Wetenschap
Imitatie en versterkend leren gebruiken om robottaken met een lange horizon aan te pakken

Krediet:Gupta et al.
Reinforcement learning (RL) is een veelgebruikte machine learning-techniek waarbij AI-agenten of robots worden getraind met behulp van een systeem van beloning en straf. Tot dusver, onderzoekers op het gebied van robotica hebben RL-technieken voornamelijk toegepast in taken die in relatief korte tijd worden voltooid, zoals vooruit gaan of voorwerpen vastpakken.
Een team van onderzoekers van Google en Berkeley AI Research heeft onlangs een nieuwe aanpak ontwikkeld die RL combineert met leren door imitatie, een proces dat relay-beleidsleren wordt genoemd. Deze aanpak, geïntroduceerd in een paper dat vooraf is gepubliceerd op arXiv en gepresenteerd op de Conference on Robot Learning (CoRL) 2019 in Osaka, kan worden gebruikt om kunstmatige agenten te trainen om taken in meerdere fasen en met een lange horizon aan te pakken, zoals objectmanipulatietaken die zich over langere perioden uitstrekken.
"Ons onderzoek is ontstaan uit vele, meestal niet succesvol, experimenten met zeer lange taken met behulp van wapeningsleren (RL), "Abhishek Gupta, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Vandaag, RL in robotica wordt meestal toegepast in taken die in korte tijd kunnen worden uitgevoerd, zoals grijpen, voorwerpen duwen, vooruit lopen, enz. Hoewel deze toepassingen veel waarde hebben, ons doel was om versterkend leren toe te passen op taken die meerdere subdoelen vereisen en werken op veel langere tijdschalen, zoals het dekken van een tafel of het schoonmaken van een keuken."
Voordat ze begonnen met het ontwikkelen van hun aanpak, Gupta en zijn collega's hebben eerdere literatuur doorgenomen om te proberen vast te stellen waarom langere taken bijzonder moeilijk aan te pakken zijn met de huidige RL-technieken. In hun krant ze suggereren dat hier in het algemeen twee hoofdredenen voor zijn.
Eerst, het is moeilijk voor een robot om zelf optimale oplossingen te vinden voor het oplossen van lange en complexe taken. Tweede, het is moeilijk voor de agent om met succes een lange taak aan te pakken waarvoor alleen feedback wordt gegeven aan het einde van een lange reeks. Relay-beleid leren, de nieuwe benadering van leren die ze presenteerden, is ontworpen om beide uitdagingen direct aan te gaan.
Krediet:Gupta et al.
"Om de uitdaging aan te gaan om robots lange-horizontaken alleen te laten oplossen, we besloten het probleem te vereenvoudigen en door mensen geleverde demonstraties te gebruiken, "Zei Gupta. "Het oplossen van lange taken is moeilijk omdat het buitengewoon moeilijk is om een robot een interessant gedrag te laten ontdekken - door mensen geleverde demonstraties kunnen worden gebruikt als richtlijn voor interessante dingen om te doen in een omgeving."
De door Gupta en zijn collega's voorgestelde benadering voor robotleren bestaat uit twee verschillende fasen, een waarin een agent leert door mensen te imiteren en de andere op basis van RL. In de imitatieleerfase, een robot krijgt menselijke demonstraties van hoe een taak moet worden voltooid en produceert op doelen gebaseerd hiërarchisch beleid.
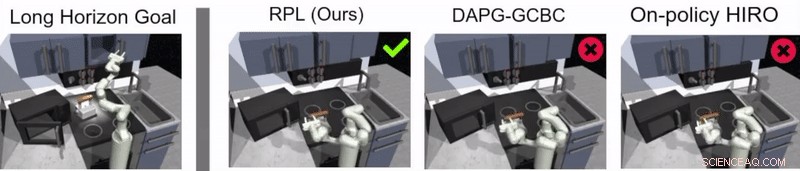
In hun studie hebben de onderzoekers gebruikten hun aanpak om een kunstmatige agent genaamd Franka te trainen in multi-stage en long-horizon manipulatietaken in een gesimuleerde keukenomgeving, die werd gemodelleerd met behulp van het fysica-simulatorplatform MuJoCo. Deze omgeving bestond uit een keuken met een te openen magnetron, vier ovenbranders, een ovenlichtschakelaar, een ketel, twee scharnierende kasten en een schuifdeur.

Krediet:Gupta et al.
"Belangrijk, leren van demonstraties alleen is niet genoeg om de uitdagende taken in onze gesimuleerde keukenomgeving op te lossen, "Karol Hausman, een andere onderzoeker die bij het onderzoek betrokken was, vertelde TechXplore. "Om deze eerste oplossing te verbeteren, we laten de robots de taken zelf oefenen om hun gedrag verder te verfijnen."
Eigenlijk, met behulp van de door de onderzoekers voorgestelde leermethode voor relaisbeleid, een agent leert in eerste instantie door menselijke demonstraties te verwerken over hoe een bepaalde taak moet worden voltooid en gaat vervolgens zelfstandig verder via RL. Om het proces van het leren van langetermijnbeleidslijnen gemakkelijker te maken, het team gebruikte een nieuw data-relabeling-algoritme waarmee een agent doelgericht hiërarchisch beleid kan leren.
"Om de uitdaging van schaarse feedback aan te gaan, we gebruiken een hiërarchische structuur voor ons controlebeleid:het beleid op hoog niveau stelt doelen voor die het beleid op laag niveau probeert te bereiken, bijvoorbeeld, sluit een kast, zet de brander uit, enzovoort., " legde Hausman uit. "Op deze manier, de taak kan gemakkelijk worden ontleed in kleinere subproblemen die kunnen worden opgelost met versterkingsleren, bootstrap van door mensen geleverde demonstraties."

Krediet:Gupta et al.
Gupta, Hausman en hun collega's evalueerden de effectiviteit van het leren van relaisbeleid voor het trainen van robots in lange-horizontaken binnen de gesimuleerde keukenomgeving die ze creëerden, het behalen van zeer veelbelovende resultaten. Ze ontdekten dat met de juiste beleidsstructuur en demonstratiegegevens, Dankzij hun aanpak konden robots veel langere horizontaken aan dan ze aanvankelijk voor mogelijk hadden gehouden.
"We hopen dat onze bevindingen nieuwe wegen kunnen openen voor het combineren van imitatie- en versterkingsleeronderzoek en ons een mogelijke richting geven waarmee robots lang kunnen presteren, complexe taken, ' zei Hausman.
In de toekomst, de door Gupta geïntroduceerde leerbenadering van het estafettebeleid, Hausman en hun collega's zouden kunnen worden gebruikt om robots te trainen voor een breder scala aan lange-horizontaken. De onderzoekers hebben hun techniek tot nu toe alleen getest in een gesimuleerde omgeving; dus, het zou interessant zijn om het in de praktijk te evalueren en te zien of het even veelbelovende resultaten oplevert.
"Als volgende stap we willen kijken naar het probleem van generalisatie buiten de demonstratiegegevens, " zei Hausman. "Uiteindelijk, we willen ook de data-efficiëntie van onze methode verder verbeteren, ga over op pixelobservaties en maak real-world leren mogelijk op een fysieke robot."
© 2019 Wetenschap X Netwerk
 Bepaling van de kristalstructuur van een DNA-gestabiliseerd zilveren nanocluster
Bepaling van de kristalstructuur van een DNA-gestabiliseerd zilveren nanocluster- Analytische methoden helpen bij het ontwikkelen van tegengiffen voor cyanide, mosterdgas
- Leven bevroren in de tijd onder een elektronenmicroscoop krijgt Nobelprijs
- Studie onthult nieuwe inzichten in hoe hybride perovskiet-zonnecellen werken
- Baanbrekende kwantumchemietechniek voor computationeel ontwerp en optimalisatie van organische fotofunctionele materialen
Hoofdlijnen
- Hoe verbeteren microscopen ons leven vandaag?
- Wetenschappers ontwikkelen aardnoot die resistent is tegen aflatoxine
- Team publiceert onderzoek naar ongewone genevolutie in bacteriën
- Wat is het verschil tussen continue en discontinue DNA-synthese?
- Een eiwitduo zorgt ervoor dat de chromosomen in de voortplantingscellen hun significante andere vinden
- Hoe maak je een plantencelmodel op stap-voor-stap
- Top 10 mythes over de hersenen
- In vijverschuim, wetenschappers vinden antwoorden op een evolutie die het eerst kwam gevallen
- De effecten van temperatuur op enzymactiviteit en biologie
- Wereldprimeur als kunstmatige neuronen ontwikkeld om chronische ziekten te genezen

- Romp van nieuwe Boeing 777X gescheurd tijdens druktests

- Gebouwen renoveren om energie te besparen

- Blootgestelde Chinese database toont diepte van bewakingsstatus

- Wie neemt en verkoopt uw persoonlijke gegevens? Wetgevers in de staat Washington werken eraan om mensen meer inspraak te geven


 Klimaatverandering en de effecten ervan op de bergmeren van Rocky Mountain
Klimaatverandering en de effecten ervan op de bergmeren van Rocky Mountain- Scienceweekprojecten van twee weken
- Het grootste vuur groeit, dwingt evacuatie van wildstation af
- Webcam op Mars Express onderzoekt wolken op grote hoogte
- Adolescente meisjes beschermen tegen geweld
- Duinen gevangen in een krater op Mars vormen dit interessante patroon
- YouTubes Notre Dame-9/11 flub benadrukt AI's blinde vlekken
- Hoe klimaatverandering de bouwstenen voor gezondheid beïnvloedt
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Dutch | Danish | Norway | Swedish | German |

-
Wetenschap © https://nl.scienceaq.com
