Wetenschap
De beste functies selecteren voor detectie-algoritmen voor phishing-aanvallen
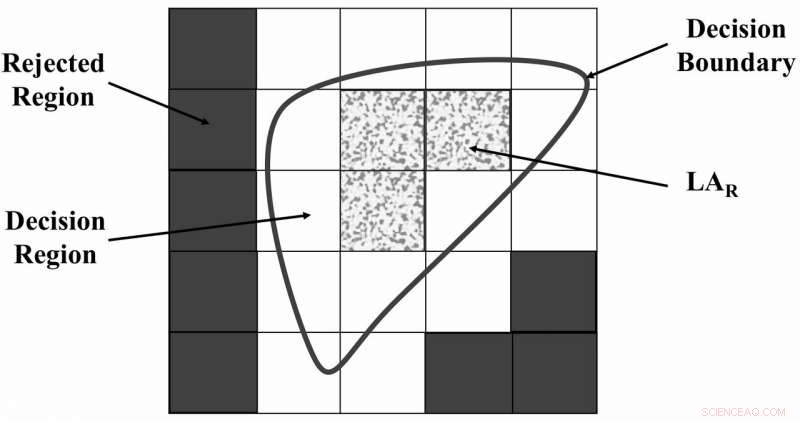
Het universum van discoursregio's gescheiden door FRS. Krediet:Zabihimayvan &Doran.
In de afgelopen decennia, phishing-aanvallen komen steeds vaker voor. Met deze aanvallen kunnen aanvallers gevoelige gebruikersgegevens verkrijgen, zoals wachtwoorden, gebruikersnamen, creditcard details, enzovoort., door mensen te misleiden om persoonlijke informatie vrij te geven. De meest voorkomende vorm van phishing-aanval is e-mailzwendel waarbij gebruikers worden doen geloven dat ze hun gegevens aan een gevestigde of vertrouwde entiteit moeten geven, terwijl ze zijn, in feite, het delen van deze gegevens met iemand anders.
IT-professionals hebben een groot aantal tools en strategieën ontwikkeld om phishing-aanvallen te detecteren en te voorkomen, waarvan vele gebaseerd zijn op machine learning. De prestaties van dergelijke algoritmen voor machine learning zijn vaak afhankelijk van de functies die ze uit websites halen.
Onderzoekers van de Wright State University hebben onlangs een nieuwe methode ontwikkeld om de beste sets functies voor detectie-algoritmen voor phishing-aanvallen te identificeren. Hun aanpak, geschetst in een paper dat vooraf is gepubliceerd op arXiv, zou kunnen helpen om de prestaties van individuele machine-learning-algoritmen voor het opsporen van phishing-aanvallen te verbeteren.
"De prestaties van phishing-detectie-algoritmen die machine learning gebruiken, zijn sterk afhankelijk van de kenmerken van een website die het algoritme in overweging neemt, inclusief de lengte van de webpagina-URL of als speciale tekens zoals @ en streepje in de URL voorkomen, " Mahdieh Zabihimayvan en Derek Doran, de twee onderzoekers die het onderzoek uitvoerden, vertelde TechXplore via e-mail. "In dit werk, we wilden het gemakkelijker maken om machine learning-algoritmen voor phishing-detectie te bouwen door automatisch een 'beste' set functies voor elk phishing-detectie-algoritme te herstellen, ongeacht de website in kwestie."
Hoewel er nu verschillende algoritmen zijn om phishing-aanvallen te identificeren, tot dusver, zeer weinig studies hebben zich gericht op het bepalen van de meest effectieve functies voor het detecteren van dit specifieke type aanval. In hun studie hebben Zabihimayvan en Doran gingen in op deze leemte in de literatuur, door te proberen de meest effectieve functies voor deze specifieke taak te ontdekken.
"We hebben de Fuzzy Rough Set (FRS)-theorie toegepast als een hulpmiddel om de meest effectieve functies te selecteren uit drie gebenchmarkte phishing-websitedatasets, " Zabihimayvan en Doran zeiden. "De geselecteerde functies worden vervolgens gebruikt voor drie veelgebruikte machine-learning-algoritmen voor phishing-detectie."
Om de effectiviteit en generaliseerbaarheid van hun FRS-functieselectiebenadering te testen, de onderzoekers gebruikten het om drie veelgebruikte classificaties voor phishing-detectie te trainen op een dataset van 14, 000 websitevoorbeelden en evalueerde vervolgens hun prestaties. Hun evaluaties leverden veelbelovende resultaten op, het bereiken van een maximale F-maat van 95 procent wanneer hun functieselectiemethode werd toegepast op een random forest (RM) classifier.
"FRS ontdekt functie-afhankelijkheden op basis van de gegevens, Zabihimayvan en Doran legden het uit. Met andere woorden, FRS beslist hoe een set gegevens wordt gescheiden op basis van hun kenmerkwaarden en labels met behulp van een beslissingsgrens en een overeenkomstrelatie die wordt gedeclareerd in de vorm van fuzzy-lidmaatschapsfuncties. Functies die door FRS zijn geselecteerd, zijn degenen die meer onderscheid kunnen maken tussen gegevensmonsters die tot verschillende klassen behoren."
De FRS-aanpak die door Zabihimayvan en Doran werd gebruikt, selecteerde negen universele kenmerken in alle datasets die in hun onderzoek werden gebruikt. Met behulp van deze universele functieset, ze behaalden een F-maat van ongeveer 93 procent, wat vergelijkbaar is met wat wordt bereikt door classifiers die hun FRS-benadering gebruiken. De universele functieset bevat geen functies van services van derden, dus deze bevinding suggereert dat phishing-aanvallen mogelijk sneller kunnen worden gedetecteerd zonder onderzoek van externe bronnen.
"De functies die automatisch door FRS zijn geselecteerd, leveren de beste detectieprestaties op voor een aantal classificaties, " Zabihimayvan en Doran zeiden. "We vinden ook een reeks 'universele functies' - die aspecten van een webpagina die FRS het beste voorspelde of een pagina informatie probeert te vissen, ongeacht het type website dat de pagina probeert na te bootsen."
De studie uitgevoerd door Zabihimayvan en Doran is een van de eerste die waardevolle inzichten oplevert over de meest effectieve functies voor het detecteren van phishing-aanvallen. In de toekomst, hun werk zou de weg kunnen banen voor de ontwikkeling van efficiëntere en betrouwbaardere detectietechnieken voor phishing, die deze aanvallen sneller zouden ontdekken dan de huidige methoden.
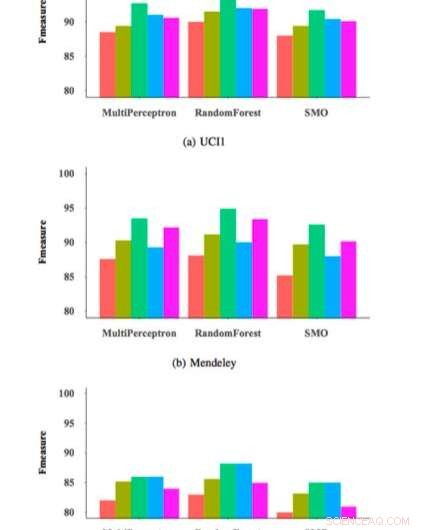
F-maat voor verschillende classificaties en functiesets. Krediet:Zabihimayvan &Doran.
"We hopen nu onze studie verder uit te breiden door functieselectie te onderzoeken voor meer geavanceerde algoritmen voor machine learning, inclusief deep learning-architecturen die automatisch 'meta-functies' ontdekken om de detectieprestaties verder te verbeteren, Zabihimayvan en Doran zeiden. "We zijn ook van plan om ons kader voor functieselectie uit te breiden om phishing-e-mails te detecteren."
© 2019 Wetenschap X Netwerk
 Opsporen van vuilbronnen voor strafrechtelijk onderzoek
Opsporen van vuilbronnen voor strafrechtelijk onderzoek- Onderzoekers stellen een nieuwe benadering voor om heterogene fotosynthese van azoverbindingen te verbeteren
- Wetenschappers bakken glutenvrij brood met een revolutionaire technologie
- Geactiveerde kool
- Smartphonelab levert testresultaten in een oogwenk
Hoofdlijnen
- Microbiële bewoner stelt kevers in staat zich te voeden met een bladdieet
- Trucs voor het onthouden van dierenfylum
- Waarom is diffusie belangrijk voor het leven van een cel?
- De verschillen tussen monosachariden en polysachariden
- De voordelen van het bestuderen van cellen onder een lichtmicroscoop
- Waarom hebben de meeste mensen 23 paar chromosomen?
- Een beetje stress is goed voor de gezondheid van de cellen en een lang leven
- De Middellandse Zee:onvergelijkbare rijkdom in scherpe daling
- Wat betekent homozygoot?





 Kenmerken van duiven
Kenmerken van duiven - Hoe de breedte van een rechthoekige prisma te vinden
- Mississippi Delta moerassen in een staat van onomkeerbare ineenstorting, studie toont
- Gigantische verbetering van het magnetische effect zal de spintronica ten goede komen
- Nieuw type nanosensor detecteert DNA-bouwstenen
- Bosbranden geven tientallen jaren aan verontreinigende stoffen vrij die door bossen worden opgenomen
- Euraziatische instorting ijskap verhoogde zeeën acht meter:studie
- Grafeencoating verandert fragiele aerogels in superelastische materialen
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway | French |

-
Wetenschap © https://nl.scienceaq.com
