Wetenschap
CruzAffect:een veelzijdige benadering om geluk te karakteriseren
Krediet:CC0 Publiek Domein
Een team van onderzoekers van UC Santa Cruz heeft onlangs een nieuwe machine learning-aanpak ontwikkeld om geluk te karakteriseren, genaamd CruzAffect. Hun aanpak, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, kan worden toegepast op verschillende modellen voor classificatie van affectieve inhoud, inclusief zowel traditionele classificaties als deep learning convolutionele neurale netwerken (CNN).
Deze recente studie bouwt voort op eerder onderzoek waarin werd onderzocht hoe mensen first-person affect en geluk overbrengen. In een studie, dezelfde onderzoekers ontdekten dat mensen de neiging hebben om situaties te beschrijven, zoals 'mijn vriend heeft bloemen voor me gekocht', of 'ik heb een parkeerkaart', waaruit andere mensen gemakkelijk hun impliciete affectieve reacties kunnen afleiden. Ze concludeerden dat compositorische semantiek sterk bewijs kan leveren van het sentiment geassocieerd met een bepaalde gebeurtenis.

Krediet:Wu et al.
In een andere studie, de onderzoekers probeerden de taalkundige beschrijvingen van gebeurtenissen van mensen te baseren op theorieën over welzijn en geluk. Door een corpus van privé-microblogs te analyseren die zijn geëxtraheerd uit een applicatie genaamd Echo, ze onderzochten in hoeverre verschillende theoretische verklaringen de variantie konden verklaren in de geluksscores die Echo-gebruikers gaven aan dagelijkse gebeurtenissen in hun leven.
"Het is een uitdaging om een affectieve gebeurtenis te generaliseren en te associëren met welzijnstheorieën, " Jiaqi Wu, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "In ons eerdere onderzoek we hebben gemerkt dat er geen enkele theorie is die het sentiment van alle affectieve gebeurtenissen kan voorspellen. Het doel van ons recente werk was om specifieke compositorische semantiek te identificeren die het sentiment van gebeurtenissen karakteriseert en om geluk te modelleren op een hoger niveau van generalisatie. Echter, het vinden van generieke kenmerken voor het modelleren van welzijn blijft een uitdaging."
Het primaire doel van de recente studie van Wu en haar collega's was om de effectiviteit te onderzoeken van traditionele machine learning-methoden en deep learning-methoden voor affectieve inhoudsclassificatie. Om dit te behalen, ze identificeerden een reeks kenmerken die geluk kenmerken in affectieve inhoud en pasten deze toe op een traditionele classificatie, XGBoostelijk bos, en een CNN.
"Ons project, genaamd CruzAffect, omvat de ontwikkeling van twee verschillende modellen:een traditionele machine learning-methode (d.w.z. XGBoosted forest) en een deep learning CNN met GloVe-inbedding, " zei Wu. "We gebruiken syntactische functies, emotionele kenmerken, en profielfuncties, en hun prestaties zijn stabiel voor verschillende taken voor classificatie van affectieve inhoud."
Eigenlijk, de onderzoekers evalueerden de prestaties van twee verschillende machine learning-modellen voor affectieve inhoudsclassificatie (XGBoosted forest en een CNN), die beide inhoud analyseerden op basis van de functies die ze eerder hadden geïdentificeerd. Waaronder:
- Syntactische kenmerken:deel van spraak, zelfstandige naamwoorden, werkwoorden, bijvoegelijke naamwoorden en bijwoorden, gebruik van vragen, tijds- en aspectinformatie.
- Emotionele kenmerken:Linguïstisch onderzoek en aantal woorden (LIWC) v2007, emotie lexicon, subjectiviteit lexicon, niveau van feitelijke en emotionele taal.
- Word Embedding:Handschoen 100 dimensie woordvectoren voor woordrepresentatie.
- Profielkenmerken:leeftijd, land, geslacht, burgerlijke staat, ouderschap, enzovoort.
Dankzij deze functies konden de onderzoekers essentiële indicatoren van sociale betrokkenheid en controle ontdekken die verschillende mensen tijdens gelukkige momenten zouden kunnen uitoefenen. In hun studie hebben ze trainden zowel het XGBoosted- als het CNN-model met gesuperviseerd leren op een dataset van 10, 000 gelabelde tekstfragmenten. Ze hebben de modellen ook getraind om pseudo-labels te genereren voor 70, 000 niet-gelabelde fragmenten met behulp van een bootstapped semi-supervised benadering, omdat ze hierdoor hun dataset konden verbreden. Al deze tekstfragmenten zijn geëxtraheerd uit de HappyDB-database.

CNN-architectuur. Krediet:Wu et al.
"De betekenisvolle bevindingen van onze studie omvatten de interessante syntactische patronen die zich herhalen over verschillende domeinen, " zei Wu. "Dergelijke taalpatronen worden waarschijnlijk geassocieerd met welzijnstheorieën. We vinden ook dat de functies die deskundige kennis omvatten, zoals het LIWC-woordenboek kan de prestaties van het traditionele model verbeteren, evenals het deep learning-model in de classificatietaken voor affectieve inhoud."
De onderzoekers evalueerden de XGBoosted forest- en CNN-modellen op de binaire classificatie van agency en sociale labels, evenals op de multi-class voorspelling van conceptlabels. Hun evaluaties leverden veelbelovende resultaten op, wat suggereert dat de door hen geïdentificeerde kenmerken bijzonder effectief zijn voor het classificeren van affectieve inhoud. Hoewel het op CNN gebaseerde model beter presteerde op classificatietaken met meerdere klassen, het traditionele machine learning-model behaalde vergelijkbare resultaten met behulp van de functies die ze eerder hadden geïdentificeerd.
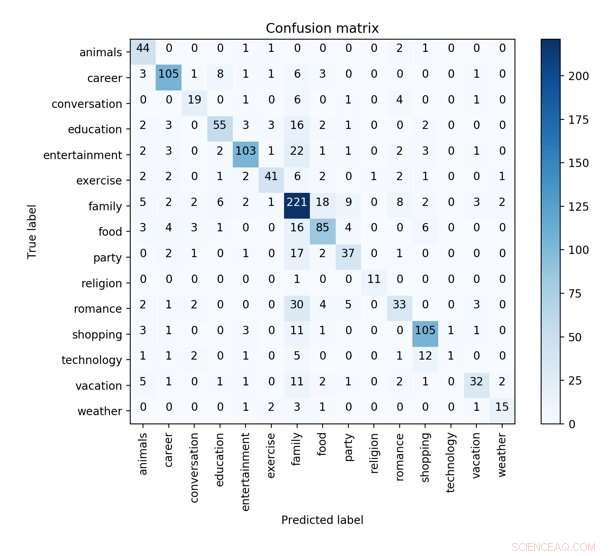
De verwarringsmatrix van het beste CNN-model met syntactische, emotionele en profielkenmerken in 10-voudige kruisvalidatie om de kenmerkende concepten te voorspellen. Krediet:Wu et al.
Het onderzoek van Wu en haar collega's bracht algemene thema's aan het licht die terugkeren in de beschrijvingen van gelukkige momenten door mensen. In de toekomst, hun bevindingen zouden kunnen bijdragen aan de ontwikkeling van nieuwe modellen voor affectieve classificatietaken, waardoor onderzoekers welzijn en geluk effectief kunnen voorspellen door de inhoud van tekstfragmenten te analyseren.
"Ik zal nu de domeinoverschrijdende affectieve gebeurtenisanalyse onderzoeken, en een beter model onderzoeken om de taalkundige beschrijvingen van gebeurtenissen die gebruikers ervaren te onderbouwen in theorieën over welzijn en geluk, Wu zei. "Na het begrijpen van de relatie tussen de affectieve inhoud en welzijnstheorieën, we kunnen misschien algemene affectieve gebeurtenissen verzamelen die sterk gerelateerd zijn aan het welzijn."

Het team van onderzoekers dat het onderzoek heeft uitgevoerd. Krediet:Wu et al.
© 2019 Wetenschap X Netwerk
 Onderzoek onthult een nieuwe manier om chirale katalysatoren te maken
Onderzoek onthult een nieuwe manier om chirale katalysatoren te maken- Biovriendelijke protocellen pompen bloedvaten op
- Veilige oplossing om olievlekken op te ruimen
- Een materiaalgeheugen gebruiken om unieke fysieke eigenschappen te coderen
- Polymeren effenen de weg voor een breder gebruik van gerecyclede banden in asfalt
Hoofdlijnen
- Een model van een cel-kern maken
- De illegale schildpaddenhandel - waarom wetenschappers geheimen bewaren
- Temperatuur kan de pollenkleur beïnvloeden
- Soorten Agar-platen
- Vijf redenen om de insecten in je tuin niet te besproeien
- EU stelt stemming over verlenging omstreden vergunning voor onkruidverdelger uit
- Dodelijk beheer van wolven op één plek kan de situatie in de buurt erger maken
- Wat zijn de functies van een levercel?
- Centriole: definitie, functie en structuur
- Geautomatiseerd systeem kan verouderde zinnen in Wikipedia-artikelen herschrijven
- Gezichtsgebaren kunnen deze AI-gemotoriseerde rolstoel verplaatsen

- Het voorkomen van cyberbeveiligingsaanvallen ligt in strategische, investeringen van derden, studie vondsten

- De op een na grootste luchtvaartmaatschappij van Frankrijk, Aigle Azur, gaat onder curatele

- Tinder, Grindr beschuldigd van het illegaal delen van gebruikersgegevens


 Compact, goedkope vingerafdruklezer zou de kindersterfte over de hele wereld kunnen verminderen
Compact, goedkope vingerafdruklezer zou de kindersterfte over de hele wereld kunnen verminderen- NASA ziet tropische storm Flossie op weg naar de centrale Stille Oceaan
- Zuid-Afrika heft rampspoed op vanwege droogte
- NASA activeert Deep Space Atomic Clock
- Microplastics zijn overal, studie vondsten
- Over bodemerosie
- Gasdynamiek in een nabijgelegen protostellair binair systeem bestudeerd met ALMA
- NASA's Mars-helikopter meldt zich in
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | Swedish | German | Dutch | Danish | Norway |

-
Wetenschap © https://nl.scienceaq.com
