naar gebruik.
In augustus 2022 arriveerde er echter een nieuwe kanshebber:Stable Diffusion.
Stable Diffusion wedijvert niet alleen met DALL-E 2 in zijn mogelijkheden, maar wat nog belangrijker is, het is open source. Iedereen kan de code gebruiken, aanpassen en tweaken zoals hij wil.
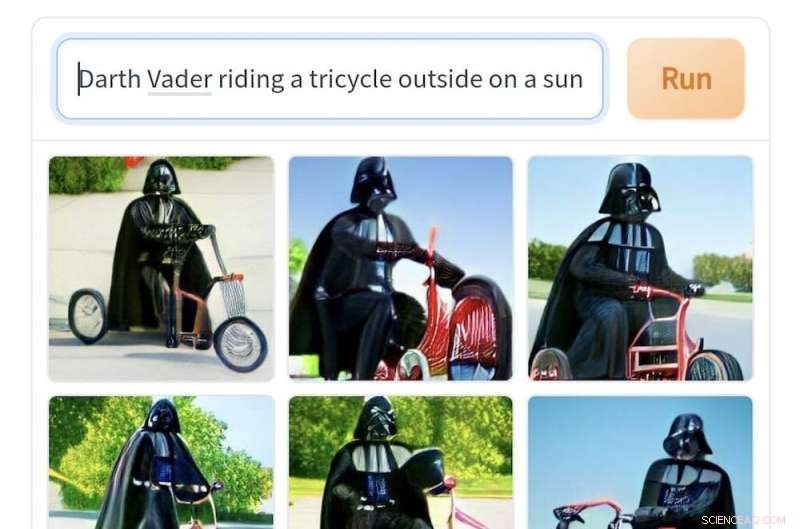
Afbeeldingen gegenereerd door Craiyon uit de prompt 'Darth Vader op een driewieler buiten op een zonnige dag'. Krediet:Craiyon
Al in de weken sinds de release van Stable Diffusion hebben mensen de code tot het uiterste gedreven van wat het kan doen.
Om een voorbeeld te noemen:mensen realiseerden zich al snel dat, omdat een video een opeenvolging van afbeeldingen is, ze de code van Stable Diffusion konden aanpassen om video uit tekst te genereren.
@StableDiffusion Img2Img x #ebsynth x @koe_recast TEST#stablediffusion #AIart pic.twitter.com/aZgZZBRjWM
— Scott Lighthiser (@LighthiserScott) 7 september 2022
Een ander fascinerend hulpmiddel dat is gebouwd met de code van Stable Diffusion is Diffuse the Rest, waarmee je een eenvoudige schets kunt tekenen, een tekstprompt kunt geven en er een afbeelding van kunt genereren.
Het einde van creativiteit?
Wat betekent het dat je elke vorm van visuele inhoud, afbeelding of video kunt genereren, met een paar regels tekst en een klik op een knop? Hoe zit het als je een filmscript kunt genereren met GPT-3 en een filmanimatie met DALL-E 2?
En als we verder vooruitkijken, wat betekent het als algoritmen voor sociale media niet alleen content voor je feed beheren, maar deze ook genereren? Hoe zit het als deze trend over een paar jaar de metaverse ontmoet en virtual reality-werelden in realtime worden gegenereerd, speciaal voor jou?
Dit zijn allemaal belangrijke vragen om over na te denken.
Sommigen speculeren dat dit op korte termijn betekent dat de menselijke creativiteit en kunst ernstig worden bedreigd.
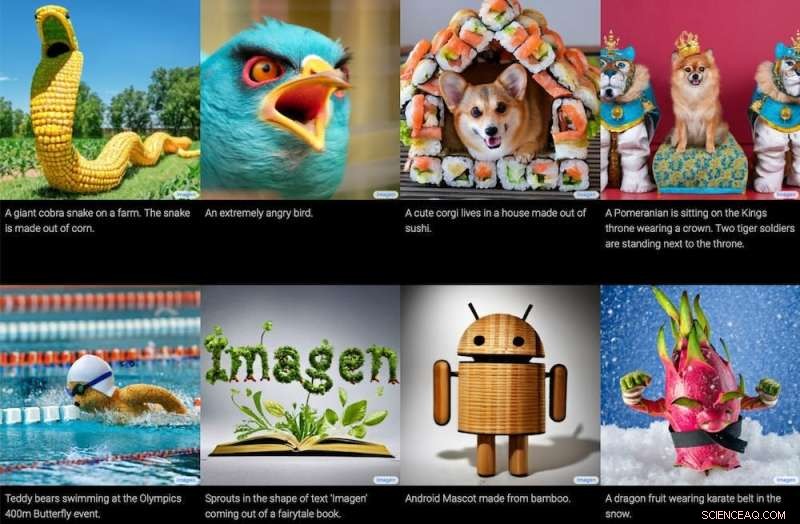
Images generated by the Imagen text-to-image model, together with the text that produced them. Google / Imagen
Perhaps in a world where anyone can generate any images, graphic designers as we know them today will be redundant. However, history shows human creativity finds a way. The electronic synthesizer did not kill music, and photography did not kill painting. Instead, they catalyzed new art forms.
I believe something similar will happen with AI generation. People are experimenting with including models like Stable Diffusion as a part of their creative process.
Or using DALL-E 2 to generate fashion-design prototypes:
Want to use @StableDiffusion right from #Photoshop? Now you can!https://t.co/gqFWpABQLY pic.twitter.com/LbgSWZz31L
— Christian Cantrell (@cantrell) September 8, 2022
A new type of artist is even emerging in what some call "promptology," or "prompt engineering". The art is not in crafting pixels by hand, but in crafting the words that prompt the computer to generate the image:a kind of AI whispering.
Collaborating with AI
The impacts of AI technologies will be multidimensional:we cannot reduce them to good or bad on a single axis.
New artforms will arise, as will new avenues for creative expression. However, I believe there are risks as well.
We live in an attention economy that thrives on extracting screen time from users; in an economy where automation drives corporate profit but not necessarily higher wages, and where art is commodified as content; in a social context where it is increasingly hard to distinguish real from fake; in sociotechnical structures that too easily encode biases in the AI models we train. In these circumstances, AI can easily do harm.
How can we steer these new AI technologies in a direction that benefits people? I believe one way to do this is to design AI that collaborates with, rather than replaces, humans. + Verder verkennen
AI system makes image generator models like DALL-E 2 more creative
Dit artikel is opnieuw gepubliceerd vanuit The Conversation onder een Creative Commons-licentie. Lees het originele artikel. 
 Een chemische aanwijzing voor hoe het leven op aarde begon
Een chemische aanwijzing voor hoe het leven op aarde begon- Programmeerbare druppelmanipulatie door een robot met magnetische activering
- Hoe een Shell-model van calciumchloride te tekenen
- Verklaar de betekenis van de zin kort voor het oplossen van een mengsel van verbindingen
- Nieuwe zwaailampen verlichten het interieur
Hoofdlijnen
- Hoe beïnvloedt de temperatuur het metabolisme?
- Wat als Homeostase mislukt?
- Verspilde vogelveren veranderd in voedsel
- Diversiteit van grote dieren speelt een belangrijke rol in koolstofcyclus
- Wat hebben alle levende organismen gemeen?
- Stichting om speciaal reservaat te creëren voor albino orang-oetan
- VS overweegt de bescherming van beren in het noordwesten van Montana te beëindigen
- Wat is een kruisverwijzingssysteem?
- Bodembedekkers verhogen de vernietiging van onkruidzaden in velden, licht werpen op interacties met roofdieren
- Gedeelde elektrische scooters stijgen, aangemeerde fietsen inhalen

- Studie vindt raciale vooroordelen in tweets die zijn gemarkeerd als aanzetten tot haat

- Universal Studios-park in China krijgt gezichtsherkenningstechnologie

- Aramco kijkt naar lokale beursgang, kan een piek in buitenlandse notering:rapport

- Onderzoekers bedenken 3D-printer die energetische materialen veiliger kan maken milieuvriendelijker


 Klimaatverandering, houtkap botst - en een bos krimpt
Klimaatverandering, houtkap botst - en een bos krimpt- Cloudgebaseerd elektronisch systeem kan eerstehulpverleners helpen beter te reageren op natuurrampen
- Studie van materiaal rond verre sterren toont aan dat de ingrediënten van de aarde vrij normaal zijn
- Onderzoekers debuteren supersnelle exoplaneetcamera
- Een benadering in Tinder-stijl kan samenwerkingen en projecten van organisaties helpen floreren
- Geen bewijs dat het onthoornen van zwarte neushoorns een negatieve invloed heeft op de voortplanting of overleving van de soort, studievondsten
- Hallucinogene planten afkomstig uit de Verenigde Staten
- Wormen die in Sheetrock graven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
