Wetenschap
CycleMatch:een nieuwe aanpak voor het matchen van afbeeldingen en tekst
Krediet:Liu et al.
Onderzoekers van de Universiteit Leiden en de Nationale Universiteit voor Defensietechnologie (NUDT), in China, hebben onlangs een nieuwe benadering ontwikkeld voor het matchen van afbeeldingen en tekst, genaamd CycleMatch. Hun aanpak, gepresenteerd in een paper gepubliceerd in Elsevier's Patroonherkenning logboek, is gebaseerd op cyclus-consistent leren, een techniek die soms wordt gebruikt om kunstmatige neurale netwerken te trainen op beeld-naar-beeld vertaaltaken. Het algemene idee achter cyclusconsistentie is dat bij het transformeren van brongegevens naar doelgegevens en vice versa, men zou eindelijk de originele bronmonsters moeten verkrijgen.
Als het gaat om het ontwikkelen van tools voor kunstmatige intelligentie (AI) die goed presteren in multimodale of op multimedia gebaseerde taken, het vinden van manieren om afbeeldingen en tekstrepresentaties te overbruggen is van cruciaal belang. Eerdere studies hebben geprobeerd dit te bereiken door semantiek of kenmerken bloot te leggen die relevant zijn voor zowel visie als taal.
Bij het trainen van algoritmen op correlaties tussen verschillende modaliteiten, echter, deze studies hebben de intramodale semantische consistentie vaak verwaarloosd of niet behandeld, dat is de consistentie van de semantiek voor de individuele modaliteiten (d.w.z. visie en taal). Om deze tekortkoming aan te pakken, het team van onderzoekers van de Universiteit Leiden en NUDT stelde een aanpak voor die cyclusconsistente inbedding toepast op een diep neuraal netwerk voor het matchen van visuele en tekstuele representaties.
"Onze aanpak, genoemd als CycleMatch, kan zowel intermodale correlaties als intramodale consistentie behouden door dubbele mappings en gereconstrueerde mappings op een cyclische manier te laten lopen, ' schreven de onderzoekers in hun paper. 'Bovendien, om tot een robuuste gevolgtrekking te komen, we stellen voor om twee late-fusiebenaderingen te gebruiken:gemiddelde fusie en adaptieve fusie."
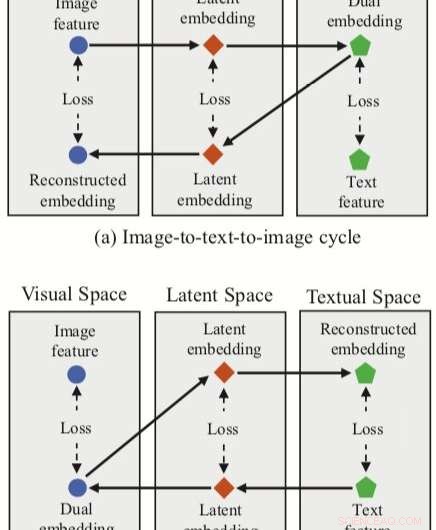
De door de onderzoekers bedachte aanpak integreert drie functie-inbeddingen (dual, gereconstrueerde en latente inbeddingen) met een neuraal netwerk voor het matchen van afbeeldingen en tekst. De methode heeft twee cyclustakken, een vanuit een beeldkenmerk in de visuele ruimte en een vanuit een tekstkenmerk in de tekstuele ruimte.
Voor elk van deze cycli hun aanpak zorgt voor een dubbele mapping, het vertalen van een invoerkenmerk in de bronruimte naar een dubbele inbedding in de doelruimte. De onderzoekers passen vervolgens gereconstrueerde mapping toe, proberen deze dubbele inbedding terug te vertalen naar de bronruimte.
Hun aanpak stelt de onderzoekers ook in staat om een 'latente ruimte' te verwerven tijdens zowel duale als gereconstrueerde mappings, en vervolgens latente inbeddingen correleren. In tegenstelling tot andere technieken voor het matchen van afbeeldingen en tekst, daarom, hun methode kan zowel intermodale mappings (d.w.z. beeld-naar-tekst en tekst-naar-beeld) als intra-modale mappings (beeld-naar-beeld en tekst-naar-tekst) leren.
Om hun aanpak te evalueren, voerden de onderzoekers een reeks experimenten uit met behulp van twee gerenommeerde multimodale datasets, Flickr30K en MSCOCO. Hun methode bereikte state-of-the-art resultaten, beter presteren dan traditionele benaderingen en leiden tot aanzienlijke verbeteringen in cross-modale retrieval.
Deze bevindingen suggereren dat cyclus-consistente inbeddingen de prestaties van neurale netwerken in multimodale taken zouden kunnen verbeteren, zoals afbeelding-tekst matching, waardoor ze zowel intermodale als intramodale mappings kunnen verwerven. In hun toekomstige werk, de onderzoekers zijn van plan hun aanpak verder te ontwikkelen, door rekening te houden met lokale relaties bij het matchen van afbeeldingen en tekst (bijv. semantische correlaties tussen visuele regio's en zinnen).
© 2019 Wetenschap X Netwerk
 Hawaï regent, overstromingen genoemd als voorbeelden van klimaatverandering
Hawaï regent, overstromingen genoemd als voorbeelden van klimaatverandering- ijskoude arctische lucht, winterstormen grijpen een groot deel van ons aan
- Snelle toename van wereldwijde lichtvervuiling
- Klimaatverandering kan de impact van bospathogenen in bomen veranderen
- Hoe snel de planeet opwarmt, is cruciaal voor de leefbaarheid
Hoofdlijnen
- Waarom zie je nooit vierkante groenten?
- Vissen reageren op aanvallen van roofdieren door de groeisnelheid te verdubbelen
- Difference Between Gap Junctions & Plasmodesmata
- Een 3D-model plantencel maken zonder voedsel
- Ambien
- Een incubator laten groeien Bacteriën
- Wetenschappers controleren cellen met licht,
- Psychologische theorie over de vijf menselijke zintuigen
- Hoeveel zintuigen heeft een mens?
- Coole nieuwe draagbare apparaten kunnen wonderen doen voor je gezondheid

- Voormalig Intel-baas Brian Krzanich leidt CDK Global

- Waarom het web de autoriteit van wetenschappers heeft uitgedaagd - en waarom ze zich moeten aanpassen

- INLs TREAT-reactor voltooit met succes het eerste van brandstof voorziene experiment

- Snapchat daagt Facebook uit onder Amerikaanse jongeren:enquête


 Supergeleidende tokamaks staan rechtop
Supergeleidende tokamaks staan rechtop- Hoe een auto op zonne-energie te bouwen
- De positie en baan van de aarde leidden tot het uitsterven van het oude zeeleven
- PayPal voorzichtig over toekomst van Libra-cryptocurrency
- Chinese ijsbreker stoomt naar Antarctica in poolmachtspel
- Bacteriën kunnen meer bijdragen aan klimaatverandering naarmate de planeet warmer wordt
- Een eenvoudigere manier om eiwitten te maken kan leiden tot nieuwe nanomedicijnen
- De kleinst denkbare schakelaar:gerichte protonenoverdracht binnen een molecuul
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Spanish | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
