Wetenschap
Model voorspelt cognitieve achteruitgang door Alzheimer, tot twee jaar uit
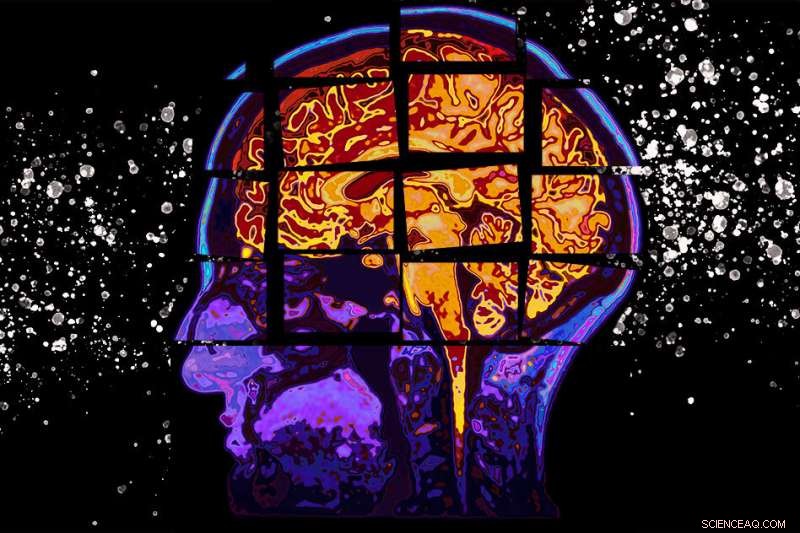
Een model ontwikkeld aan het MIT voorspelt de cognitieve achteruitgang van patiënten met een risico op de ziekte van Alzheimer door hun cognitietestscores tot twee jaar in de toekomst te voorspellen, wat zou kunnen helpen bij het vinden van de juiste patiënten om te selecteren voor klinische onderzoeken. Krediet:Christine Daniloff, MIT
Een nieuw model ontwikkeld aan het MIT kan helpen voorspellen of patiënten met een risico op de ziekte van Alzheimer een klinisch significante cognitieve achteruitgang zullen ervaren als gevolg van de ziekte. door hun cognitietestscores tot twee jaar in de toekomst te voorspellen.
Het model zou kunnen worden gebruikt om de selectie van kandidaat-geneesmiddelen en deelnemerscohorten voor klinische proeven te verbeteren, die tot dusver niet succesvol zijn geweest. Het zou patiënten ook laten weten dat ze de komende maanden en jaren een snelle cognitieve achteruitgang kunnen ervaren, zodat zij en hun dierbaren zich kunnen voorbereiden.
Farmaceutische bedrijven hebben de afgelopen twee decennia honderden miljarden dollars geïnjecteerd in onderzoek naar de ziekte van Alzheimer. Toch wordt het veld geplaagd door mislukkingen:tussen 1998 en 2017 er waren 146 mislukte pogingen om medicijnen te ontwikkelen om de ziekte te behandelen of te voorkomen, volgens een rapport uit 2018 van het Pharmaceutical Research and Manufacturers of America. In die tijd, slechts vier nieuwe geneesmiddelen werden goedgekeurd, en alleen om symptomen te behandelen. Momenteel zijn er meer dan 90 kandidaat-geneesmiddelen in ontwikkeling.
Studies suggereren dat meer succes bij het op de markt brengen van medicijnen zou kunnen komen door het werven van kandidaten die zich in de vroege stadia van de ziekte bevinden, voordat de symptomen duidelijk zijn, dat is wanneer de behandeling het meest effectief is. In een paper die volgende week wordt gepresenteerd op de conferentie Machine Learning for Health Care, MIT Media Lab-onderzoekers beschrijven een machine-learningmodel dat clinici kan helpen om in te zoomen op dat specifieke cohort van deelnemers.
Ze trainden eerst een "populatie" -model op een volledige dataset met klinisch significante cognitieve testscores en andere biometrische gegevens van Alzheimerpatiënten. en ook gezonde personen, verzameld tussen de tweejaarlijkse doktersbezoeken. Uit de gegevens, het model leert patronen die kunnen helpen voorspellen hoe de patiënten zullen scoren op cognitieve tests die tussen bezoeken worden afgenomen. Bij nieuwe deelnemers een tweede model, gepersonaliseerd voor elke patiënt, werkt continu scorevoorspellingen bij op basis van nieuw geregistreerde gegevens, zoals informatie verzameld tijdens de meest recente bezoeken.
Experimenten geven aan dat nauwkeurige voorspellingen kunnen worden gedaan, vooruitkijkend zes, 12, 18, en 24 maanden. Clinici zouden het model dus kunnen gebruiken om te helpen bij het selecteren van risicodeelnemers voor klinische onderzoeken, die waarschijnlijk een snelle cognitieve achteruitgang vertonen, mogelijk zelfs voordat andere klinische symptomen optreden. Door dergelijke patiënten in een vroeg stadium te behandelen, kunnen clinici beter nagaan welke geneesmiddelen tegen dementie wel en niet werken.
"Nauwkeurige voorspelling van cognitieve achteruitgang van zes tot 24 maanden is van cruciaal belang voor het ontwerpen van klinische onderzoeken, " zegt Oggi Rudovic, een Media Lab-onderzoeker. "Door toekomstige cognitieve veranderingen nauwkeurig te voorspellen, kan het aantal bezoeken dat de deelnemer moet afleggen, worden verminderd, wat duur en tijdrovend kan zijn. Naast het helpen ontwikkelen van een nuttig medicijn, het doel is om de kosten van klinische proeven te helpen verlagen om ze betaalbaarder te maken en op grotere schaal te doen."
Toetreden tot Rudovic op het papier zijn:Yuria Utsumi, een student, en Kelly Peterson, een afgestudeerde student, zowel bij de faculteit Elektrotechniek als Informatica; Ricardo Guerrero en Daniel Rueckert, beide van Imperial College London; en Rosalind Picard, een professor in mediakunsten en -wetenschappen en directeur van affectieve computeronderzoek in het Media Lab.
Bevolking naar personalisatie
Voor hun werk, de onderzoekers maakten gebruik van 's werelds grootste dataset van klinische onderzoeken naar de ziekte van Alzheimer, genaamd Alzheimer's Disease Neuroimaging Initiative (ADNI). De dataset bevat gegevens van ongeveer 1, 700 deelnemers, met en zonder Alzheimer, geregistreerd tijdens halfjaarlijkse doktersbezoeken gedurende 10 jaar.
Gegevens omvatten hun AD Assessment Scale-cognition subschaal (ADAS-Cog13) scores, de meest gebruikte cognitieve maatstaf voor klinische proeven met geneesmiddelen tegen de ziekte van Alzheimer. De test beoordeelt het geheugen, taal, en oriëntatie op een schaal van toenemende ernst tot 85 punten. De dataset omvat ook MRI-scans, demografische en genetische informatie, en cerebrospinale vloeistof metingen.
In alles, de onderzoekers trainden en testten hun model op een subcohort van 100 deelnemers, die meer dan 10 bezoeken aflegden en voor minder dan 85 procent ontbrekende gegevens hadden, elk met meer dan 600 berekenbare functies. Van die deelnemers 48 werden gediagnosticeerd met de ziekte van Alzheimer. Maar gegevens zijn schaars, waarbij verschillende combinaties van functies voor de meeste deelnemers ontbreken.
Om dat aan te pakken, de onderzoekers gebruikten de gegevens om een populatiemodel te trainen dat werd aangedreven door een "niet-parametrisch" waarschijnlijkheidskader, Gaussiaanse processen (GP's) genoemd, die flexibele parameters heeft om in verschillende kansverdelingen te passen en om onzekerheden in gegevens te verwerken. Deze techniek meet overeenkomsten tussen variabelen, zoals patiëntgegevenspunten, om een waarde te voorspellen voor een ongezien gegevenspunt, zoals een cognitieve score. De output bevat ook een schatting van hoe zeker het is over de voorspelling. Het model werkt robuust, zelfs bij het analyseren van datasets met ontbrekende waarden of veel ruis uit verschillende formaten voor het verzamelen van gegevens.
Maar, bij het evalueren van het model op nieuwe patiënten van een achterblijvend deel van de deelnemers, de onderzoekers ontdekten dat de voorspellingen van het model niet zo nauwkeurig waren als ze zouden kunnen zijn. Dus, ze personaliseerden het populatiemodel voor elke nieuwe patiënt. Het systeem zou dan geleidelijk de lacunes in de gegevens opvullen bij elk nieuw patiëntbezoek en de voorspelling van de ADAS-Cog13-score dienovereenkomstig bijwerken, door de voorheen onbekende verdelingen van de huisartsen continu bij te werken. Na ongeveer vier bezoeken, de gepersonaliseerde modellen verminderden het foutenpercentage in voorspellingen aanzienlijk. Het presteerde ook beter dan verschillende traditionele machine learning-benaderingen die worden gebruikt voor klinische gegevens.
Leren hoe te leren
Maar de onderzoekers ontdekten dat de resultaten van de gepersonaliseerde modellen nog steeds suboptimaal waren. Om dat op te lossen, ze bedachten een nieuw 'metalearning'-schema dat leert automatisch te kiezen welk type model, bevolking of gepersonaliseerd, het beste werkt voor een bepaalde deelnemer op een bepaald moment, afhankelijk van de gegevens die worden geanalyseerd. Metalearning is eerder gebruikt voor computervisie en machinevertalingstaken om nieuwe vaardigheden te leren of zich snel aan te passen aan nieuwe omgevingen met een paar trainingsvoorbeelden. Maar dit is de eerste keer dat het wordt toegepast om cognitieve achteruitgang van Alzheimerpatiënten te volgen. waar beperkte gegevens een grote uitdaging vormen, zegt Rudovic.
Het schema simuleert in wezen hoe de verschillende modellen presteren op een bepaalde taak - zoals het voorspellen van een ADAS-Cog13-score - en leert de beste pasvorm. Bij elk bezoek van een nieuwe patiënt, het schema wijst het juiste model toe, op basis van de eerdere gegevens. Bij patiënten met luidruchtige, schaarse gegevens tijdens vroege bezoeken, bijvoorbeeld, populatiemodellen maken nauwkeurigere voorspellingen. Wanneer patiënten met meer gegevens beginnen of meer verzamelen door volgende bezoeken, echter, gepersonaliseerde modellen presteren beter.
Dit hielp het foutenpercentage voor voorspellingen met nog eens 50 procent te verminderen. "We konden geen enkel model of vaste combinatie van modellen vinden die ons de beste voorspelling zouden kunnen geven, " zegt Rudovic. "Dus, we wilden leren hoe te leren met dit metalearning-schema. Het is als een model bovenop een model dat als selector fungeert, getraind met behulp van metakennis om te beslissen welk model beter kan worden ingezet."
Volgende, de onderzoekers hopen samen te werken met farmaceutische bedrijven om het model te implementeren in klinische onderzoeken naar de ziekte van Alzheimer. Rudovic zegt dat het model ook kan worden gegeneraliseerd om verschillende statistieken voor de ziekte van Alzheimer en andere ziekten te voorspellen.
Dit verhaal is opnieuw gepubliceerd met dank aan MIT News (web.mit.edu/newsoffice/), een populaire site met nieuws over MIT-onderzoek, innovatie en onderwijs.
 Onderzoekers ontwikkelen radars in de lucht om de kenmerken van Amerikaanse snowpacks voor watermodellen te meten
Onderzoekers ontwikkelen radars in de lucht om de kenmerken van Amerikaanse snowpacks voor watermodellen te meten- Casestudy's bieden diepgaande lessen over duurzaamheid
- Milieuwetenschappers noemen de noodzaak van onderzoeken naar de impact van microplastics
- Grote bosbranden zorgen voor een toename van de jaarlijkse rivierstroom
- Het behalen van de klimaatdoelstelling van Parijs kan extra miljarden aan visserij-inkomsten opleveren
Hoofdlijnen
- Nieuw onderzoek naar spermastamcellen heeft gevolgen voor mannelijke onvruchtbaarheid en kanker
- Een 3D-cel maken
- EU-lidstaten stemmen volgende maand over vijfjarige verlenging van onkruidverdelger
- Big data helpt onderzoekers in de strijd om plantenindringers onder controle te krijgen
- Verbetering van de neuronenfabriek - nieuwe modulator van stamcelidentiteit gevonden
- Genetisch manipulatiemechanisme gevisualiseerd
- Vleermuizen anticiperen op optimale weersomstandigheden
- Hoe werkt het spierenstelsel met de bloedsomloop?
- Studie onthult nieuw inzicht in onsterfelijke plantencellen
- Winst Cathay Pacific 2019 keldert, voorspelt virusverliezen

- Vliegtuigpiloten kunnen een oprukkende drone meestal niet zien, studie toont

- Veilige paden:een privacy-first benadering van contacttracering

- Langverwachte videodienst maandag verwacht van Apple

- Een neurorobotica-aanpak voor het bouwen van robots met communicatieve vaardigheden

 Studie biedt eerste grootschalige bewijs van het effect van ethiektraining op het gedrag van de financiële sector
Studie biedt eerste grootschalige bewijs van het effect van ethiektraining op het gedrag van de financiële sector- De ventilatiesnelheid voor een besloten ruimte berekenen
- De leeftijd van mensen schatten met behulp van convolutionele neurale netwerken
- Welk deel van de nephron is verantwoordelijk voor de heropname van water?
- Een ruimte-tijdsensor voor interacties tussen licht en materie
- Bedrijven profiteren van het geven van getuigenissen van het congres, studie vondsten
- Kijken en luisteren naar signalen van marinetestexplosies voor de kust van Florida
- Wetenschappers ontdekken een nieuwe klasse nanozymen met één atoom
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Portuguese | Swedish | German | Dutch | Danish | Italian | Norway |

-
Wetenschap © https://nl.scienceaq.com
