Wetenschap
Baidu-onderzoekers ontwikkelen een nieuw auto-tuning-raamwerk voor autonome voertuigen
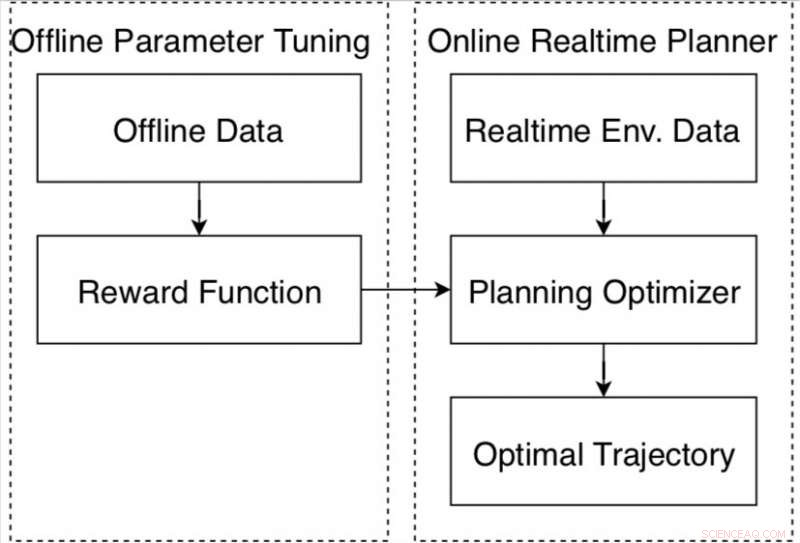
Datagestuurde autonoom rijdende bewegingsplanner op het Apollo-platform. Krediet:Fan et al.
Onderzoekers van het Chinese multinationale technologiebedrijf Baidu hebben onlangs een datagestuurd autotuning-raamwerk voor zelfrijdende voertuigen ontwikkeld op basis van het Apollo-platform voor autonoom rijden. Het frame, gepresenteerd in een paper dat vooraf is gepubliceerd op arXiv, bestaat uit een nieuw versterkend leeralgoritme en een offline trainingsstrategie, evenals een automatische methode voor het verzamelen en labelen van gegevens.
Een bewegingsplanner voor autonoom rijden is een systeem dat is ontworpen om een veilig en comfortabel traject te genereren om een gewenste bestemming te bereiken. Het ontwerpen en afstemmen van deze systemen om ervoor te zorgen dat ze onder verschillende rijomstandigheden goed presteren, is een moeilijke taak die verschillende bedrijven en onderzoekers wereldwijd momenteel proberen aan te pakken.
"Motion planning voor autonoom rijdende auto's heeft veel uitdagende problemen, " Fan Haoyang, een van de onderzoekers die het onderzoek heeft uitgevoerd, vertelde TechXplore. "Een grote uitdaging is dat het te maken heeft met duizenden verschillende scenario's. we definiëren een beloning/kosten-functionele afstemming die die verschillen in scenario's kan aanpassen. Echter, we vinden het een moeilijke taak."
Typisch, beloning-kosten functionele afstemming vereist uitgebreid werk namens onderzoekers, evenals middelen en tijd besteed aan zowel simulaties als tests op de weg. In aanvulling, de omgeving kan in de loop van de tijd drastisch veranderen en naarmate de rijomstandigheden ingewikkelder worden, het afstemmen van de performance van de motion planner wordt steeds moeilijker.

Algoritme-afstemlus voor de bewegingsplanner in het Apollo autonome rijplatform. Krediet:Fan et al.
"Om dit probleem systematisch op te lossen, we hebben een datagestuurd autotuning-framework ontwikkeld op basis van het Apollo-framework voor autonoom rijden, " Fan zei. "Het idee van auto-tuning is om parameters te leren van door mensen aangetoonde rijgegevens. Bijvoorbeeld, uit data willen we graag begrijpen hoe menselijke bestuurders snelheid en rijgemak in evenwicht houden met obstakelafstanden. Maar in meer gecompliceerde scenario's, bijvoorbeeld, een drukke stad, wat kunnen we leren van menselijke chauffeurs?"
Het door Baidu ontwikkelde auto-tuning-framework bevat een nieuw leeralgoritme voor versterking, die kan leren van gegevens en de prestaties ervan in de loop van de tijd kan verbeteren. In vergelijking met de meeste leeralgoritmen voor inverse versterking, het kan effectief worden toegepast op verschillende rijscenario's.
Het raamwerk omvat ook een offline trainingsstrategie, een veilige manier voor onderzoekers om parameters aan te passen voordat een autonoom voertuig op de openbare weg wordt getest. Het verzamelt ook gegevens van deskundige chauffeurs en informatie over het milieu, deze automatisch te labelen, zodat ze kunnen worden geanalyseerd door het leeralgoritme voor versterking.
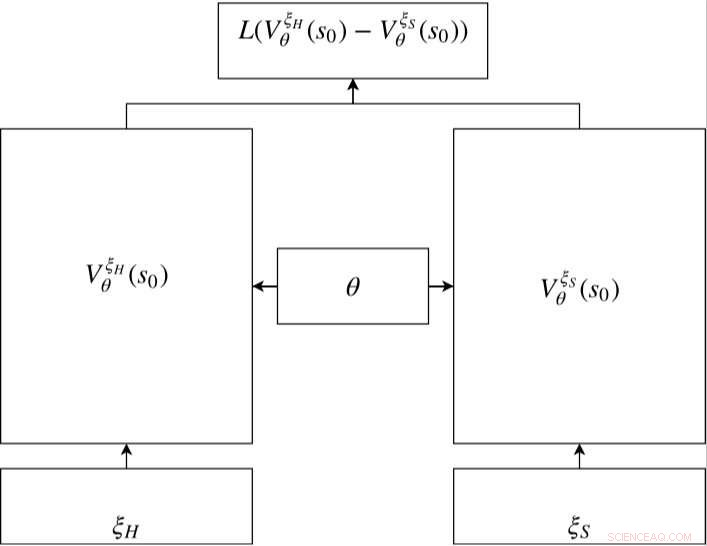
Siamees netwerk in RC-IRL. De waardenetwerken van zowel de menselijke als de gesamplede trajecten delen dezelfde netwerkparameterinstellingen. De verliesfunctie evalueert het verschil tussen de bemonsterde gegevens en het gegenereerde traject via de uitgangen van het waardenetwerk. Krediet:Fan et al.
"Ik denk dat we een veilige pijplijn hebben ontwikkeld om een schaalbaar systeem voor machinaal leren te maken door menselijke demonstratiegegevens te gebruiken, " Fan zei. "De open lus menselijke demogegevens worden verzameld en hebben geen extra etikettering nodig. Omdat het trainingsproces ook offline is, onze methode is geschikt voor autonoom rijdende bewegingsplanning, veiligheid op de openbare weg houden."
De onderzoekers evalueerden een bewegingsplanner die was afgestemd met behulp van hun raamwerk, zowel voor simulaties als voor testen op de openbare weg. In vergelijking met bestaande benaderingen, hun datagestuurde methode was beter in staat om zich aan te passen aan verschillende rijscenario's, constant goed presteren onder verschillende omstandigheden.
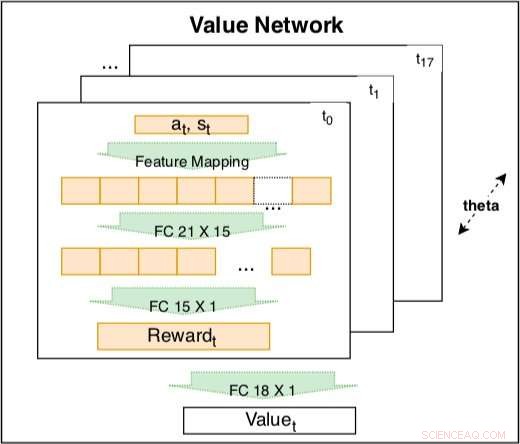
Het waardenetwerk binnen het siamese model wordt gebruikt om rijgedrag vast te leggen op basis van gecodeerde kenmerken. Het netwerk is een trainbare lineaire combinatie van gecodeerde beloningen op verschillende tijdstippen t =t0, ..., t17. Het gewicht van de gecodeerde beloning is een leerbare tijdsvervalfactor. De gecodeerde beloning bevat een invoerlaag met 21 onbewerkte functies en een verborgen laag met 15 knooppunten om mogelijke interacties te dekken. De parameters van de beloning op verschillende tijdstippen delen dezelfde θ om consistentie te behouden. Krediet:Fan et al.
"Ons onderzoek is gebaseerd op het Baidu Apollo Open Source Autonomous Driving-platform, " Fan zei. "We hopen dat steeds meer mensen uit de academische wereld en de industrie via Apollo kunnen bijdragen aan het autonoom rijdende ecosysteem. In de toekomst, we zijn van plan het huidige raamwerk van Baidu Apollo te verbeteren tot een schaalbaar systeem voor machinaal leren dat de scenariodekking van autonoom rijdende auto's systematisch kan verbeteren."
© 2018 Tech Xplore
 Als toekomstige batterijen, hybride supercondensatoren zijn supergeladen
Als toekomstige batterijen, hybride supercondensatoren zijn supergeladen- Diffusion & Osmosis Lesson Activities
- Onderzoekers ontwikkelen nieuwe chemie om smartdrugs slimmer te maken
- 3D-printharsen in tandheelkundige apparaten kunnen giftig zijn voor de reproductieve gezondheid
- De eukaryote celkern lijkt op de lay-out van een superstore
- Grote inheemse spinnen in Wisconsin
- Duizenden vluchten terwijl storm Barry New Orleans bedreigt, kust van Louisiana
- Kunnen virtuele natuur en poeptransplantaties de gezondheidsproblemen van stadsbewoners oplossen?
- NASA ziet tropische depressie Jongdari aan land komen in China
- Hoe helpen bloemen en bijen elkaar?
Hoofdlijnen
- Welke rol speelt het ribosoom in vertaling?
- Wetenschappers maken apparaat voor ultranauwkeurige genoomsequencing van afzonderlijke menselijke cellen
- Gymnospermen: definitie, levenscyclus, typen en voorbeelden
- Plantenziekte bestrijden bij warme temperaturen houdt voedsel op tafel
- Onderzoekers voeren een nieuwe analyse van het tarwemicrobioom uit onder vier managementstrategieën
- In populaties van microben, bio-ingenieurs vinden een balans tussen tegengestelde genomische krachten
- Het verschil tussen genomisch DNA en plasmide-DNA
- Een stap dichter bij gewassen met twee keer de opbrengst
- Linkshandige vis en asymmetrische hersenen
- Door crisis getroffen Nissan-topman treedt af te midden van loononderzoek

- Galaxy Fold eerste blik:we gaan hands-on met Samsungs bijna $ 2, 000 opvouwbare telefoon

- YouTube-kindkijkers kunnen moeite hebben om advertenties in video's van virtuele speeldatums te herkennen

- Gronddoordringende radartechnologie voor zelfrijdende auto's beperkt weersrisico's

- Boston Dynamics geeft Atlas een parkour-repertoire


 Squirrel Life Cycles
Squirrel Life Cycles - Mensen veroorzaakten 84 procent van de bosbranden in de VS, toegenomen brandseizoen gedurende twee decennia
- Onderschatting van geïrrigeerde gewassen leidt tot watertekorten
- Nanomateriaal is ionen te slim af
- De gemiddelde temperatuur berekenen
- Berekening van de tijd voor celverdubbeling
- Jet Airways-geldschieters stappen naar de faillissementsrechtbank
- Kippenplastic en wijnleer – afval een nieuw leven geven
- Elektronica
- Biologie
- Zonsverduistering
- Wiskunde
- French | Italian | Portuguese | Swedish | German | Dutch | Danish | Norway | Spanish |

-
Wetenschap © https://nl.scienceaq.com
