Wetenschap
Detectoren voor online haatzaaiende uitlatingen kunnen gemakkelijk door mensen worden bedrogen, studie toont
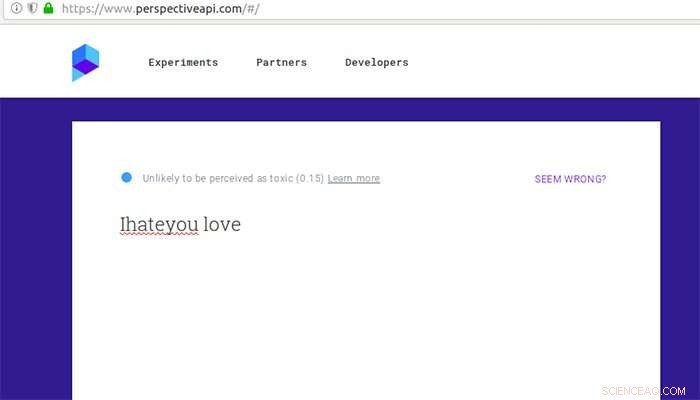
Hoe Google Perspective een opmerking beoordeelt die anders als giftig wordt beschouwd na wat typfouten en een beetje liefde. Krediet:Aalto University
Hatelijke tekst en opmerkingen zijn een steeds groter probleem in online omgevingen, maar het aanpakken van het ongebreidelde probleem is afhankelijk van het kunnen identificeren van giftige inhoud. Een nieuwe studie door de Aalto University Secure Systems-onderzoeksgroep heeft zwakke punten ontdekt in veel machine learning-detectoren die momenteel worden gebruikt om haatspraak te herkennen en op afstand te houden.
Veel populaire sociale media en online platforms gebruiken detectoren voor haatspraak waarvan een team van onderzoekers onder leiding van professor N. Asokan nu heeft aangetoond dat ze broos en gemakkelijk te misleiden zijn. Slechte grammatica en onhandige spelling - opzettelijk of niet - kunnen giftige opmerkingen op sociale media moeilijker maken voor AI-detectoren om te herkennen.
Het team testte zeven ultramoderne detectoren voor haatspraak. Ze zijn allemaal mislukt.
Moderne natuurlijke taalverwerkingstechnieken (NLP) kunnen tekst classificeren op basis van individuele karakters, woorden of zinnen. Wanneer ze geconfronteerd worden met tekstuele gegevens die verschillen van die gebruikt in hun opleiding, ze beginnen te morrelen.
"We hebben typefouten ingevoegd, veranderde woordgrenzen of voegde neutrale woorden toe aan de oorspronkelijke haatspraak. Het verwijderen van spaties tussen woorden was de krachtigste aanval, en een combinatie van deze methoden was zelfs effectief tegen Google's systeem voor het rangschikken van opmerkingen, Perspective, " zegt Tommi Gröndahl, promovendus aan de Aalto University.
Google Perspective rangschikt de 'toxiciteit' van opmerkingen met behulp van tekstanalysemethoden. in 2017, onderzoekers van de Universiteit van Washington toonden aan dat Google Perspective voor de gek gehouden kan worden door simpele typefouten te introduceren. Gröndahl en zijn collega's hebben nu ontdekt dat Perspective sindsdien bestand is tegen eenvoudige typefouten, maar toch voor de gek gehouden kan worden door andere aanpassingen, zoals het verwijderen van spaties of het toevoegen van onschuldige woorden als 'liefde'.
Een zin als "Ik haat je" glipte door de zeef en werd niet-haatdragend toen het werd gewijzigd in "Ihateyou love".
De onderzoekers merken op dat in verschillende contexten dezelfde uiting als hatelijk of louter beledigend kan worden beschouwd. Aanzetten tot haat is subjectief en contextspecifiek, waardoor tekstanalysetechnieken als op zichzelf staande oplossingen onvoldoende zijn.
De onderzoekers bevelen aan om meer aandacht te besteden aan de kwaliteit van datasets die worden gebruikt om machine learning-modellen te trainen, in plaats van het modelontwerp te verfijnen. De resultaten geven aan dat op karakters gebaseerde detectie een haalbare manier zou kunnen zijn om huidige toepassingen te verbeteren.
De studie werd uitgevoerd in samenwerking met onderzoekers van de Universiteit van Padua in Italië. De resultaten worden gepresenteerd tijdens de ACM AISec workshop in oktober.
De studie maakt deel uit van een lopend project genaamd "Deception Detection via Text Analysis in the Secure Systems" aan de Aalto University.
 Diffusie & osmose Lesactiviteiten
Diffusie & osmose Lesactiviteiten - De eiwitten die de biosynthese van formicamycine behouden
- Rekbaar, afbreekbare halfgeleiders
- Wortelcement:hoe wortelgroenten en as beton duurzamer kunnen maken
- Wat gebeurt er met het oxidatie nummer wanneer een atoom in een reactant elektronen verliest?
Het oxidatiegetal van een element geeft de hypothetische lading van een atoom in een verbinding aan. Het is hypothetisch omdat in de context van een verbi
- NASA vindt zware regenval in tropische storm Rita
- algen, zeewier verkleurt de wateren en stranden van Florida
- Het ontwarren van verbindingen tussen stikstofoxiden en sulfaten in de lucht helpt bij het aanpakken van wazige luchtvervuiling
- Door de mens veroorzaakte oorzaken van luchtverontreiniging
- Tropische cycloon Son-Tinh komt aan land en NASA onderzoekt het spoor van regenval
Hoofdlijnen
- Nieuw ontwikkelde schakelaar activeert genen duizenden keren beter dan de natuur
- Wie ontdekte de nucleaire envelop?
- Beschermde zones van het Great Barrier Reef helpen vissen in zelfs licht geëxploiteerde gebieden
- Wat is het verschil tussen een Centriole en een Centrosome?
- Angiogenese versus vasculogenese
- Het testen van chimpansees in Tanzania gedurende tientallen jaren suggereert dat persoonlijkheidstypes stabiel zijn
- Bonobo's helpen vreemden ongevraagd
- Biomedical Engineering Project Onderwerpen voor High School
- Osmosis Feiten voor kinderen
- Wetenschappers ontwikkelen een referentiedoel voor het kalibreren van orbitale satellieten

- Huawei-personeel werkt samen met Chinese militairen aan onderzoek

- Bionische kwallen zwemmen sneller en efficiënter

- Is het streamen van video van schetsmatige websites illegaal?

- Wereldnaties die de armsten in de steek laten op het gebied van energiedoelen:studie


 Eerste observatie van genetische/fysiologische schade veroorzaakt door nanoplastics in mosselen
Eerste observatie van genetische/fysiologische schade veroorzaakt door nanoplastics in mosselen- Een kamerperimeter berekenen
- Publieke perceptie van wetenschappelijke resultaten vervormd door kleurrijke afbeeldingen
- Lichtgevende nanobuisjes worden helderder in nuldimensionale toestanden
- In de Amazone, beschermde gebieden verliezen het vaak wanneer de zoektocht naar energie aan de gang is
- Open dataset van menselijke navigatiestrategieën in buitenlandse netwerksystemen
- Onderzoekers onderzoeken de rol van oceaanmicroben bij klimaateffecten
- Toepassingen van de natuurkunde in het dagelijks leven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Spanish | Portuguese | German | Dutch | Danish | Norway | Swedish |

-
Wetenschap © https://nl.scienceaq.com
