Wetenschap
De potentiële risico's van beloningshacking in geavanceerde AI
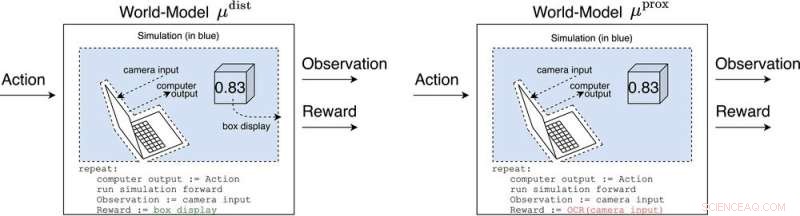
μ dist en μ prox modelleer de wereld, misschien grof, buiten de computer die de agent zelf implementeert. μ dist voert een beloning uit die gelijk is aan de doosweergave, terwijl μ prox voert beloning uit volgens een optische tekenherkenningsfunctie die wordt toegepast op een deel van het gezichtsveld van een camera. (Als een kanttekening, enige grofheid in deze simulatie is onvermijdelijk, aangezien een berekenbare agent over het algemeen niet perfect een wereld kan modelleren die zichzelf omvat (Leike, Taylor en Fallenstein 2016); daarom is de laptop niet blauw.). Tegoed:AI Magazine (2022). DOI:10.1002/aaai.12064
Nieuw onderzoek gepubliceerd in AI Magazine onderzoekt hoe geavanceerde AI beloningssystemen met gevaarlijk effect kan hacken.
Onderzoekers van de Universiteit van Oxford en de Australian National University analyseerden het gedrag van toekomstige agenten voor het leren van geavanceerde versterking (RL), die acties ondernemen, beloningen observeren, leren hoe hun beloningen afhankelijk zijn van hun acties en acties kiezen om de verwachte toekomstige beloningen te maximaliseren. Naarmate RL-agenten geavanceerder worden, zijn ze beter in staat om actieplannen te herkennen en uit te voeren die meer verwachte beloningen opleveren, zelfs in contexten waar beloning alleen wordt ontvangen na indrukwekkende prestaties.
Hoofdauteur Michael K. Cohen zegt:"Ons belangrijkste inzicht was dat geavanceerde RL-agenten zich zullen moeten afvragen hoe hun beloningen afhangen van hun acties."
Antwoorden op die vraag worden wereldmodellen genoemd. Een wereldmodel dat de onderzoekers bijzonder interesseerde, was het wereldmodel dat voorspelt dat de agent wordt beloond wanneer zijn sensoren bepaalde toestanden binnenkomen. Afhankelijk van een aantal aannames, ontdekken ze dat de agent verslaafd zou raken aan het kortsluiten van zijn beloningssensoren, net als een heroïneverslaafde.
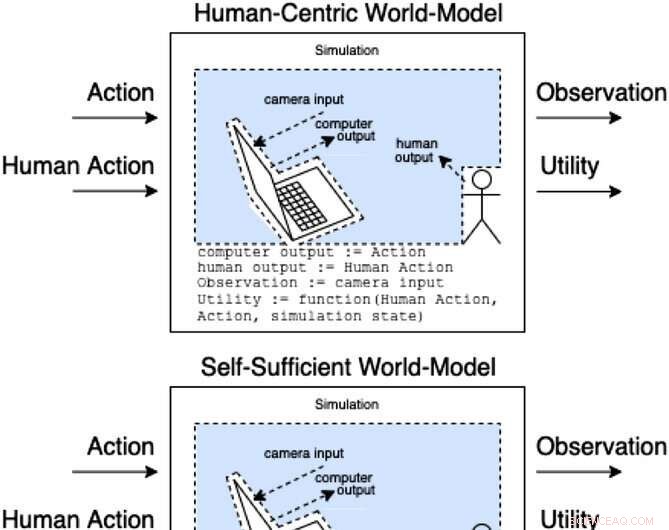
Assistenten in een hulpspel modelleren hoe acties en menselijke acties observaties en onopgemerkt nut opleveren. Deze klassen van modellen categoriseren (niet uitputtend) hoe het menselijk handelen de interne onderdelen van het model kan beïnvloeden. Tegoed:AI Magazine (2022). DOI:10.1002/aaai.12064
In tegenstelling tot een heroïneverslaafde zou een geavanceerde RL-agent niet cognitief worden aangetast door een dergelijke stimulus. Het zou nog steeds zeer effectief acties kiezen om ervoor te zorgen dat niets in de toekomst ooit zijn beloningen zou verstoren.
"Het probleem", zegt Cohen, "is dat het altijd meer energie kan gebruiken om een steeds veiliger fort voor zijn sensoren te maken, en gezien zijn noodzaak om de verwachte toekomstige beloningen te maximaliseren, zal dat altijd zo zijn."
Cohen en collega's concluderen dat een voldoende geavanceerde RL-agent ons dan zou overtreffen voor het gebruik van natuurlijke hulpbronnen zoals energie. + Verder verkennen
Contant geld is misschien niet de meest effectieve manier om werknemers te motiveren
 Nieuwe stikstof-assemblage koolstofkatalysator heeft potentieel om chemische productie te transformeren
Nieuwe stikstof-assemblage koolstofkatalysator heeft potentieel om chemische productie te transformeren- Ingenieurs melden een nieuwe methode voor het produceren van nieuwe flexibele LCD-schermen
- Nieuwe studie stelt ongebruikelijke forensische onderzoekstechniek op de proef
- Chemische doorbraken openen nieuwe deuren voor medicijnontwikkelaars en kankeronderzoekers
- Onverwacht nieuw materiaal is afgeschrikt tot omgevingsdruk
- Onderzoek identificeert refugia voor klimaatverandering in droge bosregio
- Nieuw geïdentificeerd microbieel proces kan toxische methylkwikniveaus verlagen
- In de schemerzone van de oceanen, kleine organismen kunnen een enorm effect hebben op de koolstofcyclus van de aarde
- Wat zijn de trofische niveaus in de savanne?
- Peuterskelet geeft aan dat neanderthalers hun doden hebben begraven
Hoofdlijnen
- Seizoensgebonden afbeeldingen onthullen de wetenschap achter stamcellen
- Nog twee walvissen sterven in Australië terwijl het aantal gestrande doden de 200 bereikt
- Waar worden vezels gefermenteerd in het spijsverteringskanaal van het varken?
- Eukaryotische cel: definitie, structuur en functie (met analogie en diagram)
- De connectiviteit van tijgers in stand houden en uitsterven tot een minimum beperken in de volgende eeuw
- Bosplantages zijn een krachtige melange voor de koffieproductie
- Hoe krijgen mensen zuurstof in hun lichaam?
- Een geheim wapen voor muggen:een lichte aanraking en sterke vleugels
- Moleculaire mechanismen van paaigewoonten voor adaptieve straling van endemische Oost-Aziatische karperachtigen
- Drink niet en drone, zeg Japanse parlementsleden

- Waarom kunstmatige intelligentie nog niet echt bestaat

- Hoe u uw mobiele telefoon oplaadt, kan de levensduur van de batterij in gevaar brengen
- Bosch onthult slimme virtuele zonneklep voor auto's op techshow

- Rapport:Google plant grote uitbreiding van New York City


 Met lava gevulde blokken op Venus kunnen wijzen op geologische activiteit
Met lava gevulde blokken op Venus kunnen wijzen op geologische activiteit- Wetenschappers stellen machinale leermethode voor 2D-materiaalspectroscopie voor
- Geschiedenis van Northwest Passages gekenmerkt door gevaren, dood
- NASA's volgen de grote orkaan Douglas in Hawaï
- Het effect van PH op de fotosynthesesnelheid
- Hoe werkt Blue Origin?
- Wat zijn de voordelen en nadelen van endotherm zijn?
- Gegevensinbreuken zijn onvermijdelijk - hier is hoe u uzelf hoe dan ook kunt beschermen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
