Wetenschap
Een nieuwe leerbenadering voor ontwikkelingsversterking voor vergroting van de sensomotorische ruimte
Krediet:Zimmer, Bonifatius, en Dutech.
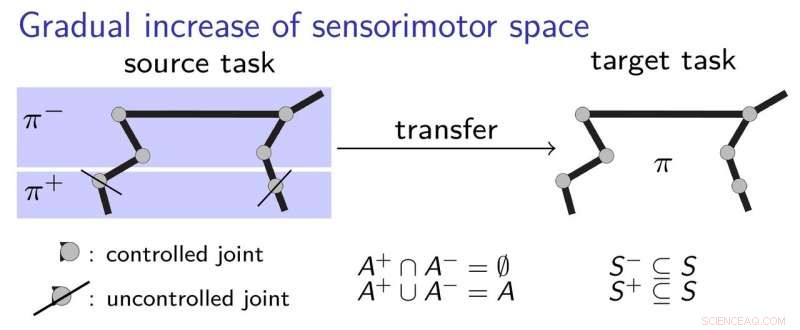
Onderzoekers van de Universiteit van Lorraine hebben onlangs een nieuw type transfer learning ontwikkeld op basis van modelvrij diep versterkend leren met continue vergroting van de sensorimotorische ruimte. Hun aanpak, gepresenteerd in een paper gepubliceerd tijdens de achtste Joint IEEE International Conference on Development and Learning and on Epigenetic Robotics, en vrij beschikbaar op HAL-archieven-ouvertes, is geïnspireerd door de ontwikkeling van kinderen, vooral door de groei van de sensomotorische ruimte die zich voordoet als een kind, leert hij nuttige nieuwe strategieën.
"Het formele raamwerk van versterkend leren kan worden gebruikt om een breed scala aan problemen te modelleren, " zei Matthieu Zimmer, een van de onderzoekers die het onderzoek heeft uitgevoerd. "In dit kader een agent gebruikt een trial-and-error-methode om langzaam te leren welke volgorde van acties het meest geschikt is om een gewenst doel te bereiken. Als aan een aantal vereisten is voldaan, dan vertelt de theorie ons dat we algoritmen hebben die de agent kan gebruiken om de optimale oplossing voor het probleem te vinden, toch kan dit lang duren. Om dit proces te versnellen, we hebben manieren onderzocht waarop een agent goede prestaties kan leveren in minder proeven, zelfs als het bijna geen kennis heeft van de taak die het moet oplossen."
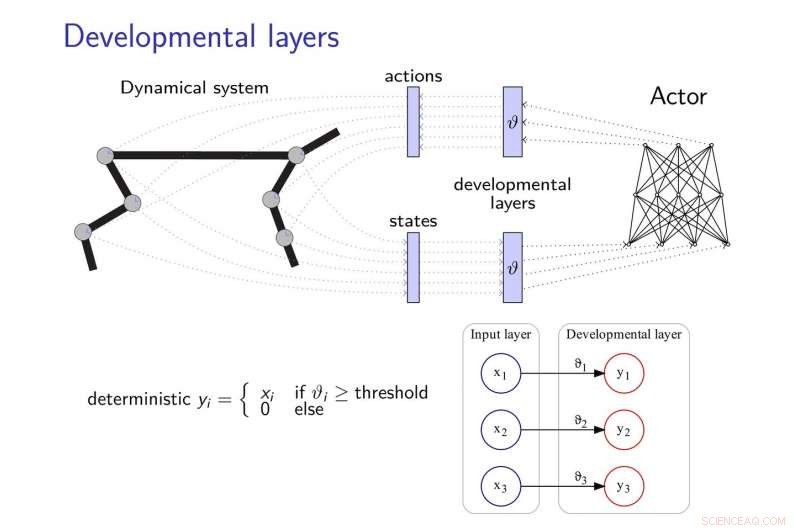
De door Zimmer en zijn collega's voorgestelde transferleermethode voegt ontwikkelingslagen toe aan neurale netwerken, waardoor ze nieuwe strategieën kunnen ontwikkelen om taken te voltooien, vooral wanneer deze taken op de een of andere manier gerelateerd zijn. Deze ontwikkelingslagen onthullen geleidelijk enkele dimensies van de sensomotorische ruimte, het volgen van een intrinsieke motivatieheuristiek.
Om de effecten van "catastrofaal vergeten, " een veelvoorkomend probleem bij de ontwikkeling van neurale netwerken, de onderzoekers lieten zich inspireren door de theorie van elastische gewichtsconsolidatie, gebruiken om het leren van de neurale controller te reguleren.
Krediet:Zimmer, Bonifatius, en Dutech.
"Het basisidee van ons werk is dat de agent begint met zeer beperkte waarnemings- en actiemogelijkheden en deze vervolgens ontwikkelingsgericht ontwikkelt, geïnspireerd door hoe een kind leert, " zei Alain Dutech, een andere onderzoeker die het onderzoek heeft uitgevoerd. "De ruimte waarin de agent naar een oplossing zoekt, wordt zo verkleind, en deze oplossing zij het om een gedegradeerd probleem, gemakkelijker te vinden zijn. Dan vergroten we de mogelijkheden van de agent, profiteren van de eerder gevonden oplossing."
Om beter uit te leggen hoe hun transfer learning-aanpak werkt, de onderzoekers gebruiken het voorbeeld van een kind dat een pen leert grijpen. aanvankelijk, het kind mag alleen haar elleboog en schouder gebruiken, leren hoe de pen aan te raken. achtereenvolgens, ze zou kunnen besluiten om de hand en vingers te gaan gebruiken, de basis hebben begrepen van hoe u het beste contact kunt maken met de pen. Dit houdt een geleidelijk leerproces in, waarbij het kind stap voor stap sensomotorische strategieën verwerft, zonder al te veel dingen tegelijk te moeten leren.
De onderzoekers valideerden hun nieuwe aanpak met behulp van twee state-of-the-art deep learning-algoritmen, namelijk DDPG en NFAC, getest op Half-Cheetah en Humanoid, twee hoogdimensionale omgevingsbenchmarks. Hun resultaten suggereren dat het zoeken naar een suboptimale oplossing in een subset van de parameterruimte voordat de volledige ruimte wordt overwogen, een nuttige techniek is om leeralgoritmen op te starten, betere prestaties behalen met kortere training.
"In het zeer actieve en stimulerende veld van deep-reinforcement learning, we hebben aangetoond dat ontwikkelingsmethoden zoals die van ons, evenals andere soortgelijke onderzocht door andere onderzoekers, kan worden gecombineerd met diepgaande leermethoden om helemaal opnieuw te leren, met weinig voorkennis, ' zei Zimmer.
Ondanks de veelbelovende resultaten, de studie uitgevoerd door Zimmer en zijn collega's benadrukte ook de kloof die nog steeds bestaat tussen de mogelijkheden van diepe neurale netwerken en mensen. In feite, zelfs bij het gebruik van ontwikkelingsversterking leren, de meeste bestaande middelen zijn nog steeds veel minder veelzijdig en efficiënt dan mensen.
"Soms, mensen kunnen leren in slechts één proef, maar zelfs het meest efficiënte kunstmatige leren vereist een complexe combinatie van verschillende algoritmen om te leren, schatting, memoriseren, vergelijken, en optimaliseren, "Zei Zimmer. "Bovendien, sommige van deze algoritmen zijn nog steeds niet duidelijk gedefinieerd."
Dutech en zijn collega's verkennen nu nieuwe horizonten op het gebied van AI en deep learning. Bijvoorbeeld, ze willen nieuwe manieren ontwikkelen waarop een lerende agent de prikkels die hij waarneemt goed kan categoriseren.
"Leren is veel efficiënter wanneer de agent kan interpreteren wat 'ziet' of 'voelt', " legde Dutech uit. "Vandaag, de trend is om hiervoor deep learning en neurale netwerken te gebruiken. We onderzoeken nu andere methoden om relevante en nuttige informatie te extraheren uit de ruwe perceptie van kunstmatige middelen, die minder afhankelijk zijn van een enorm corpus aan voorbeelden; zoals leren zonder toezicht en zelforganisatie."
© 2018 Tech Xplore

Hoofdlijnen
- Cellulair metabolisme: definitie, proces en de rol van ATP
- High School Biology Experiment Ideas
- Leuke wetenschappelijke experimenten op cellen
- Team onthult hoge prevalentie van bacteriën die gen mcr-1 dragen in ecosysteem
- Inspanningen zijn bedoeld om de verspreiding van vuurmieren in de VS te beperken
- Welke soorten cellen delen door mitose en cytokinese?
- Uitwerpselen van verstrikte Noord-Atlantische walvissen onthullen torenhoge stressniveaus
- Thomas Malthus: Biografie, Populatietheorie & Feiten
- Plantaanpassingen: woestijn, tropisch regenwoud, toendra
- Vragen over privacy bij het beoordelen van gebruikersaudio op Facebook

- Europa's toekomst is hernieuwbaar

- Pi is berekend tot 31,4 biljoen decimalen, Google kondigt op Pi-dag aan

- Amerikaans bedrijf voor hernieuwbare energie daagt Polen voor de rechter wegens keerpunt windmolens

- General Electric gaat delen van overzeese verlichtingsactiviteiten verkopen


 Elektrochemie spoelt antibioticaresistente eiwitten weg
Elektrochemie spoelt antibioticaresistente eiwitten weg- Wat zijn lobben in een kern?
- Project in Cyprus om emissies in het Midden-Oosten te monitoren
- Team maakt hoogwaardig grafeen met sojabonen
- Opheldering van het mechanisme van een door licht aangedreven natriumpomp
- UD-uitvinding heeft tot doel de batterijprestaties te verbeteren
- Turbulente tijden onthuld op Asteroid 4 Vesta
- Een nieuw tijdperk in de zoektocht naar donkere materie
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- Italian | Spanish | Portuguese | Swedish | Dutch | Danish | Norway | French | German |

-
Wetenschap © https://nl.scienceaq.com
